








文章目录
1、NoSQL数据库简介(非关系型数据库)
1.1在web2.0时代出现了大量用户上网,出现了两个压力
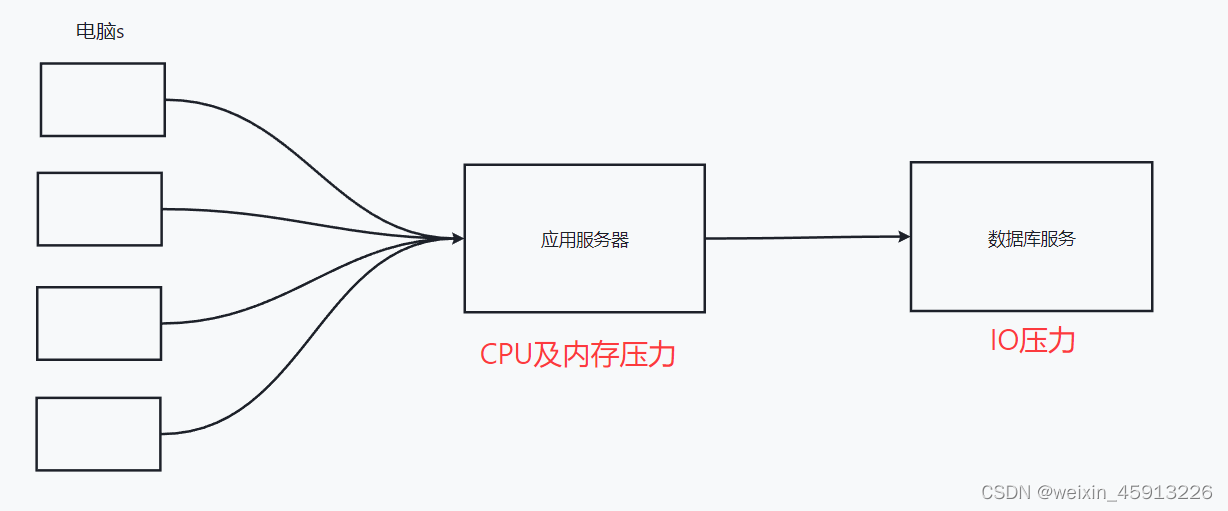
1.1.1解决CPU及内存压力和IO压力:
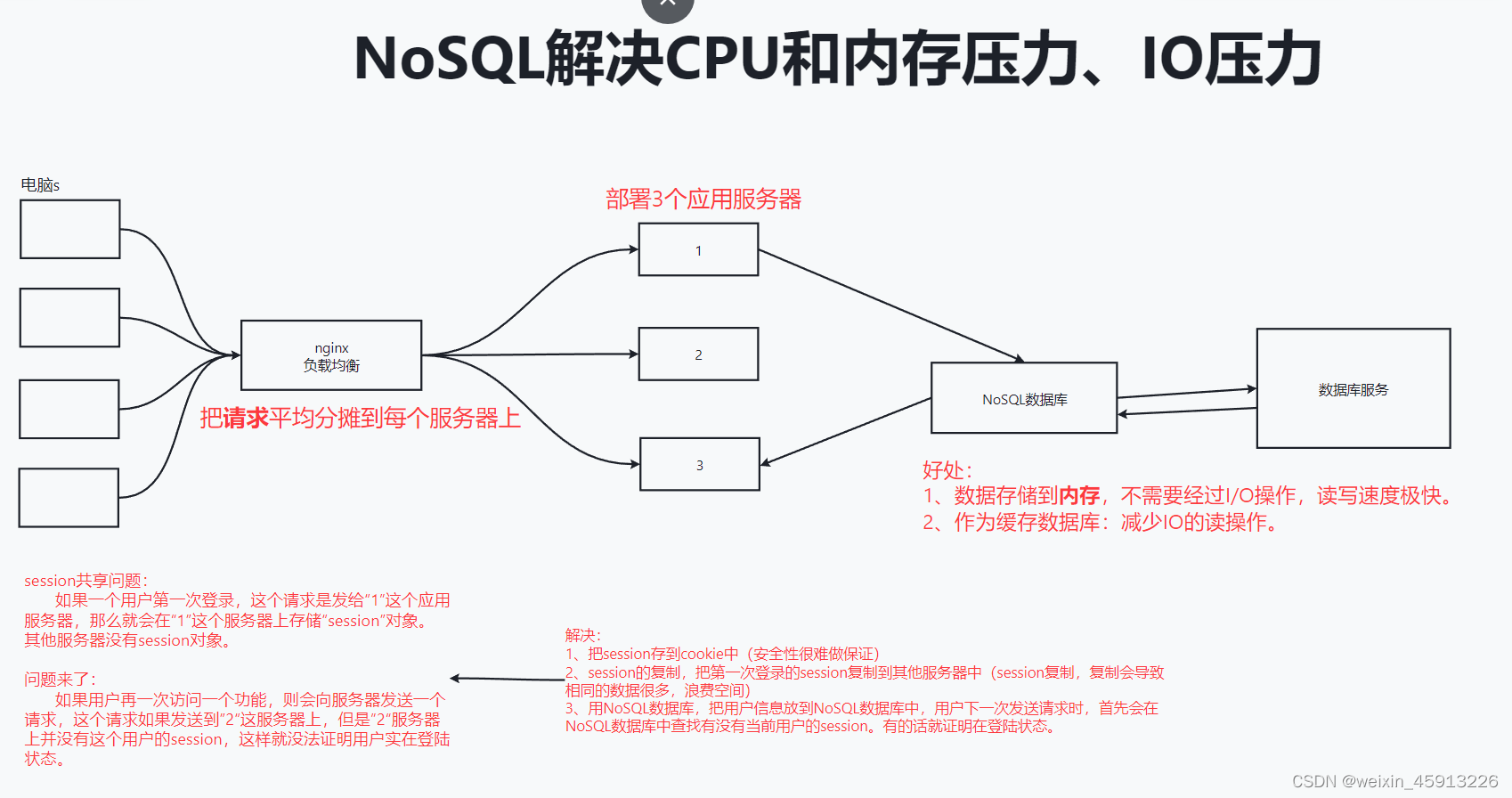
1.2NoSQL简单概述
1.2.1NoSQL数据库概述
- 不支持SQL标准
- 不支持ACID。即事务的四大特性原子性、一致性、隔离性、持久性
- 远超SQL的性能
1.2.2NoSQL使用场景
- 对数据高并发的读写(电商里的秒杀场景)
- 海量数据的读写
- 对数据的高扩展性
1.2.3NoSQL不适用场景
- 需要事务的支持
- 基于SQL的结构化查询存储,处理复杂的关系。
1.2.4有哪些NoSQL数据库
- Memcache(缺点不支持数据的持久化,数据不能存储到硬盘中)
- Redis (支持数据的持久化、支持多种数据结构list\set\hash\zset)
- mongoDB(文档型数据库、存储的数据类型更加的多样化)
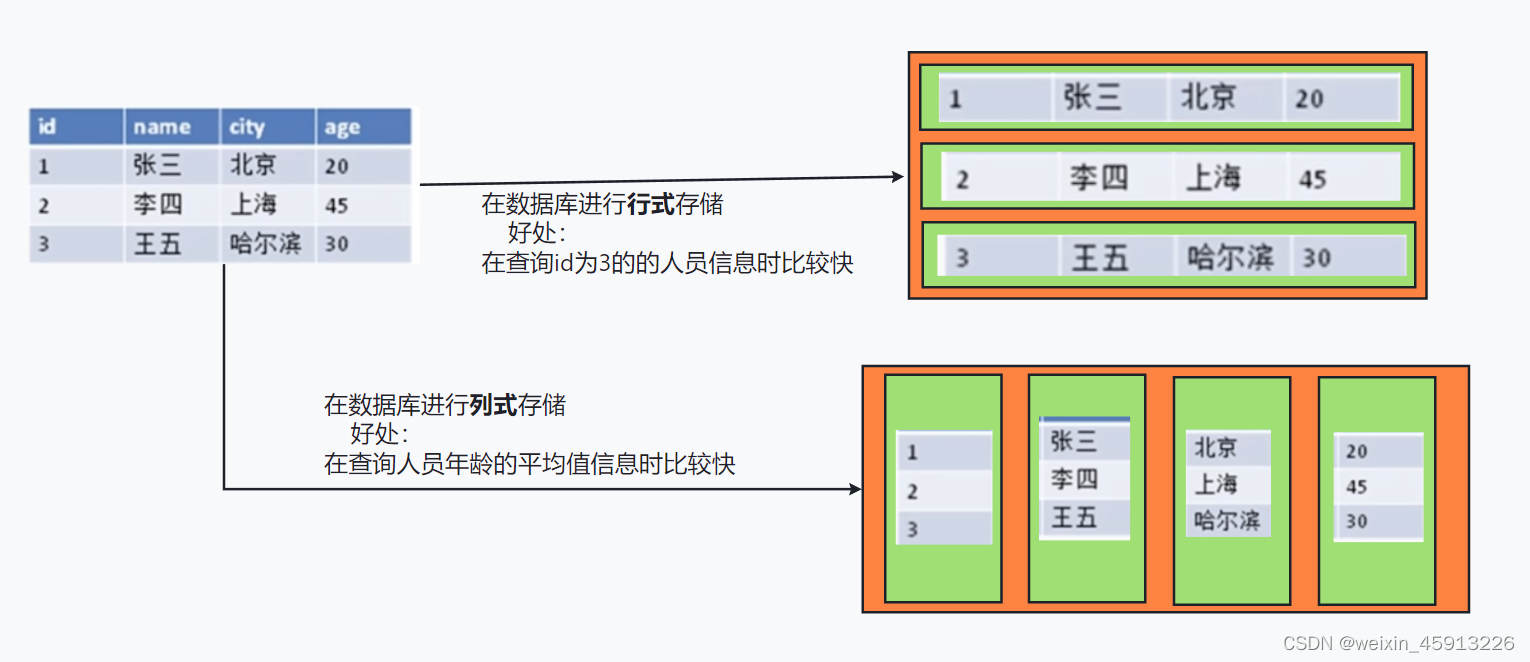
1.3行列式存储数据库(大数据时代)
2、Redis安装
2.1使用宝塔傻瓜式安装
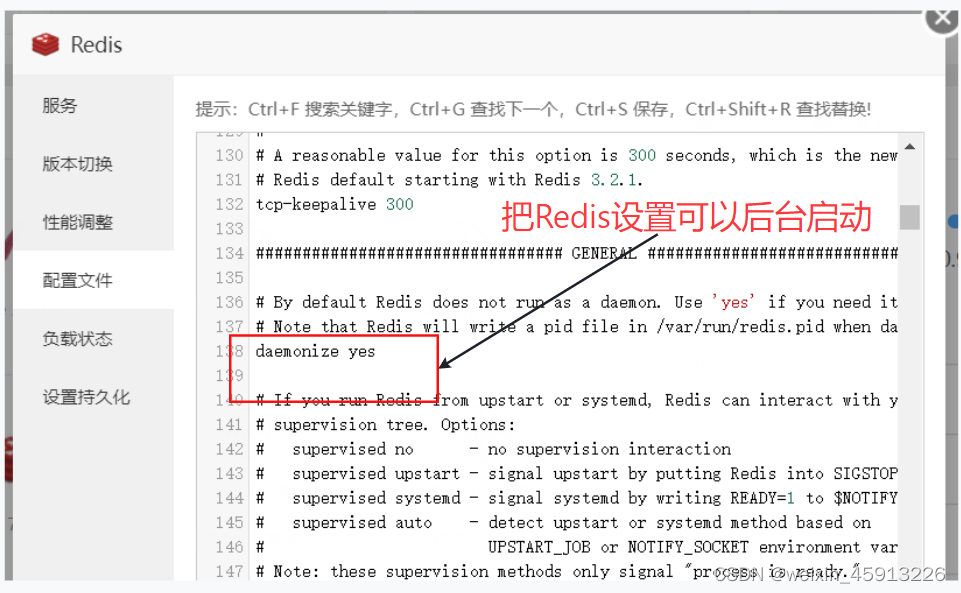
2.2Redis启动
- ps -ef | grep redis //查看redis启动后的进程
- reids-server redis.conf //启动redis服务
- redis-cli //设置可以用客户端终端访问
- auth 123456 //输入密码
- 127.0.0.1:6379> ping //测试验证一下
2.3Redis关闭
- 第一:用宝塔关闭(简单)
- 第二:单实例关闭:redis-cli shutdown
- 第三:可以进入终端后关闭

- 第四:知道redis进程号后用kill命令杀掉redis进程
3、Redis相关知识介绍
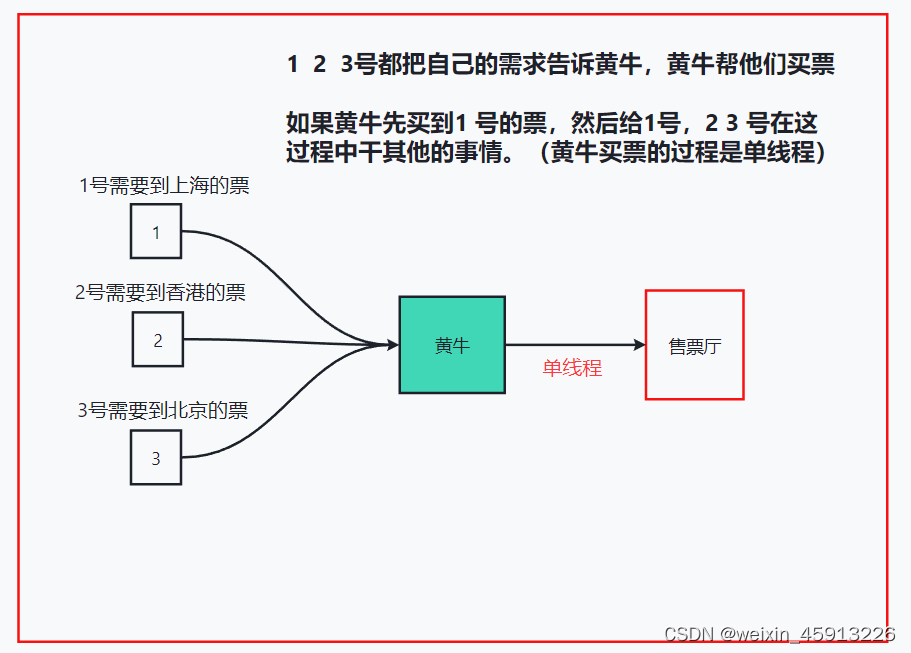
3.1Redis是单线程+多路IO复用技术(可以实现多线程的效果)
- 如下图描述:单线程+多路IO复用
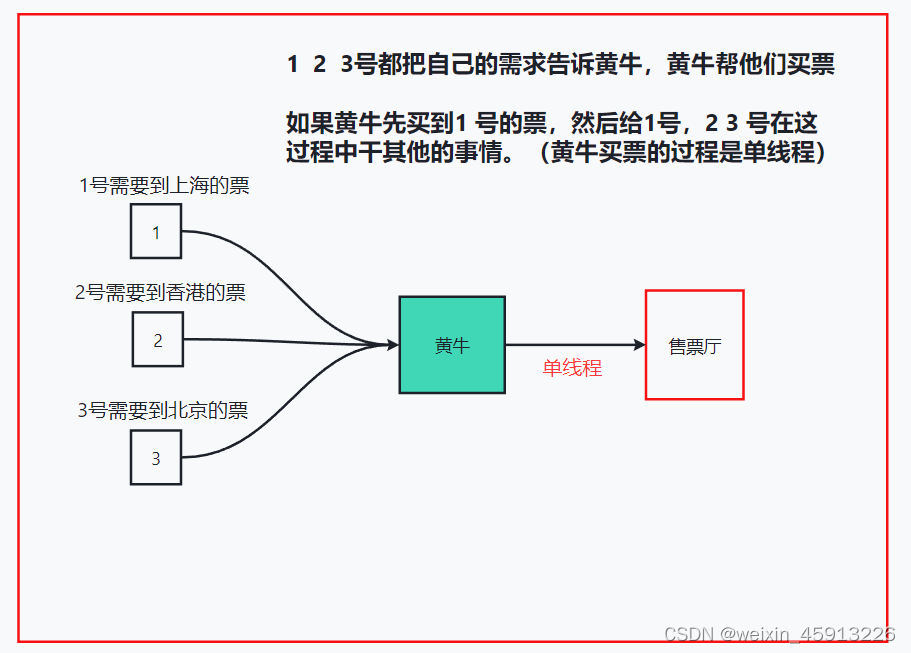
- Redis读取是原子操作,因为在黄牛和售票厅之间是单线程的,不像多线程里面需要加锁
3.2Redis中常用5大基本数据类型
(1)Redis键(key)
- keys * :查看当前库中的所有key
- set :设置key-value
- exists key1 :判断key1是否存在——返回1:存在,2:不存在
- type key2 :查看key2所对应值的类型
- del key2 :删除key2
- unlink key2 :删除key2(它会先返回消息说已经删掉了key2,其实还没有删除,真正的删除是在以后慢慢删除,异步删除)
- expire key1 10 :设置过期时间,为key1设置10秒后过期
- ttl key1:查看key1是否已经过期——返回: -1:永不过期,-2:已经过期
- select :切换库(Redis一共有16个库,默认用0号库)
- dbsize :查看当前数据库的key的数量
- flushdb:清空当前库
- flushall :通杀全部库
(2)字符串String
- String类型是二进制安全的。意味着Redis的String可任意包含任何数据。比如jpg图片,或者序列化对象,通俗点,只要你的内容能用字符串表示,我们都能存到Redis去。
- String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以达到512MB。
- 关于String的命令:
- set:添加key—value (设置相同key的数据会把前面的覆盖掉)
- get:取值
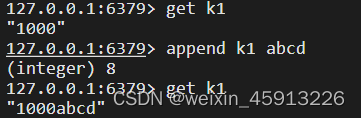
- append:将指定的value追加到原来值的末尾
- strlen:获取指定值的长度;
- setnx:当库中没有对应的key时,设置key-value才能成功。(以防覆盖原来的);
- incr key:将key中存储的数值加1,如果为空,则新增值1;
- decr key:将key中存储的数值减1;
- incrby/decrby key 步长:给数值加减指定的数。
- mset :同时设置多个key-value(不保证原子性)
- mget :同时获取多个key分别对应的值(不保证原子性)
- msetnx:同时设置多个key-value,但是key不能和之前有重复,如果有一个重复则这次设置的key-value都失败;(体现原子性)
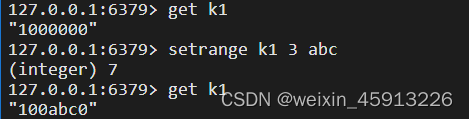
- getrange key 起始位置 结束位置:获取key对应值的
- setrange key 起始位置 value : 用value覆盖掉从起始位置开始的值
- setex key 过期时间 value 设置key-value时设置过期时间;
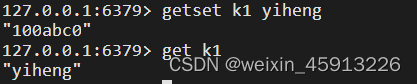
- getset key1 value:设置新的key1-value;同时输出原来的key1对应的value
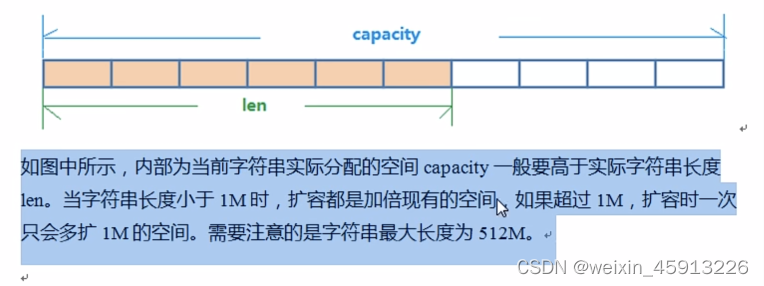
- String的数据结构:
- String的内部结构为简单的动态字符串(Simple Dynamic String),是可以修改的字符串(Java的字符串是不可变的),其内部结构类似于Java中的ArrayList,可以伸缩。
(3)列表(List)
- List是简单的字符串列表,里面存储的都是一个一个的字符串;
- List底层实现为一个循环的双向链表,对两端的操作时它性能很高,当需要通过下标操作中间件时性能较差。
- 常用命令:
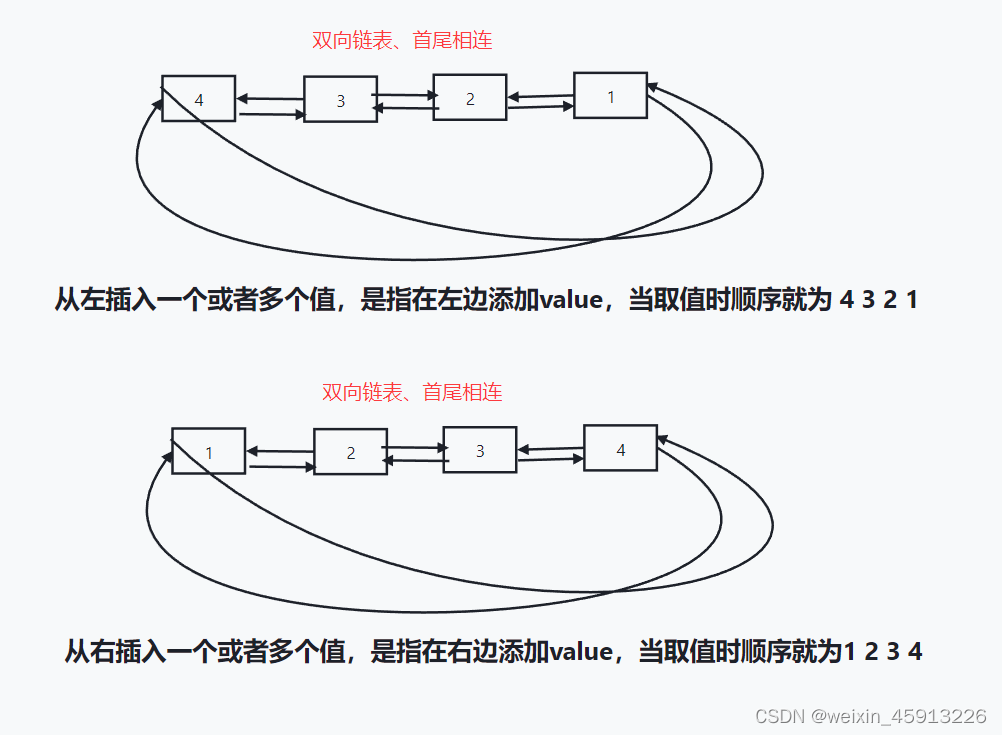
- lpush/rpush key value1 value2 value3:从左/右边边放入多个值;
- lrange key1 start stop: 按照索引下标获取元素(从左到右)
如:lrange key1 0 -1: 从左到右取出所有元素,0代表第一个位置,因为是链表List底层是双向链表,所以-1代表左后一个位置。- lpop/rpop key count: 从key对应的链表的左边或者从右边取出count个值; 每取出一个值该链表少一个值;
- rpoplpush key1 key2 :把key1最右边的一个value放到key2最左边去。
- lindex key index :按照索引下标获得元素;
- linsert key before value newvalue: 在旧的值的后面插入一个新的值;
- lrem key N value11:从左边到右边删除N个一样的value;
- lset key index value :将key对应列表中下标为index的值替换为value

- List列表数据结构:
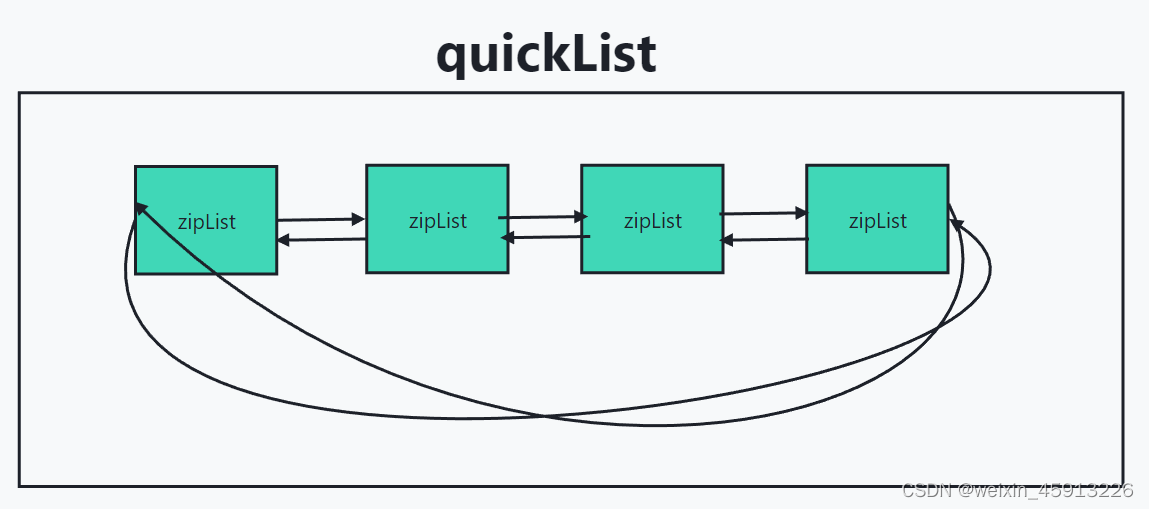
- List会在数据量较少时寻找一块连续的空间,结构为zipList.也就是压缩列表。只有数据量比较多时才会改成多个zipList首尾相连的quickList(链表实现)
- 使用普通链表,如果存放的只是int型数据,还需要在两边加上指针(prev,next),极大浪费空间。
(4)集合(Set)
- Redis Set和List的功能不同在于List可以有重复项,而Set没有重复项。Set可以自动排重
- Redis Set集合内提供了查看一个成员是否在Set中的接口,而List当中就没有这样的就功能。
- Redis Set是String类型的无序集合,底层就是一个值为null的hash表,所以添加删除查找复杂度都是O(1).
- 常用命令:


- Redis Set数据结构:
- Set数据结构是dict字典,字典就是哈希表实现;
- Java中HashSet就用HashMap实现,只不过所有的value指向同一个对象。
- Redis的set结构也是一样,它内部也使用hash结构,所有的value都指向同一个内部的值。
(5)哈希(hash)
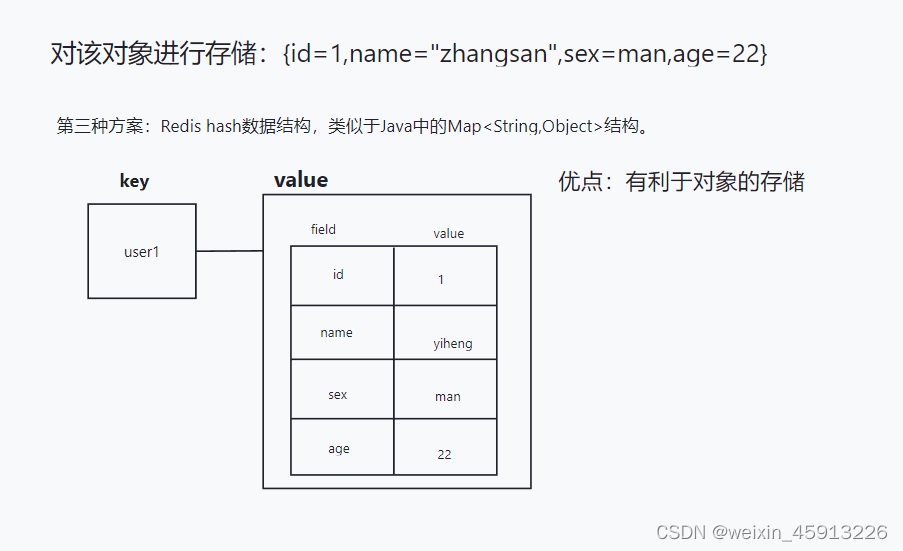
- Redis hash的由来:Redis hash是一张String类型的field和value的映射表,hash特别适合存储对象,类似于Java中的Map<String,Object>.


- hash常用命令:

- hash数据结构:
hash类型对应的数据类型是2种:zipList(压缩列表),hashTable(哈希表)。当field-value长度较短并且个数较少时,使用zipList,否则使用hashTable。
(6)有序集合(ZSet)
- 简介:Redis有序集合Zset与普通集合Set很类似,没有一个重复元素的字符串集合。
- 不同之处在于Zset的每个成员有关联一个评分,该评分(score),集合中的成员按照自己关联的评分高低排先后顺序。集合成员是唯一的,但是成员关联的评分可以相同。
- Zset的元素是有序的,而且没有重复项。
- 常用命令:


- 案例:利用Zset实现一个文章访问量排行榜。
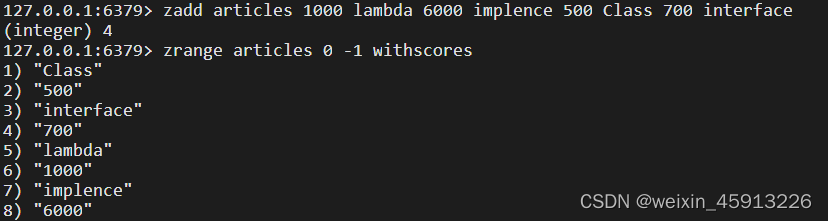
- Zset数据结构:
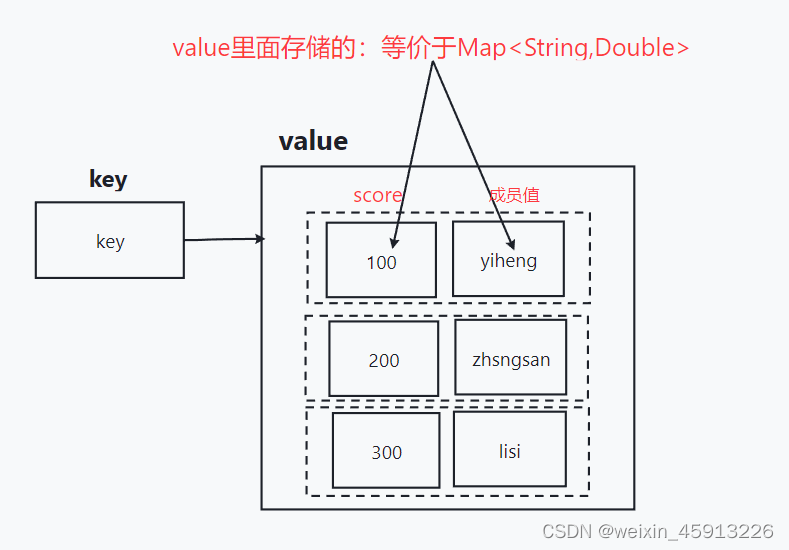
- Zset数据结构很特殊,一方面,value内部等价于Java中的Map<String,Double>
- 另一方面,类似于TreeSet,内部的元素会按照权重score来排名,还可以用过score范围来获取范围内的元素。
- Zset底层使用了两个数据结构。
(1)hash,hash的作用是的作用是关联元素的值与score,保证元素的唯一性,可任通过value找到相应的score值。
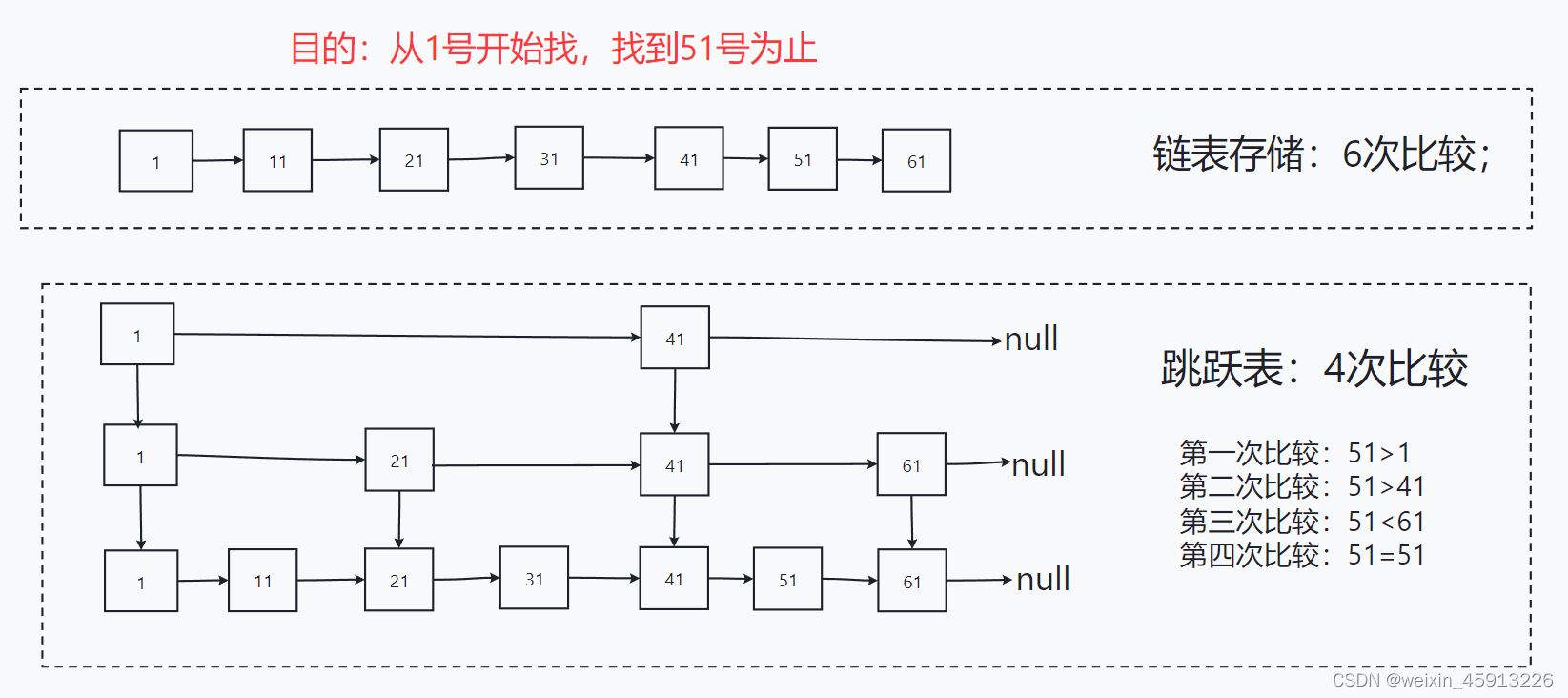
(2)跳跃表(跳表),跳跃表的目的:在于给元素value排序,根据score来查找元素。
例如:

4、Redis配置文件讲解
4.1
5、Redis的发布和订阅
5.1什么时发布和订阅?
- Redis发布和订阅是一种通信模式:发送者发送消息,订阅者接收消息
- Redis客户端可以订阅任意数量的频道。
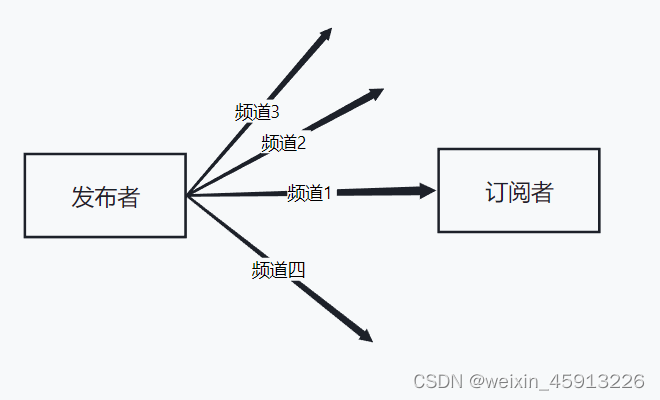
5.2Redis的发布与订阅。
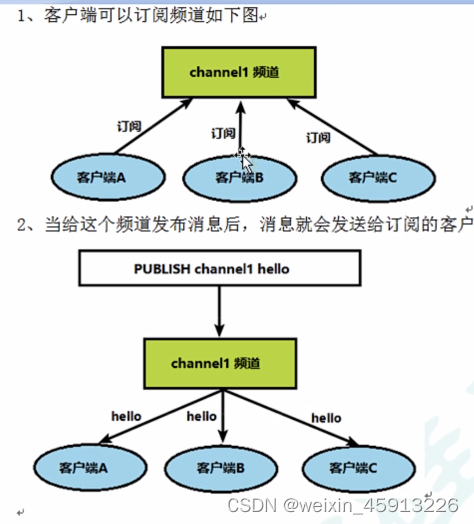
5.3发布与订阅的命令实现。
- 打开一台客户端订阅频道1、2;
- SUBSCRIBE channel1 chanel2————订阅频道1 和频道2
- 打开另一台客户端分别向频道1和频道2发送“nihao”;
- publish channel1 nihao ————向频道1发送“nihao”
- publish channel2 nihao————向频道2发送“nihao”
6. Redis新数据类型
6.1Bitmaps:新数据类型
(1)Redis提供了Bitmaps这个数据类型可以实现对位操作:
- Bitmaps本身不是数据类型,实际上它就是字符串(相当于字符类型和字符串的差别)。
- Bitmaps可以被想象成一个以bit(位)为单位的数组(这个数组中只能存“0”或者“1”,如果存默认数组里面全是0),数组的下标叫做偏移量(offset)
- 基本命令:
- setbit key offset value :往一个key对应的数组(以位为单位的数组)中的offset(偏移量)的这个位置存一个值,value值只能为“0”或“1”;
- getbit key offset:取出该offset(偏移量)对应的值
- bitcount key :统计key对应的Bitmaps中为“1”的个数。
- bitcount key start end bit :以bit为单位在start和end中有多少个“1”;
- bitcount key start end byte :以byte为单位在start和end中有多少个“1”;
- bitop and(or/not/xor) destkey key[key…],对多个Bitmaps求,and(交集)、or(并集)、not(非)、xor(异或)操作,并将结果保存在目标Bitmaps(deskey)中。
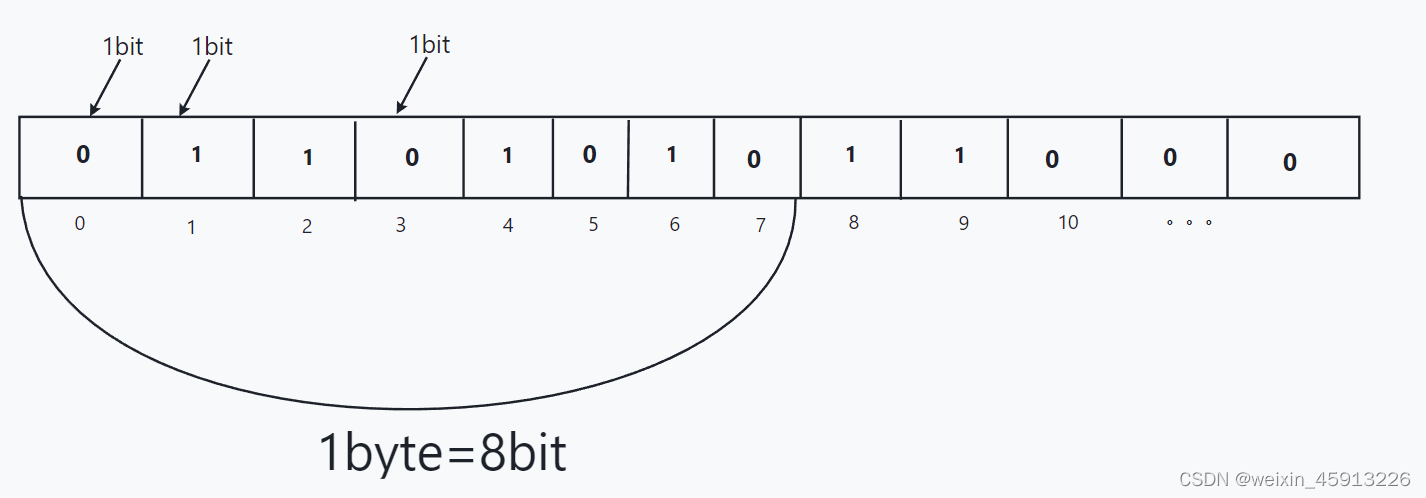
- 举例1:一个班的有10位同学,学号分别为1 2 3 4 5 6 7 8 9 10,如果他们看了青年大学习就用”1”表示,如果没看就用“0”表示;把他们的学号作为offset(偏移量),value就是“0”或者“1”;

- 举例2:统计一个有1亿用户数量的网站的某一天的活跃用户数量,若1亿用户里有5000万用户活跃。
方案一:用集合Set存储活跃用户的id,每个人的id占64位,那么存储id总共花费:64bit x 5000万=32亿bit
方案二:用Bitmaps记录每一位用户是否活跃,那么花费:1bit x 1亿=1亿bit
结论:很明显当活跃用户多时,方案二很好;但是活跃用户少时,方案一好;
- Bitmaps用来表示一个团体的人做一件事,哪些人做了,哪些人没做很合适(或者像统计一个网站的活跃用户有哪些)。比如一个班看青年大学习,有一部分同学看了,一部分同学还没看,怎么记录看了的同学?就把看了的同学的学号作为偏移量或者数组下标,以1作为value存到Bitmaps中。
6.2HyperLogLog:新数据类型
- 主要用来解决基数运算。什么是基数?就是像一个集合中去了重复项之后的总的个数。
- 如:统计一个网站今天有多少个ip地址访问过。
解决像这样的问题有很多种解决方案:
- 方案一:如果数据存储在Mysql中,使用distinct count统计不重复的值;
- 方案二:使用Redis中的hash、set、bitmaps、这些结构都能处理
- 为什么不用这些结构:因为以上数据结构如果对于大的数据集,将要浪费大量空间,不切实际。
- 方案三:使用hyperLogLog来统计
- HyperLogLog是用来统计基数的算法。
- 优点:HyperLogLog计算基数所需的空间是固定大小的,并且很小。
- HyperLogLog算法,不像Zset、hash这些数据结构内部的算法,后者在统计量很大的数据集时占用空间也会很大,不划算。
- HyperLogLog只会根据输入的元素计算出基数,而不会像Zset、hash存储元素。
- 基本命令:
- pfadd key value[values]:把value添加,并不是存储起来,而是用来计算基数
- pfcount key :计算基数;
6.3Geospatial
Geo:Geographic:地理学的
spatial:空间的
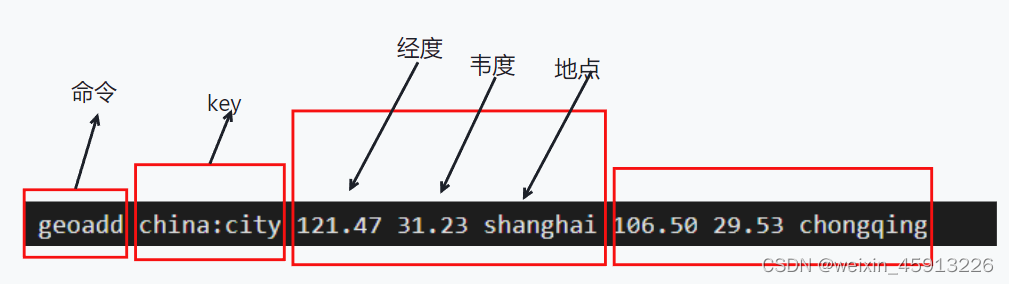
- Redis3.2增加了地理信息类型的支持,该类型的元素就是二维坐标。经度和纬度。(经度范围:-180_180;维度范围:-85_85)
- 基本命令:
- 添加多个个地点
- geopos key shanghai:取一个地点的经纬度:
- geodist key member1 member2 [m米/km千米/ft英尺/mi英里]:得到两个地点之间的直线距离
- georadius key 经度 维度 半径 [m/km/ft/mi] 以一个经纬度为中心,得到周围半径以内的距离的地点有哪些。

7、 jedis连接Redis
8、Redis_jedis实例
8.1做一个手机验证码功能:
简介:
- 生成随机6位数验证码,把这个验证码存在Redis中,然后再把这个数发送个用户;
- 生成的验证码2分钟失效,并且一天内只能生成3次验证码。
- 用户输入收到的验证码,并且输入
- 把用户输入的验证码与Redis中调出的验证码做等价判断。
package com.yiheng.jedis;
import redis.clients.jedis.Jedis;
import java.util.Random;
import java.util.Scanner;
//案例需求:
//输入手机号之后,我们点击一下,能够获取随机6位的验证码。
public class PhoneCode {
public static void main(String[] args) {
//1、用户点击获取验证码后:向Redis保存生成的验证码,并且向用户发送该验证码;
int i = verifyCode("18728089510");
if(i==1){//达到了获取3次的界限
System.out.println("程序结束!");
}else {
//2、用户填写验证码,该验证码再两分钟以内有效
Scanner scanner = new Scanner(System.in);
System.out.println("请输入验证码!!");
String code = scanner.next();
System.out.println(code);
//3、调用验证码校验,
verify("18728089510",code);
}
}
//三、验证码校验:
public static void verify(String phone,String code){
//1.连接redis
Jedis jedis = new Jedis("8.142.89.219", 6379);
jedis.auth("123456");
//2.设置改手机号获取的验证码在Redis中的key
String Verify_code="Code"+phone+":code";
//3.从redis中取该用户已获取到的验证码
String s = jedis.get(Verify_code);
jedis.close();
//4.判断用户输入的验证码:code与从Redis中取出的验证码是否一致;
if (s.equals(code)){
System.out.println("验证成功");
}else {
System.out.println("验证失败");
}
}
//二、让每个手机每天只能生成3次验证码,把生成的验证码保存到redis中,并且返回给用户该验证码
public static int verifyCode(String phone){
//1.连接redis
Jedis jedis = new Jedis("8.142.89.219", 6379);
jedis.auth("123456");
//2.设置改手机号获取的验证码在Redis中的key
String Verify_code="Code"+phone+":code";
//3.设置该手机号获取验证码次数在Redis中的key
String Verify_count="Count"+phone+":count";
//4.取出redis中保存的向该手机发送验证码发送的次数;
String count = jedis.get(Verify_count);
//5.判断获取次数
if(count==null){//第一次发送
jedis.setex(Verify_count,24*60*60,"1");//设置过期时间
}else if(Integer.valueOf(count)<=2){
jedis.incr(Verify_count);
}else if(Integer.valueOf(count)>2){
//回去次数大于等于3次,直接回应给用户,并且关闭资源链接
System.out.println("今日获取已经达到3次,24小时内无法再此发送");
jedis.close();
return 1;
}
//6.把随机生成的验证码保存到Redis中;
String s = String.valueOf(getCode());
jedis.setex(Verify_code,2*60,s);
//7.从redis中获取,24小时内发送给用户验证码的 总次数
String a =jedis.get(Verify_count);
//8.把生成的验证码发送到用户的手机;
System.out.println("今天第"+a+"次获取验证码;"+"验证码为:"+s+",两分钟内有效。");
jedis.close();
return 0;
}
//一、随机生成6位验证码
public static StringBuilder getCode(){
Random random = new Random();
StringBuilder code = new StringBuilder("");
for (int i = 0; i < 6; i++) {
int c = random.nextInt(10);
code=code.append(c);
}
return code;
}
}
8.2Springboot整合Redis
- pom.xml
<dependencies>
<!--Springboot整合redis包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
- application.yml
spring:
redis:
host: 8.142.89.219
port: 6379
database: 0 #数据库索引默认0;
connect-timeout: 1800000 #连接超时时间
lettuce:
pool:
max-active: 20 #最大连接数
max-idle: 5 #连接池最大空闲连接
max-wait: -1 #最大阻塞等待时间
min-idle: 0 #连接池最小空闲连接
password: 123456 #Redis连接密码
- RedisConfig.java
package com.yiheng.redis_config;
@EnableCaching //配置缓存
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600)) //设置数据过期时间600秒
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
- Controller.java
@RestController
public class RedisController {
@Autowired
RedisTemplate redisTemplate;
@RequestMapping("/RedisTest1")
public String test1(){
//设置key-String
redisTemplate.opsForValue().set("k1","yiheng");
//取key对应的String
return (String)redisTemplate.opsForValue().get("k1");
}
}
9、Redis_事务_锁机制_秒杀
9.1事务:
(1)事务定义
- Redis事务是一个单独的隔离操作:事务中所有的命令都会被序列化、按顺序的执行。在事务的执行过程中不会被客户端发送来的其他命令打断。
(2)Multi、Exec、discard 基本命令
-
Multi:可以用来开启事务,开启事务后,我们可以输入命令,命令会进入队列准备执行。
-
Exec:执行操作,命令会依次执行

-
discard:在组队(进入队列的过程)中,可以使用discard命令放弃组队。
(3)事务错误处理
- 在命令入对阶段,如果需要被执行的命令出现了被报告出来的任务,则整个队列中所有命令都会被取消。
- 在命令执行阶段,如果队列中有命令发生错误,则不会影响其他命令执行。
- 结论:这种就很像Java中的编译时错误,和运行时错误。编译错误整个程序都没法运行,运行时错误则不会影响其他命令的执行。
9.2事务冲突:
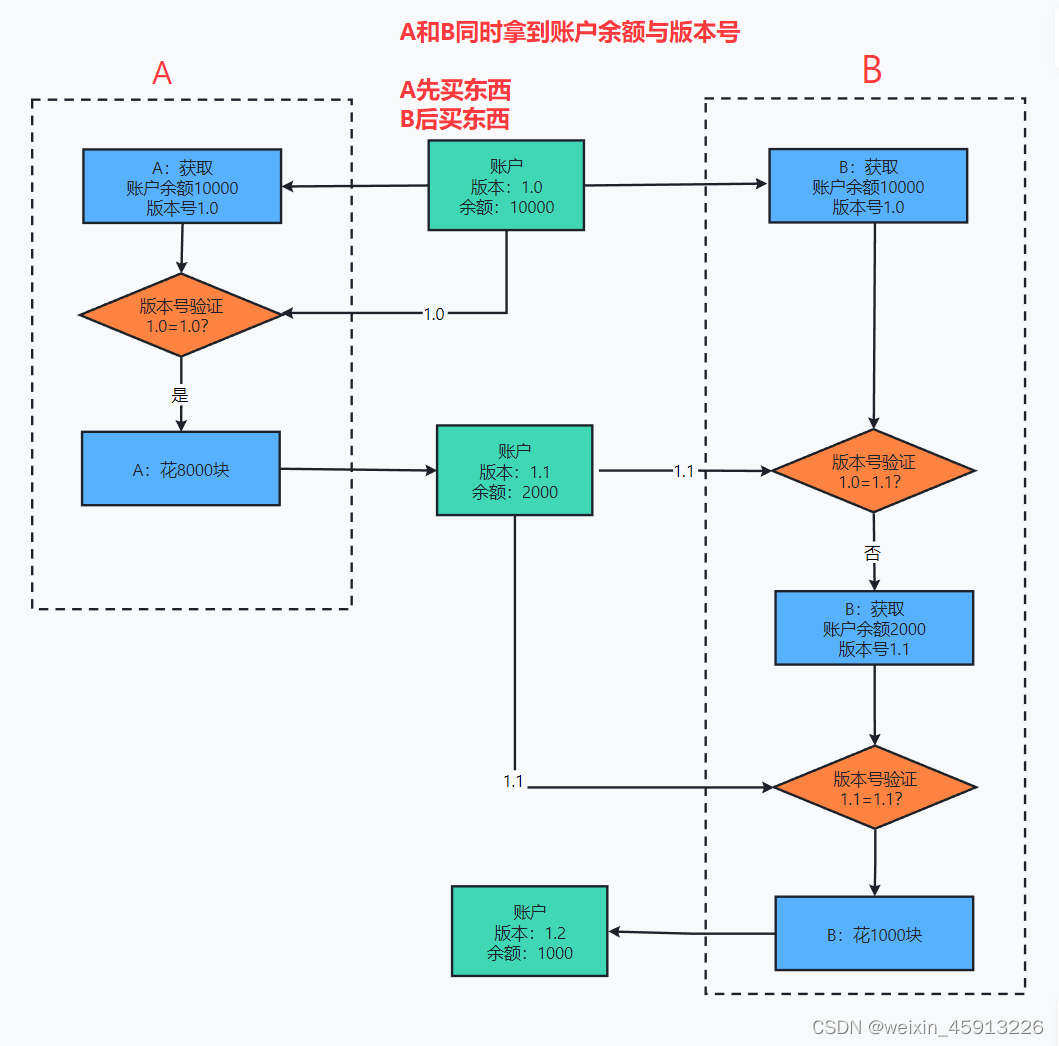
(1)什么是事务冲突?
- 举个例子,1万块钱帐户,3个人同时得知账户还有一万,第一个人买8000块钱东西,第二个人买5000块钱东西,第3个人买2000块钱的东西,那么账户余额:1万-1万5=-5000。
- 为了解决上述问题,悲观锁和乐观锁诞生了
(2)悲观锁
- 悲观锁,顾名思义就是很悲观,每次操作数据时都怕别人修改这个数据,所以你每次操作这个数据你都上锁,当你持有锁时,别人进入阻塞,当你操作完时,你就释放锁,下一个人再持有这个锁。传统关系型数据库中的行锁,表锁,读写锁,写锁,等都用这种机制。就像Java里面的同步机制,效率低下。
(3)乐观锁
- 乐观锁,顾名思义就是很乐观,认为当前我修改数据时别人不会修改该数据,所以不会上锁,也是因为没有上锁,所以所有人都可以同时拿到该数据,但是当我拿到数据将要修改该数据时,我会判断一下,我拿到的数据是否是最新的数据,这个可以利用版本号机制实现。乐观锁可以用在多读的应用类型(读:从数据库中拿数据,写:把数据保存在数据库中),这样可以提高吞吐量。Redis就是利用check-and-set机制实现事务。
- 乐观锁图解(版本号是实现):
(4)WATCH key[key…] ——Redis的基本命令
- 作用:再执行Multi之前先执行 watch key1[key…],可以用来监视一个或者多个key,如果,在输入Exec命令之前,如果你操作的key发生改变过(被其他命令改变过),则事务执行会被打断。
(5)unwatch
- 作用:在使用watch key1[key…]后,可使用unwatch取消对key的监视。
9.3Redis中事务的三个特性
- 单独的隔离操作:事务中的所有操作都会被序列化,按顺序的执行,在执行事务中,不会被客户端发送来其他的命令请求打断。
- 没有个隔离级别的概念,使用multi命令开启事务后,然后添加命令,如果最后没有提交该事务,则事务中的命令都不会执行。
- 不保证原子性:如果过再事务执行过程中,发现有执行失败的命令,则该事务其他命令继续执行。不像Mysql数据库中原子性,一个败全败。
9.4商品秒杀案例
(1)三大问题:
- 秒杀时超卖问题:在秒杀结束后,商品库存为负数
- 连接Redis超时问题:再高并发场景下,jedis连接Redis超时
- 库存遗留问题:用Redis的乐观锁机制解决了第1问后,出现了库存有遗留的情况。争抢问题
(2)高并发情况下的超卖问题的解决
- 使用Redis提供的乐观锁机制。
- 具体过程为:1、watch命令监视库存的key,2、使用mutli开启事务,把库存-1和添加用户id的两个命令添加到事务队列中。3、Exec命令来执行事务。
- 超卖问题解决!
(3)解决高并场景下连接Redis超时问题
- 用连接池解决!
(4)解决用Redis的乐观锁带来的库存遗留问题(争抢问题)
- 原因:在高并发场景下,如果有500个商品,所以人都看到了500个商品,那么所有人中一瞬间里只有一个人能抢到1件商品,这个人抢了一件衣服后(抢了一件衣服以后,库存因为乐观锁,导致库存的版本号改变了),那么其他所有人在这一瞬间都秒杀失败了,这些人的发的请求都失败了。只有点击发送下一次请求,下一次请求和这一次一样,其中只有一个人成功,其他人都失败。所以乐观锁会导致库存遗留问题。
- 解决方法:使用LUA:洛脚本语言。我们把在Redis执行的步骤写为一个脚本,然后一次提交给Redis执行,减少反复连接Redis的次数。

(5)代码展示
(5.1)模拟高并发,调用脚本。
public class TestSecondKill implements Runnable {
public static void main(String[] args) {
TestSecondKill testSecondKill = new TestSecondKill();
for (int i = 0; i < 200; i++) {//生成200个线程,模拟高并发。
new Thread(testSecondKill).start();
}
}
@Override
public void run() {
//随机生成用户id
String userid=String.valueOf(new Random().nextInt(5000));
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// boolean result = secKill(userid,"0101");
try {
SecKill_redisByScript.doSecKill(userid,"0101");
} catch (IOException e) {
e.printStackTrace();
}
}
}
(5.2)LUA脚本的编写:
public class SecKill_redisByScript {
private static final org.slf4j.Logger logger =LoggerFactory.getLogger(SecKill_redisByScript.class) ;
//主方法用来测试LUA脚本对不对
public static void main(String[] args) {
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
System.out.println(jedis.ping());
Set<HostAndPort> set=new HashSet<HostAndPort>();
// doSecKill("201","sk:0101");
}
//LUA:洛脚本语言:我们把在Redis执行的步骤写为一个脚本,然后一次提交给Redis执行,减少反复连接Redis的次数。提升性能。
static String secKillScript ="local userid=KEYS[1];\r\n" +
"local prodid=KEYS[2];\r\n" +
"local qtkey='sk:'..prodid..\":qt\";\r\n" +
"local usersKey='sk:'..prodid..\":usr\";\r\n" +
"local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" +
"if tonumber(userExists)==1 then \r\n" +
" return 2;\r\n" +
"end\r\n" +
"local num= redis.call(\"get\" ,qtkey);\r\n" +
"if tonumber(num)<=0 then \r\n" +
" return 0;\r\n" +
"else \r\n" +
" redis.call(\"decr\",qtkey);\r\n" +
" redis.call(\"sadd\",usersKey,userid);\r\n" +
"end\r\n" +
"return 1" ;
static String secKillScript2 =
"local userExists=redis.call(\"sismember\",\"{sk}:0101:usr\",userid);\r\n" +
" return 1";
public static boolean doSecKill(String uid,String prodid) throws IOException {
JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis=jedispool.getResource();
//String sha1= .secKillScript;
String sha1= jedis.scriptLoad(secKillScript);//加载脚本
Object result= jedis.evalsha(sha1, 2, uid,prodid);
String reString=String.valueOf(result);
if ("0".equals( reString ) ) {
System.err.println("已抢空!!");
}else if("1".equals( reString ) ) {
System.out.println("抢购成功!!!!");
}else if("2".equals( reString ) ) {
System.err.println("该用户已抢过!!");
}else{
System.err.println("抢购异常!!");
}
jedis.close();
return true;
}
}
(5.3)Redis的连接池编写
package com.yiheng.controller;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* Jedis连接池工具类,解决并发问题下的连接偶尔出现的Redis超时问题。
*/
public class JedisPoolUtil {
private static volatile JedisPool jedisPool=null;
private JedisPoolUtil(){
}
public static JedisPool getJedisPoolInstance(){
if(null==jedisPool){
synchronized (JedisPoolUtil.class){
if(null==jedisPool){
JedisPoolConfig poolConfig = new JedisPoolConfig();
//MaxTotal:控制一个pool可分配多少个jedis实例,通过pool.getResource()来获取;如果赋值为-1,则表示不限制;如果pool已经分配了MaxTotal个jedis实例,则此时pool的状态为exhausted。
//maxIdle:控制一个pool最多有多少个状态为idle(空闲)的jedis实例;
//MaxWaitMillis:表示当borrow(借)一个jedis实例时,最大的等待毫秒数,如果超过等待时间,则直接抛JedisConnectionException;
poolConfig.setMaxTotal(200);//最大连接数
poolConfig.setMaxIdle(32);
poolConfig.setMaxWaitMillis(100*1000);//等待时间
poolConfig.setBlockWhenExhausted(true);//连接耗尽是否进行等待
poolConfig.setTestOnBorrow(true);//从连接池获取连接,先测试一下连接是否是连通状态。
jedisPool = new JedisPool(poolConfig, "8.142.89.219", 6379, 60000, "123456");//60000超时时间,超过这个时间就不能提供服务了。
}
}
}
return jedisPool;
}
//释放Jedis资源
public static void release(JedisPool jedisPool, Jedis jedis){
if(null!=jedis){
jedisPool.returnResource(jedis);
}
}
}
10、Redis持久化方式—RDB(Redis DataBase,默认开启)
10.1 RDB是什么?
- 就是每隔指定的时间,就把Redis中的那一个快照的数据保存在磁盘中。
10.2 备份是如何执行的?如何持久化的

-
fork出的子进程会利用 写时复制 进行持久化
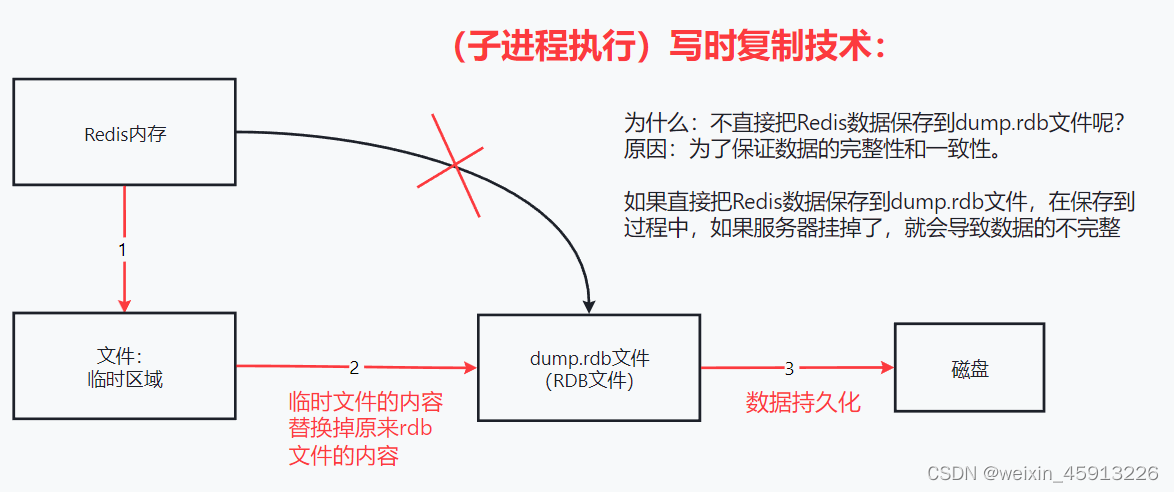
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
10.3 配置文件中关于持久化的配置的解读






10.4 Redis被关闭之后的数据恢复
是根据保存在磁盘上面的dump.rdb文件,来恢复关闭Redis关之前的状态。
10.5 关于RDB的总结:
(1)
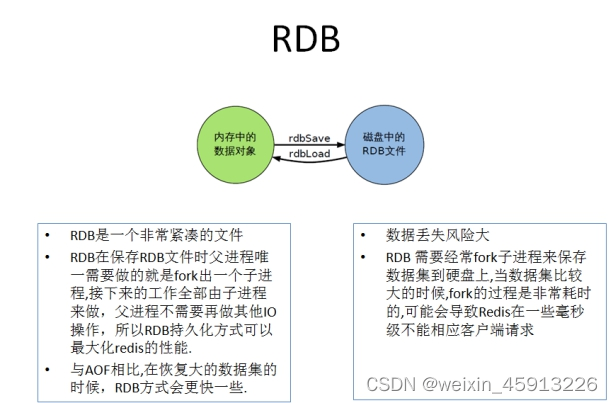
(2)为什么RDB最后一次持久化可能丢失数据?
如果在最后一次进行持久化操作中,服务器挂掉了,那么Redis就会终止。那么导致最后一次持久化时的数据丢失。
11、Redis持久化方式—AOF(Append Only File,默认不开启)
11.1 AOF是什么?有什么内容?
(1)是什么?

(2)内容:
- 一些写操作的命令
- Redis中保存的数据
11.2 当RDB和AOF同时开启,那么Redis听谁的?
AOF的,AOF>RDB优先级。再关闭Redis,再重启Redis,恢复Redis关闭前的状态中的key会根据AOF文件来恢复,而不是根据RDB文件恢复。
11.3 执行流程
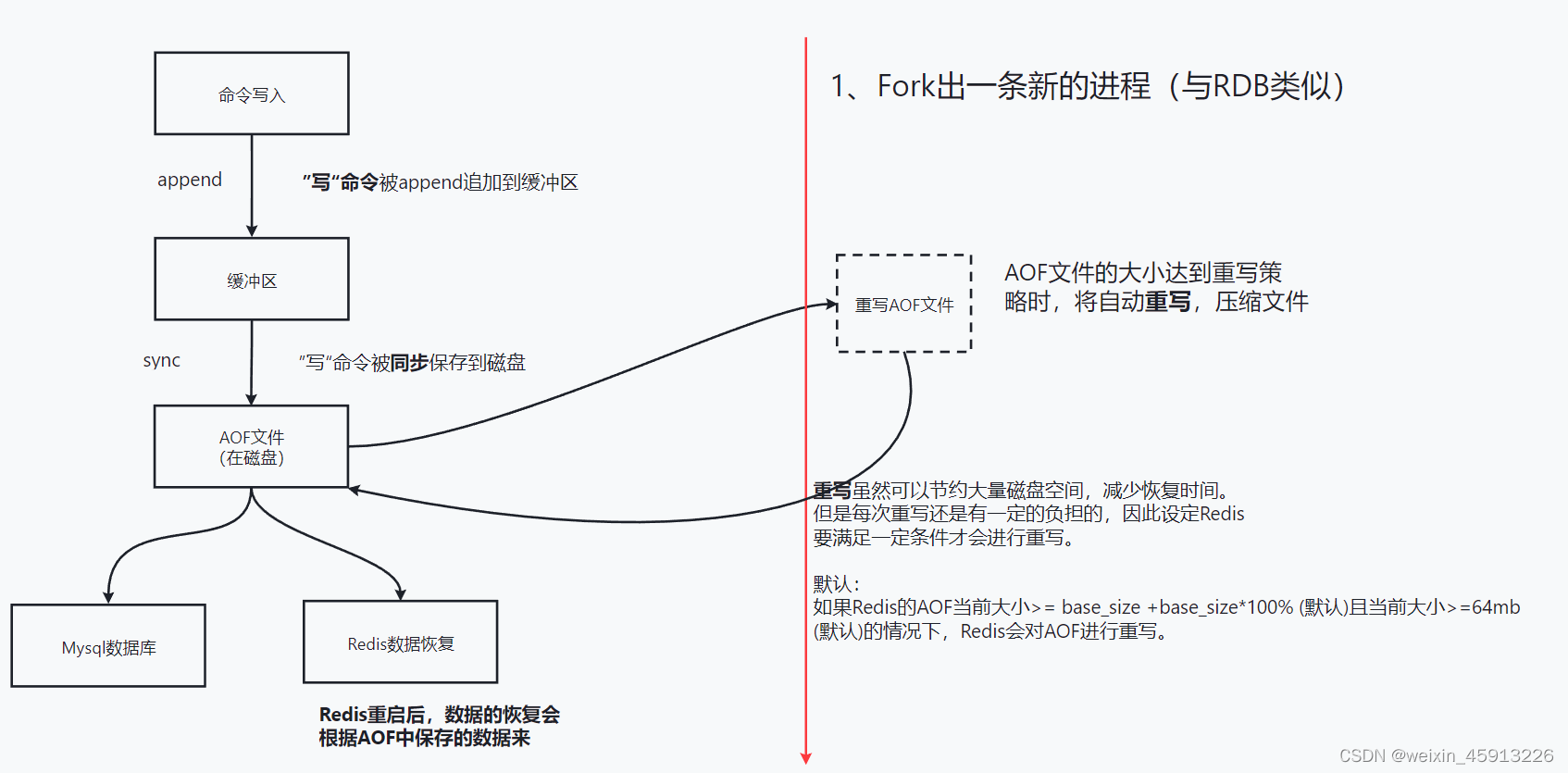
11.4AOF文件被损坏,如何恢复?

11.5 AOF同步频率



11.6 优点和缺点
- 优点:
1数据不易丢失
- 缺点:
- 空间开销大:因为AOF文件保存了“写”命令和Redis数据库中的数据,所以空间开销比RDB开销大,RDB过程产生的dump.rdb文件之保存了数据,没有命令
- 会影响系统吞吐量,AOF在同步操作命令时,会有额外的性能开销。
11.7 官方推荐

12、主从复制
12.1 主从复制是什么?
(1)是什么:
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
(2)图示:
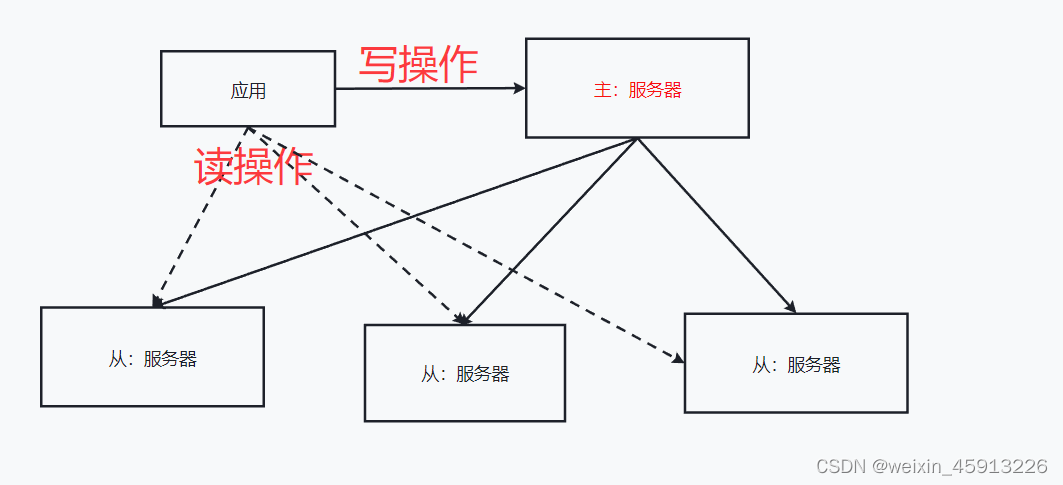
12.2为什么要有主从复制?
- 读写分离,性能提升
- 容灾快速回复:当你如果有一台从服务器挂了,其他服务器继续工作。
12.3怎么玩?:主从复制
(1)搭建1主2从
1、创建/myredis目录
2、把redis.conf配置文件复制3份到myredis文件夹(1主2从)
3、再把redis.conf里面的配置修改:
——①修改pidfile 路径为:pidfile /www/server/redis/redis_6379.pid
——②修改 port 端口号为:6379
——③修改 dbfilename为dump6379.rdb
——④方式一配主从服务器:修该 replicaof IP地址 端口号 :用来表明该服务器作为谁的从服务器
——⑤方式一配主从服务器:修改 masterauth 密码 :主机密码。
——④如果开启了AOF持久化,则需要改动aof文件的路径名。
4、启动3个Redis服务。redis-server redis6379.conf
——注意:安装redis时一定要再Redis安装目录下用make install,不然会报错:redis-server: command not found
5、查看进程: ps -ef | grep redis
6、使用redis-cli -p 端口号 :开启三个客户端连接分别连接3个redis服务。
7、①输入密码②使用info replication查看主机信息
8、方式二配主从服务器:使用 slaveof ip port 把该机器变成这个IP的这个端口的从机。

(2)测试1主2从
-
主服务器写操作:set k1 v1
-
主服务器读操作:get k1——v1
-
从服务器读操作:get k1—— v1
-
从服务器写操作:报错:你只能进行读操作
-
结论:主服务器既能写也能读,而从服务器只能读
12.4主从复制的复制原理
- 第一步:当从服务器连接到主服务器之后,从服务器主动向主服务器发送一个同步消息,
- 第二步:主服务器收到同步消息后,会把自己的数据持久化到RDB文件中,然后把RDB文件发送个从服务器。从服务器根据rdb文件进行读取。(全量复制)
- 当主服务器每次进行写操作时,主服务器主动把数据同步到从服务器。(增量复制)
12.5 常用的3招:
(1)1主2仆
- 如果从服务器挂掉,那么从服务器重启以后,它会把主服务器里面的所有数据复制一份。
- 如果主服务器挂掉,那么从服务器还是从服务器,等主服务器重启之后,还是2仆的主服务器。挂掉之前的所有数据还是有。
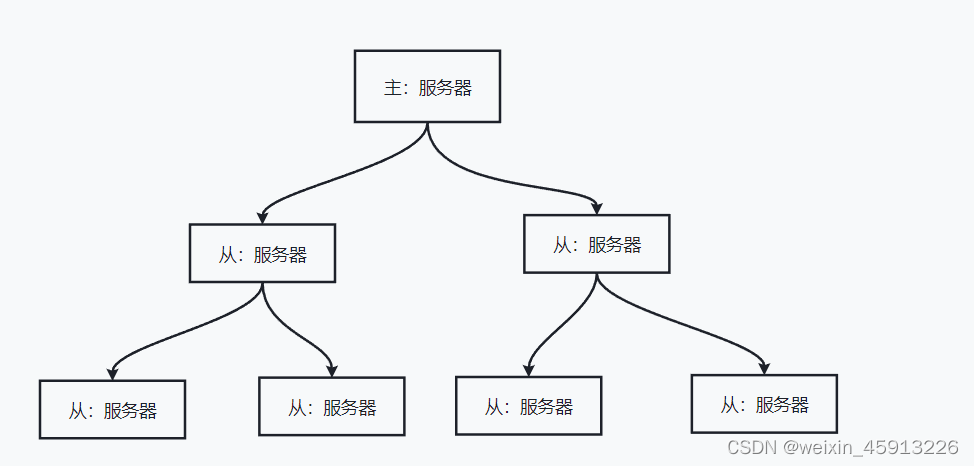
(2)薪火相传
- 图示:
- 怎么配置:只需要再一个服务器的redis配置文件修改
- 方法一:服务器的redis配置文件修改 replicaof IP地址 端口号 指定父从服务器
- 方法二:在服务器运行中使用命令: slaveof ip port 指定自己的父从服务器
- 总结:
- 优点:再从服务器的数量比较多时,有利于给主服务器分摊压力
- 缺点:当如果有中间的一台从服务器挂掉了,那么该从服务器的子从服务器,无法进行同步主服务器的数据了(中间的服务器挂了)
(3)反客为主(手动版)——(自动版:哨兵模式)
- 当主机挂掉时,我们可以让一台从机变成主机
-
命令:slaveof no one
12.6 哨兵模式(自动版:反客为主)
(1)是什么?
- 自动版反客为主,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
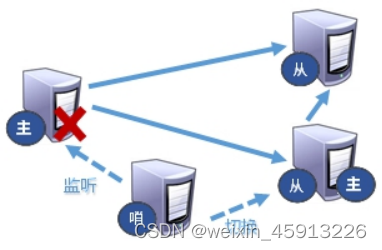
(2)怎么玩?
- 创建1主服务器,2从服务器
- 再myredis下创建sentinel.conf文件。
————内容①:sentinel monitor mymaster 127.0.0.1 6379 1。监控127.0.0.1 6379的主机,并为主机取别名为:mymaster ——1:至少有1个哨兵同意迁移。
————内容②:sentinel auth-pass mymaster 123456 -如果你主服务器密码,你不设置的话不能动态切换主从机 - 打开一个窗口启动一个哨兵(命令):redis-sentinel sentinel.conf
- 哨兵的端口和进程号

- 把主服务器的redis进程关闭。
- 哨兵会再从服务器里面选择一个当主服务器,如果启动原来的主服务器,那么原来挂掉的主服务器将变为从服务器。
(3)复制延时
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
(4)选择从服务器的规则
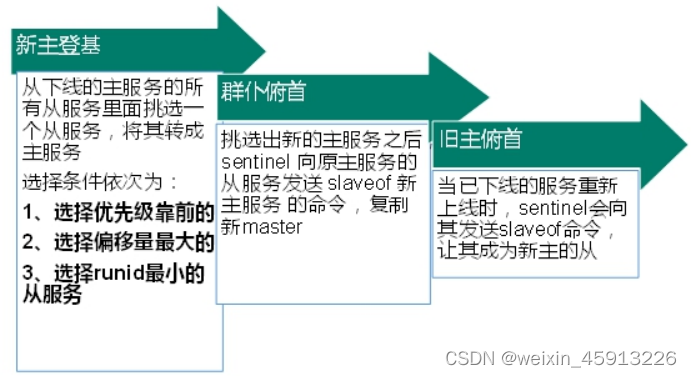
- 优先级——配置文件里

- 当优先级相同,那么就选择偏移量最大的。偏移量是指和主服务器数据相差最小的。可以省复制延时的时间。
- 每个redis实例在启动后都会生成一个随机的runid,那么就选择runid最小的。
(5)Java实现哨兵模式
13、集群
13.1 需要解决的问题?
(1)问题:
- 容量不够,redis如何进行扩容?
- 并发写操作, redis如何分摊?
- 另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。
(2)怎么解决
解决方案1:redis3之前使用代理主机。缺点:耗用的服务器数量太多了。在实际的开发中,一个redis服务器肯定对应一台Linux系统。
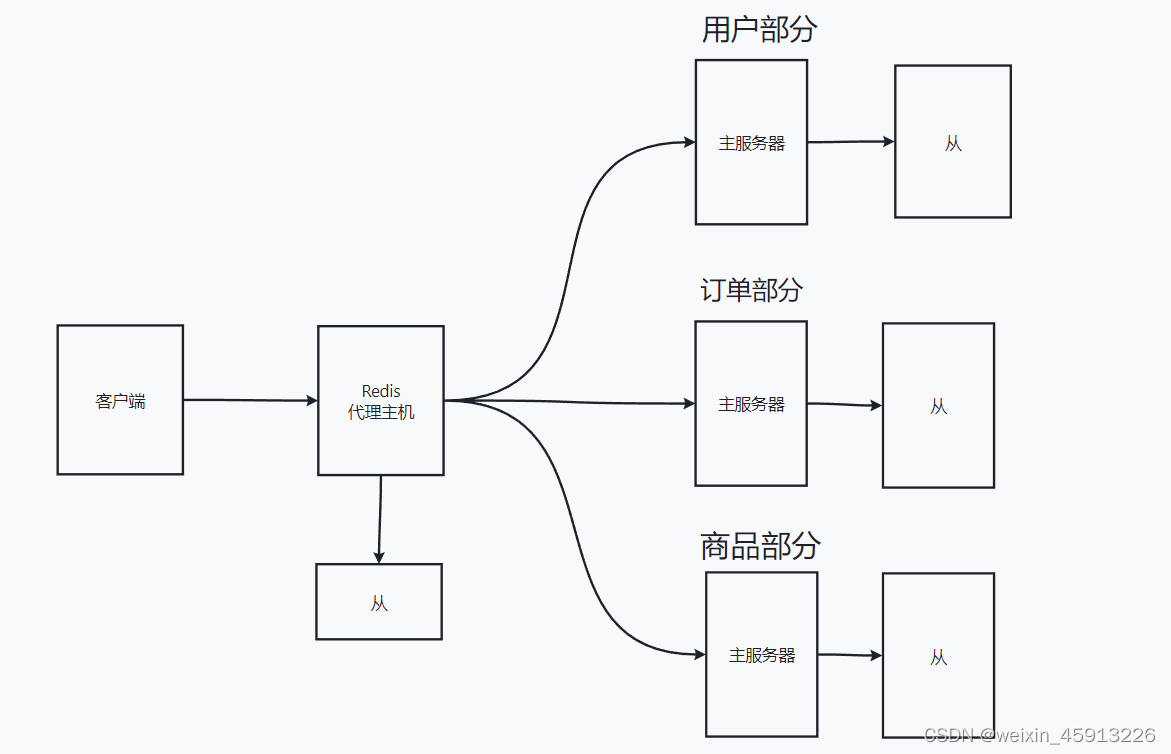
解决方案二:使用无中心化集群配置
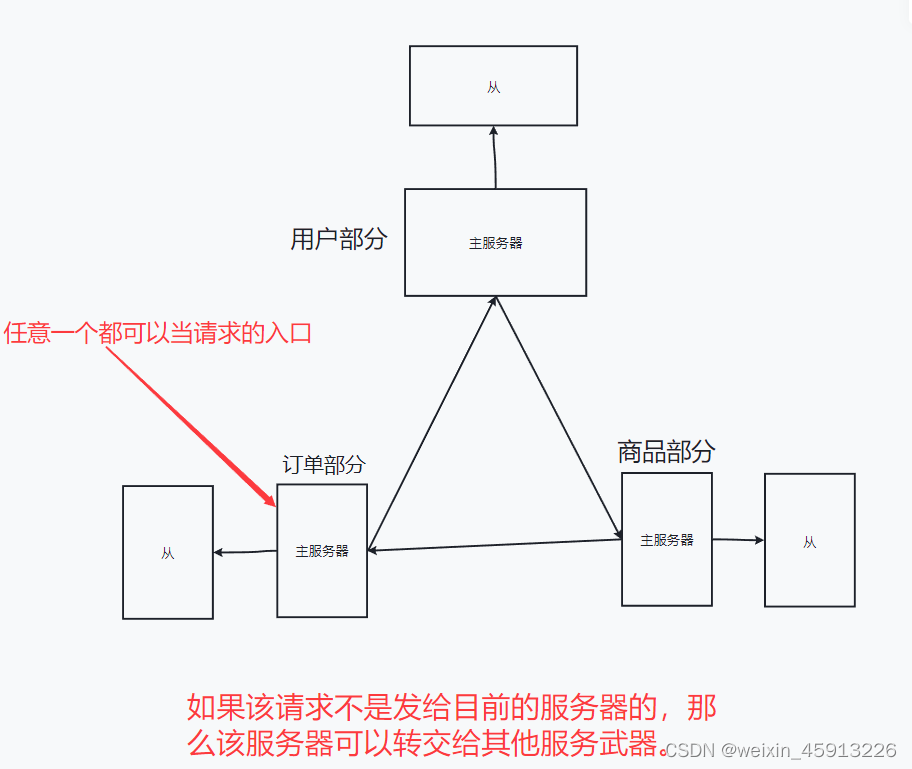
(3)Redis集群的特点:
- 实现了对Redis的水平扩容,启动N个Redis节点,那么每个节点存储总数据的1/N.
- 如果集群中某一个节点出现问题。那么其他节点可以继续提供服务。
13.2 如何搭建一个Redis集群(用端口号模拟)
(1)搭建三主三从:
- 创建/myredis目录
- 把redis.conf文件名改为redis6379.conf
- 再把redis6379.conf里面的配置修改:
——①修改pidfile 路径为:pidfile /www/server/redis/redis_6379.pid
——②修改 port 端口号为:6379
——③修改 dbfilename为dump6379.rdb
——④关闭aof持久化
——⑤cluster-enabled yes 打开集群模式
——⑥cluster-config-file nodes-6379.conf 设定节点配置文件名
——⑦cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。- 把redis6379.conf文件复制五份。
- 效果为:3主3从
- 启动6个redis服务
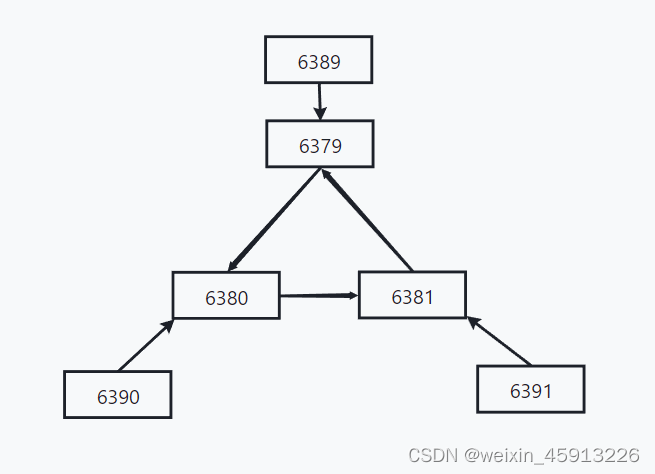
(2) 让六个节点合成一个集群:
-
重要:再阿里云和宝塔把12个端口放行(Redis服务端口+每个服务对应的集群总线端口)
-
进入www/server/redis/src目录:
-
配置集群的命令:redis-cli --cluster create --cluster-replicas 1 8.142.89.219:6379 8.142.89.219:6380 8.142.89.219:6381 8.142.89.219:6389 8.142.89.219:6390 8.142.89.219:6391
—— ①–cluster-replicas 1 ——表示1台主机1个从服务器。
——②写实际IP地址和端口号。不能用127.0.0.1。 -
成功:

(4)测试
- 使用命令:redis-cli -c -p 6379 连接到集群,集群的任意一台主机都是集群的入口。
- 使用命令:cluster nodes 查看所有节点

13.3Redis 集群怎么分配的节点?
- 一个集群至少要有3台主服务器。
- –cluster-replicas 1:配置集群的命令中的一句话:意思是:希望为集群中的每个主节点创建一个从节点。
- 集群配置的原则:尽量保证所有主机和所有从机都在不同点iP上。
13.4 插槽的概念:
- 一个Redis数据库都有16384个槽(hash slot),数据库中的每个键都属于这些槽中的一个。可以几个键存放在一个槽内。就像hashcode一样。
- 集群中的每个主节点负责处理一部分插槽。可以使用命令:cluster nodes 查看所有节点可以看出。比如:6379处理0~5640节点。
13.5 集群中的命令
- set k1 v1
- mset k1{user} v1 k2{user} v2 k3{user} v3:一次插入3个key-value,则是根据user来计算槽的位置的。原理是把k1 k2 k3 归为一个组。
- cluster keyslot k1:查询k1属于哪个槽。
- cluster countkeysinslot 5474 :查看5474这个槽有多少个键。必须要在对应的IP端口查看才能效果,5474属于8080端口管的。
13.6 故障恢复
- 一段插槽的主机挂掉:如果一个主机挂掉那么它的一个从机就顶替他作为主机,挂掉的主机如果恢复,那么该挂掉的主机就变成了从机。
- 一段插槽的主机和从机都挂掉:要看配置文件。

13.7 Jedis连接集群:
/**
* jedis连接集群测试.txt
*/
public class JedisClusterTest {
public static void main(String[] args) {
//1、可以创建一个集合,但没必要
// HashSet<HostAndPort> hostAndPorts = new HashSet<>();
// hostAndPorts.add(new HostAndPort("8.142.89.219",6379));
// hostAndPorts.add(new HostAndPort("8.142.89.219",6380));
//1、可以直接创建hostAndPort:因为搭建的是集群,集群中任意一台服务器都是入口。
HostAndPort hostAndPort = new HostAndPort("8.142.89.219", 6380);
//2、
JedisCluster jedisCluster = new JedisCluster(hostAndPort);
jedisCluster.mset("k1{user}","v1","k2{user}","v2");//集群存入一次存多个值,则需要分组。这里k1,k2都放在user组
System.out.println(jedisCluster.get("k2{user}"));
}
}
13.8 redis集群总结:
(1)好处:
- 实现了扩容
- 分摊了压力
- 无中心化配置操作方便
(2)坏处
- 多键操作麻烦。需要分组
- 多键的Redis事务是不被支持的。lua脚本不被支持
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
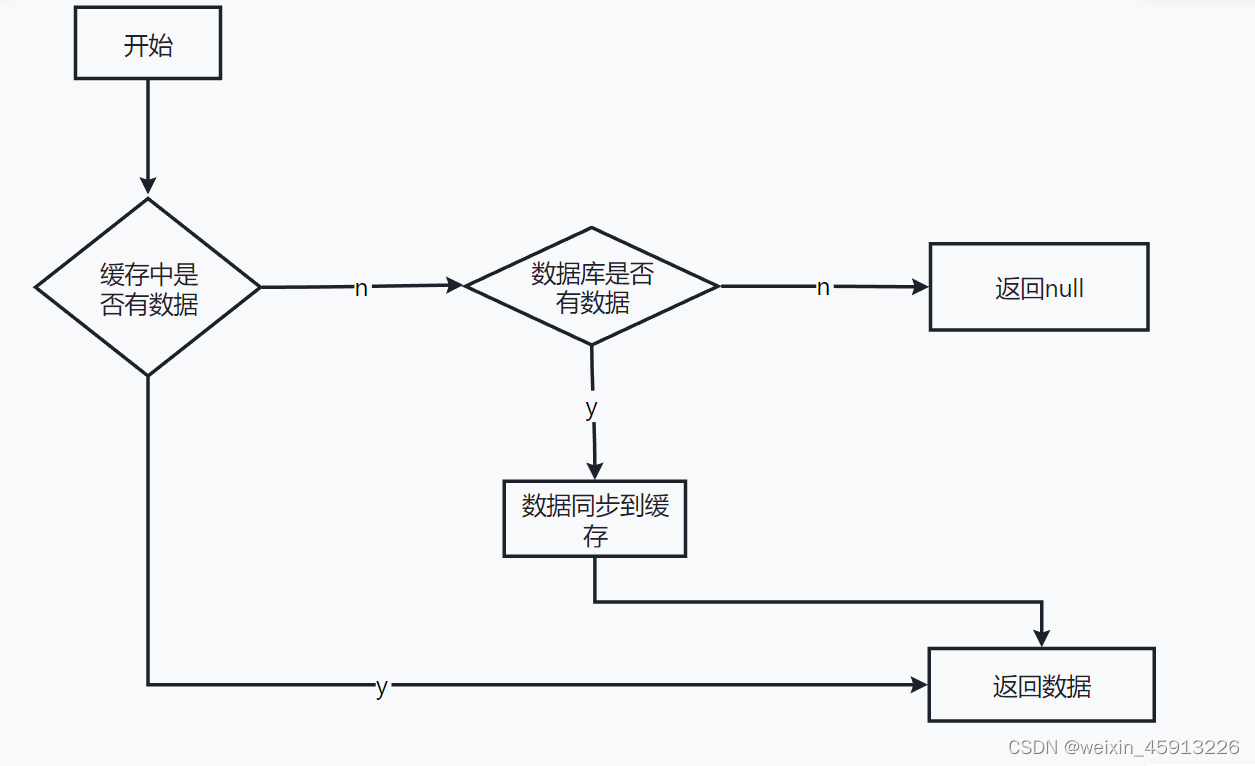
14 、Redis应用问题解决
14.1 缓存穿透
(1)什么是缓存穿透
- 在获取redis缓存中的key,如果缓存中没有找到,那么从而会向数据库(MySQL)进行查找,有可能压倒数据源。比如黑客一直请求不存在的id,那么就容易引起数据库的崩溃。
(2)解决方案
- 对空值缓存:如果一个数据的查询结果返回为空,那么我们将对这个空值进行缓存,让key=null;空值最多持续5分钟。(不方便)
- 设置可访问名单(白名单)。使用bitmaps数据结构,把可访问的id都存放到里面,id作为bitmaps的偏移量。(缺点:每次的请求id都需要和bitmaps里面的值比较,看id在bitmaps存在不,耗时长)
- 使用布隆过滤器(最优):优点:查找速度比一般的算法来的快。缺点:误判率比较高,删除困难。底层就是把数据hash到一个bitmaps中,一定不存在的数据会被bitmaps拦截掉。从而减小数据库的访问压力。
- 使用监控,监控到如果某一台主机经常访问某个不存在的id,就把它加入黑名单。
14.2 缓存击穿
(1)什么是缓存击穿
- 当一个key在Redis中刚好过期,这时候这个key访问量突然增大,使数据库压力过大,后端DB压垮。
(2)解决方案
- 预先设置热门数据。
- 实时调整,如果发现某几个key热度突然增加,则增加它的过期时间。
- 加锁方式:由高并发转低并发(一般使用分布式锁)。
14.3 缓存雪崩
(1)什么是缓存雪崩
- 当缓存有大量的key过期,这时就会造成数据库访问量过大。缓存失效时的雪崩效应对底层系统的冲击非常可怕!
(2)解决方案
- 构架多级缓存架构:nginx缓存+Redis缓存+其他缓存。缺点:实现起来很复杂
- 使用锁或者队列:能保证DB不down机,但不适用于高并发场景
- 设置过期标志:当缓存中key快过期了,则通知其他线程去延长过期时间。
- 将失效时间分散开来:让key的有效时间随机延迟1~5分钟。就不会造成集体失效现象。
14.4 分布式锁
(1)什么是分布式锁?
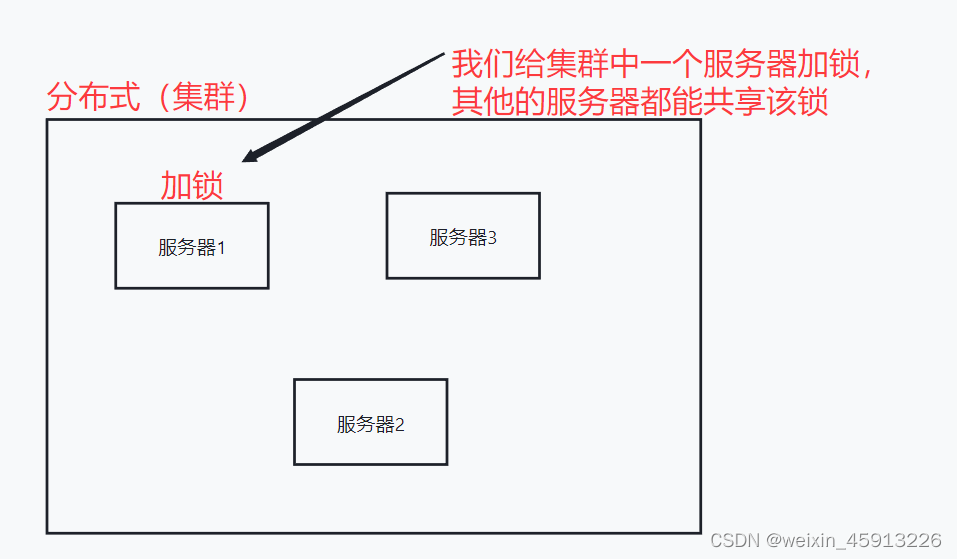
(2)主流实现方案:
- 基于数据库实现分布式锁
- 基于缓存(redis)实现 :性能高
- 基于zookeeper实现 :可靠性好
(3)Redis实现分布式锁。
- 设置锁:setnx key value :设置key-value并加锁
- 释放锁:①删除键(手动释放):del key;②设置锁的过期时间:expire key 时间
- 设置锁和释放锁(设置过期时间)的原子操作:set key value nx ex 加秒。
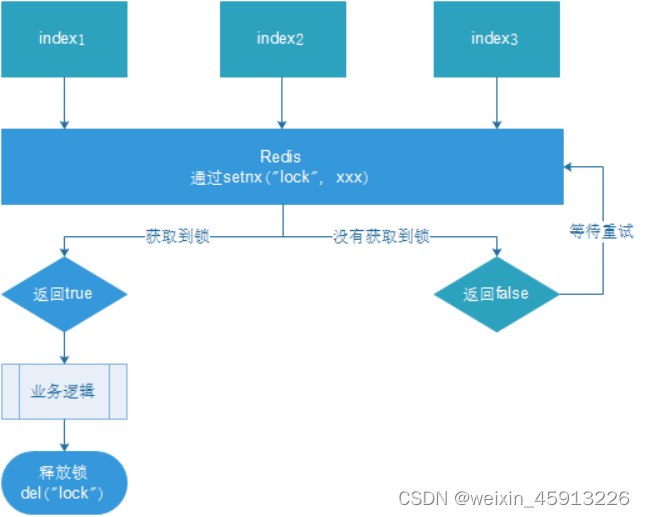
(4)Java实现分布式锁。(上锁和去锁)
- SpringBoot实现:
/**
* 分布式锁Java代码实现.txt
*/
@RestController
public class Test {
@Autowired
RedisTemplate redisTemplate;
@GetMapping("/test")
public void testLock(){
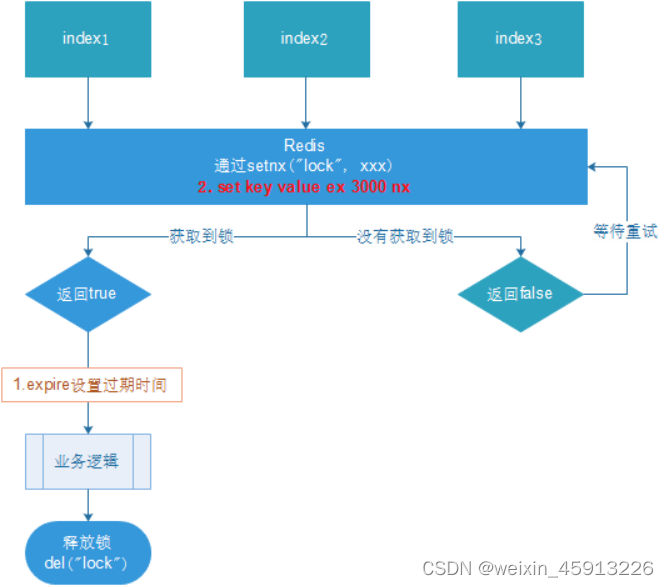
//1 获取锁,要要给锁加过期时间;如果业务逻辑出现问题锁才会自动释放:这里为11秒过期
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111",11, TimeUnit.SECONDS);
//2 获取锁成功、查询num值
if(lock){
Object value = redisTemplate.opsForValue().get("num");//redis中set num 0;
//2.1判断num为空return
if(StringUtils.isEmpty(value)){
return;
}
//2.2有值就转换为int
int num = Integer.parseInt(value + "");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num",++num);
//2.4释放锁,手动释放
redisTemplate.delete("lock");
}else {
//3.获取锁失败就隔0.1秒在获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
上述代码的业务逻辑为:
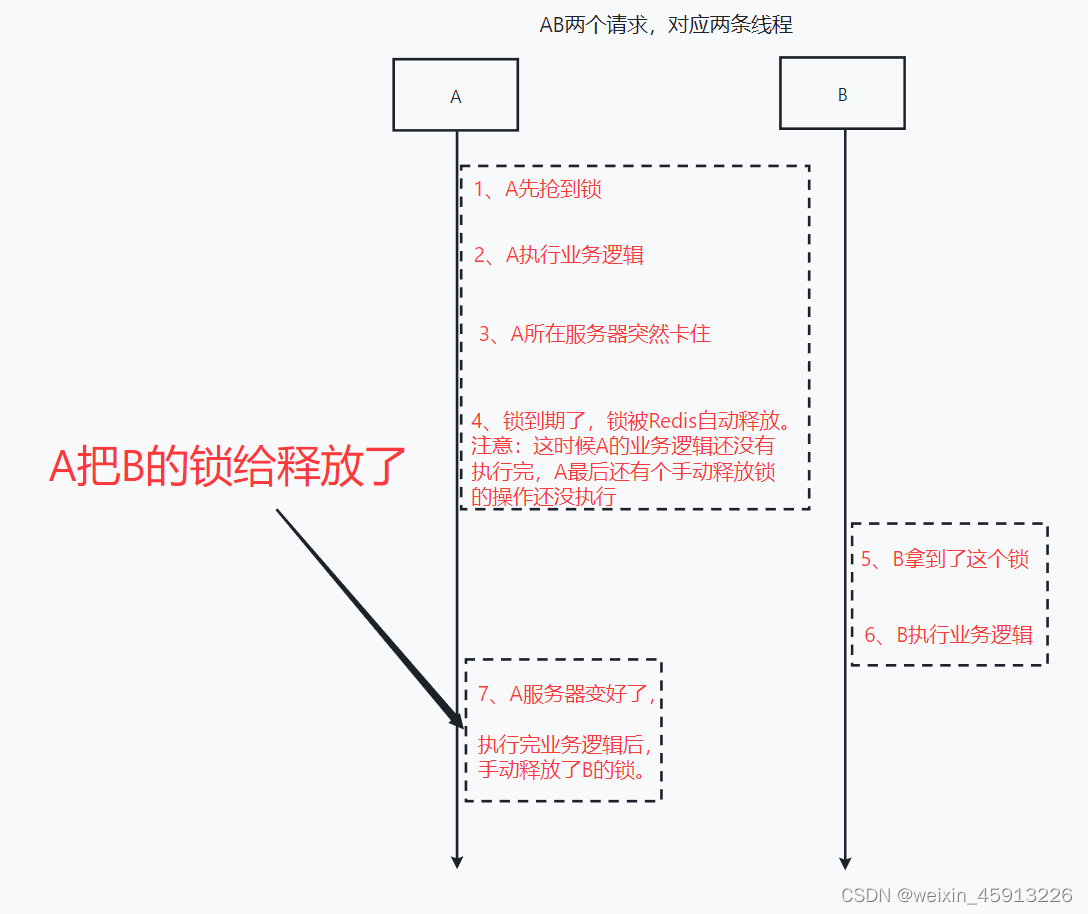
(5)分布式锁中的锁的误删问题。(给锁加UUID解决该问题)
改进:给每个锁加了uuid
/**
* 分布式锁Java代码实现.txt
*/
@RestController
public class Test {
@Autowired
RedisTemplate redisTemplate;
@GetMapping("/test")
public void testLock(){
//为每个拿到锁的线程都生成一个uuid.
String uuid = UUID.randomUUID().toString();
//1 获取锁,要要给锁加过期时间;如果业务逻辑出现问题锁才会自动释放:这里为11秒过期
//key:lock——————value:uuid+分界线+实际的value。
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid+"uuid与value的分界线"+111,11, TimeUnit.SECONDS);
//2 获取锁成功、查询num值
if(lock){
Object value = redisTemplate.opsForValue().get("num");//redis中set num 0;
//2.1判断num为空return
if(StringUtils.isEmpty(value)){
return;
}
//2.2有值就转换为int
int num = Integer.parseInt(value + "");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num",++num);
//2.4释放锁,手动释放——判断_当前线程持有的锁的uuid_是否与_Redis缓存中该key的锁的uuid_相等
String lock1 = (String) redisTemplate.opsForValue().get("lock");
String[] s = lock1.split("uuid与value的分界线");//把从Redis中取出的value以“分界线”,分解 成uuid和实际value值
String redis_uuid1=s[0];
System.out.println("redis_uuid:"+s[0]);
System.out.println("value:"+s[1]);
if(uuid.equals(redis_uuid1)){
redisTemplate.delete("lock");
}else {
return;
}
}else {
//3.获取锁失败就隔0.1秒在获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
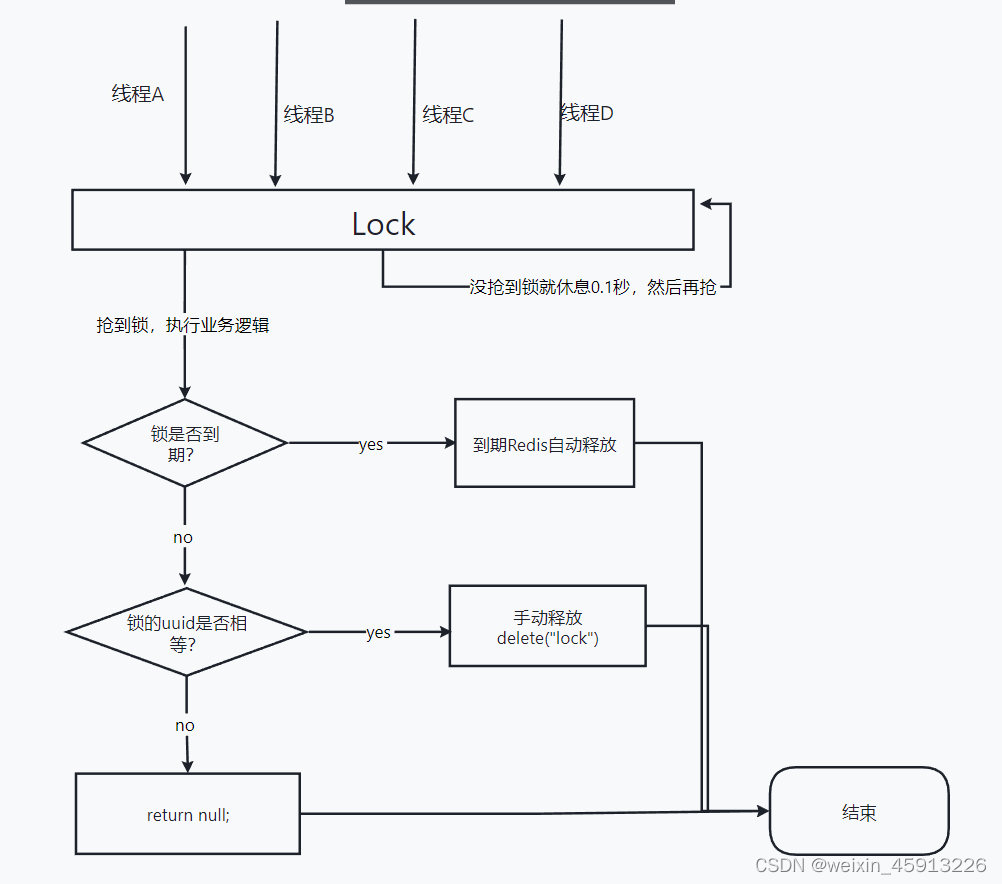
- 现在的逻辑为:
(6)lua脚本的使用:保证原子性
-
使用原因:
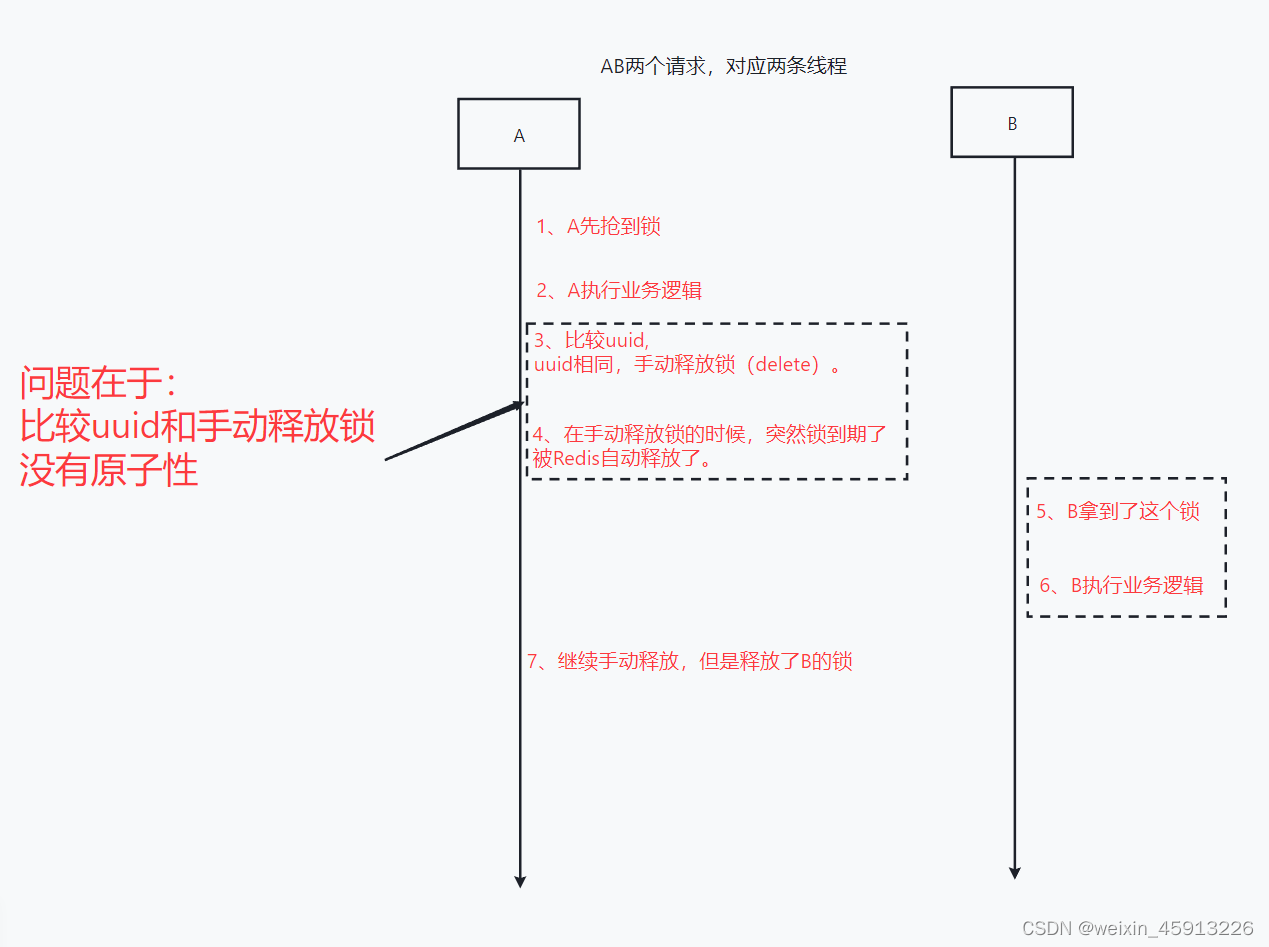
-
Lua脚本怎么写可以参考菜鸟教程
@RestController
public class TestLockLua {
@Autowired
RedisTemplate redisTemplate;
@GetMapping("/testLockLua")
public void testLockLua() {
//为每个拿到锁的线程都生成一个uuid.
String uuid = UUID.randomUUID().toString();
//定义一个锁:lua脚本可以使用同意把锁来实现删除
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
//1 获取锁,要要给锁加过期时间;如果业务逻辑出现问题锁才会自动释放:这里为11秒过期
//key:lock——————value:uuid+分界线+实际的value。
String value=uuid + "uuid与value的分界线" + 111;
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, value, 11, TimeUnit.SECONDS);
//2 获取锁成功、查询num值
if (lock) {
Object num = redisTemplate.opsForValue().get("num");
//2.1判断num为空return
if (StringUtils.isEmpty(num)) {
return;
}
//2.2有值就转换为int
int num1 = Integer.parseInt(num + "");
//2.3把redis的num1加1
redisTemplate.opsForValue().set("num", ++num1);
//2.4释放锁,手动释放——判断_当前线程持有的锁的uuid_是否与_Redis缓存中该key的锁的uuid_相等
String lock1 = (String) redisTemplate.opsForValue().get(locKey);
//使用lua脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
//使用redis执行lua
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
//设置一下返回值的类型 为 Long
//因为删除判断时,返回的0时String类型,需要封装成Long来判断;
redisScript.setResultType(Long.class);
redisTemplate.execute(redisScript,Arrays.asList(locKey),value);
} else {
//3.获取锁失败就隔0.1秒在获取
try {
Thread.sleep(100);
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
(7)分布式锁总结
- 为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。(设置过期时间)
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。(uuid的判断和使用LUA脚本保证原子性)
- 加锁和解锁必须具有原子性。
15、Redis6 新特性
15.1 ACL(了解)
(1)简介:
- Redis ACL是Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。
- 在Redis 5版本之前,Redis 安全规则只有密码控制 还有通过rename 来调整高危命令比如 flushdb , KEYS* , shutdown 等。Redis 6 则提供ACL的功能对用户进行更细粒度的权限控制 :
(1)接入权限:用户名和密码
(2)可以执行的命令
(3)可以操作的 KEY
参考官网: https://redis.io/topics/acl
15.2 IO多线程
(1)简介:
-
Redis6终于支撑多线程了,告别单线程了吗?
-
IO多线程其实指客户端交互部分的网络IO交互处理模块多线程,而非执行命令多线程。Redis6执行命令依然是单线程。
-
redis6多路IO默认不开启,配置文件修改,redis7好像默认启用了。
io-threads-do-reads yes
io-threads 4
15.3 Redis6新功能
- RESP3新的 Redis 通信协议:优化服务端与客户端之间通信
- Client side caching客户端缓存:基于 RESP3 协议实现的客户端缓存功能。为了进一步提升缓存的性能,将客户端经常访问的数据cache到客户端。减少TCP网络交互。
- 集群代理(Redis Cluster Proxy): 将集群抽象为单实例,客户端不需要知道集群中的具体节点个数和主从身份,通过代理访问集群,就像访问单机。Redis一样不过需要注意的是代理不改变 Cluster 的功能限制,不支持的命令还是不会支持,比如跨 slot 的多Key操作。
- 自动化路由:每个查询被自动路由到集群的正确节点。
- 多线程,每个线程都有自己与集群的连接
- 顺序性,只执行命令时时串行的
- 把2、3点总结为:单线程+多路IO复用技术
- Modules API:
Redis 6中模块API开发进展非常大,因为Redis Labs为了开发复杂的功能,从一开始就用上Redis模块。Redis可以变成一个框架,利用Modules来构建不同系统,而不需要从头开始写然后还要BSD许可。Redis一开始就是一个向编写各种系统开放的平台。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









