






 本文介绍了中通大数据平台如何通过采用Celeborn的RemoteShuffleService(RSS)来提升SparkShuffle的性能和稳定性,特别是通过磁盘负载感知、智能流控和AQE支持等特性,有效解决了磁盘利用不均衡、网络连接压力和数据可靠性等问题,显著提高了ETL任务的执行效率和整体系统的稳定性。
本文介绍了中通大数据平台如何通过采用Celeborn的RemoteShuffleService(RSS)来提升SparkShuffle的性能和稳定性,特别是通过磁盘负载感知、智能流控和AQE支持等特性,有效解决了磁盘利用不均衡、网络连接压力和数据可靠性等问题,显著提高了ETL任务的执行效率和整体系统的稳定性。

随着公司业务体量不断发展,多个业务线依赖于大数据平台开展数据业务,大数据底层系统的稳定和高效成为了公司业务正常运转的基石。中通的大数据平台的基座依托于Hadoop,目前公司90%的ETL任务基于Spark-Sql引擎构建的,每天线上运行的 Spark任务有12w+,每天Shuffle产生的数据规模达6PB以上,同时单次Shuffle数据最大规模达数百TB以上,巨大的Shuffle数据量和复杂的计算环境使得Spark的Shuffle过程面临巨大挑战。因此保证Shuffle稳定性对Spark任务的执行效率和稳定性显得至关重要。
中通Spark Shuffle采用了社区的External Shuffle Service方案,我们称ESS方案。ESS的Shuffle服务是内嵌在NodeManager中,Spark Eexcutor参与Shuffle过程时,Shuffle Write阶段,Map任务产生的数据直接Shuffle写入到本地存储介质。Shuffle Read阶段,Reduce任务读取Shuffle数据文件时,无需从Executor获取,直接从内嵌在NodeManager中的ESS服务获取。通过上述方式完成了Shuffle的数据交互,如下图所示的ESS数据交互过程。
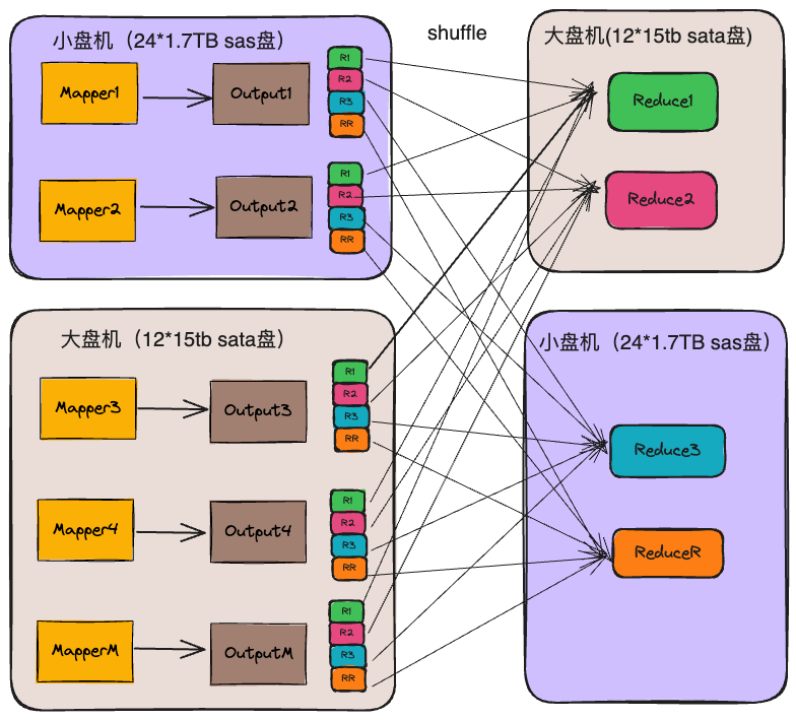
ESS数据交互过程
Shuffle过程会涉及到频繁的磁盘IO和网络连接,它的主要作用是将所有Map任务产生的数据进行重分区并重组,提供给下游Reduce任务使用,该方案的好处是Shuffle数据获取不受Eexcutor是否退出的影响。但是该方案也存在一些不足和弊端,主要表现以下三个方面:

目前中通的离线集群主流的机型的磁盘配置主要分为二种:
1)24块SAS盘(单盘1.7TB HDD)
2)12块SATA盘(单盘15TB HDD)
由于单机的io能力存在非常巨大的差异,在etl高峰时期导致12块的SATA盘的磁盘利用率一直处于在高水位,而24块盘的SAS盘利用率却一直不高,整个集群的磁盘利用率非常的不均衡,从而我们作业的长尾任务非常严重,ETL时效无法得到有效保障。
即使我们在去年扩容了数百台物理机,但整个etl时效并没有得到提前,甚至任务运行的更加不稳定,这也是我们目前遇到的最大的痛点问题。

在ESS架构下的Shuffle Read阶段,每个NodeManager所在的机器都会收到Reducer发来的数据请求,这就涉及到了M乘以N级别的网络连接和磁盘的随机读写,很容易将磁盘的iops打到上限,使得整个shuffle的速度比较缓慢,甚至出现Fetch Failed情况。

每个Mapper在Shuffle Write阶段写入数据到本地磁盘,数据有且只有一份,如果发生磁盘故障或者机器宕机了,数据就会丢失。可能引起Spark Stage级别的重算,造成ETL延迟。


Spark Remote Shuffle Service (简称RSS),这是一种基于推送的shuffle服务。核心思想,基于push的shuffle的概念。在shuffle Write阶段,Mapper产生shuffle数据被推送至远端的shuffle服务,并按照partition进行合并。在Shuffle Read阶段,Reducer从远端的shuffle服务读取合并的Shuffle文件。如下图所示为RSS数据交互过程。
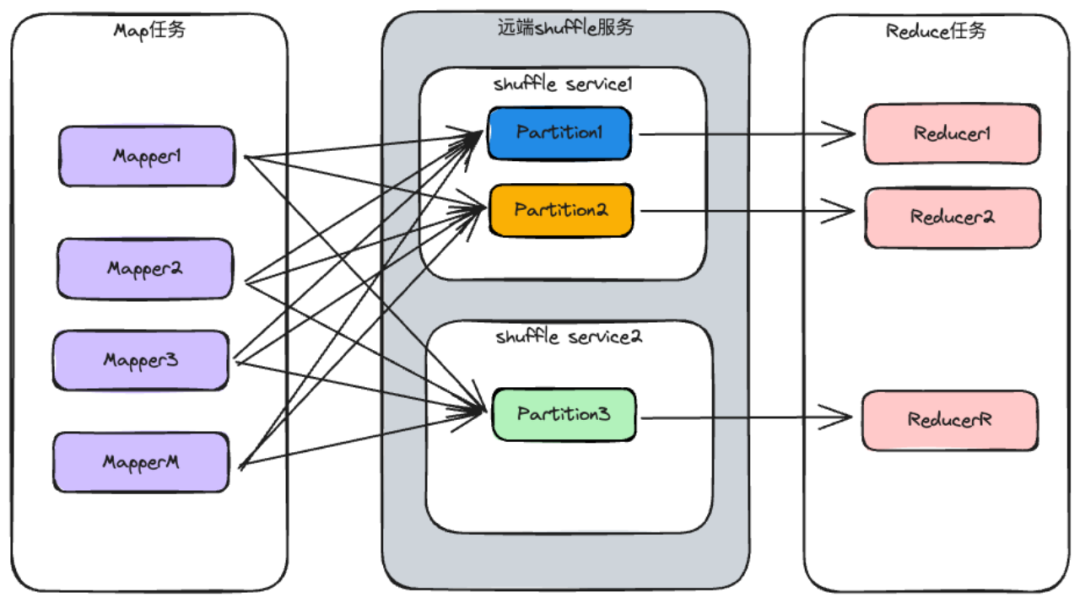
RSS数据交互过程
RSS为spark shuffle带来几个关键性的好处。
1) 提升磁盘IO效率
在传统的ESS的方案中,都是大量小的随机IO。但是,基于推送的shuffle,reducer读取数据时,从ESS原有的小的随机读写变为大的顺序读写,磁盘IO性能得到了提升。
2)缓解了shuffle可靠性问题
在ESS方案中,需要每个 reduce 任务都能成功地从所有 map 任务中获取每个相应数据,这在拥有数千个节点的繁忙集群通常无法满足。RSS通过提供多个shuffle数据副本保证了shuffle的可靠性。
3)降低网络数
在ESS方案中,Mapper和Reducer数量乘数决定了整体的网络连接数,而在RSS中,Mapper和Reducer数量线性关系决定了整体的网络连接数,大大降低了网络连接数的数量。
Celeborn是阿里云捐赠给Apache软件基金会的专注于处理Shuffle中间数据Remote Shuffle Service,致力于打造统一的中间数据服务,助推计算引擎提升性能和稳定性。目前已经广泛运行在包括阿里云、小米、shopee、网易等在内的各大企业中。Celeborn具有磁盘负载感知,双副本机制,支持AQE,基于推送shuffle服务,智能流控反压,原地升级,优雅下线机器等优点。
今年年初我们调研了业界几乎所有的RSS的开源实现,最终我们选择Celeborn作为Spark计算引擎的统一Shuffle中间数据服务,因为它具备以下几个独特的优势。
1)磁盘负载感知
Celeborn为作业分配资源时,从磁盘视角出发的,将整个集群的所有磁盘进行统一的分配,如下图所示的磁盘Slots分配流程。
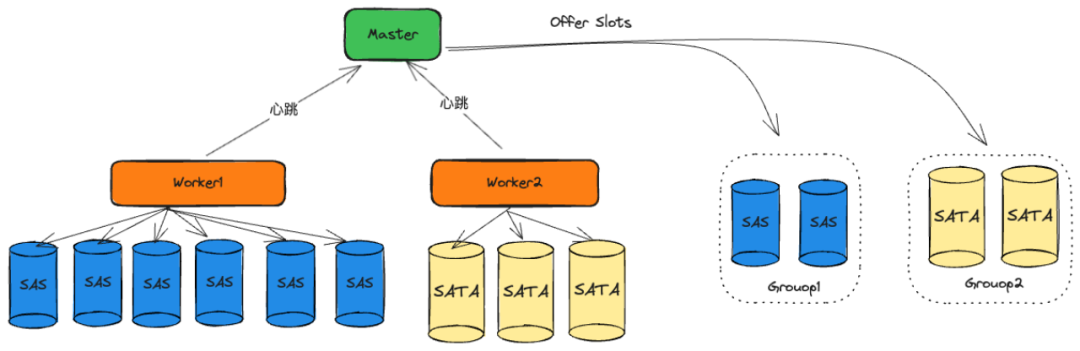
磁盘Slots分配流程
它将磁盘分为两个组,一个为快盘组,一个是慢盘组,并且实时感知磁盘的读写性能,按照一定梯度在两个组中间分配磁盘资源,通过调整梯度能够最大化利用集群磁盘的性能。该特性对于中通异构磁盘的集群非常友好,使用了Celeborn的RSS服务就不用考虑物理机磁盘数量或磁盘IO能力的差异,Celeborn利用实时感知磁盘的能力帮我们解决该问题,该能力可以帮我们做到更均衡的使用集群IO资源提升Spark Shuffle效率,保证了Spark ETL作业的执行效率和稳定性。
2)智能流控反压
由于我们的部署方式采用完全混合部署,因此我们需要严格控制内存的配置,以避免Worker机器内存被耗尽导致无法正常提供服务。为此,Celeborn设计了拥塞控制和流量控制机制。
拥塞控制方面,参考了TCP的拥塞控制机制,其中包括慢启动、拥塞避免和拥塞控制三个环节。在Shuffle Write阶段,数据推送开始时处于慢启动阶段,推送速率逐渐增加。一旦达到阈值,便进入拥塞避免阶段,推送速率以较缓慢的固定斜率增长。如果Worker内存达到警戒线,将触发拥塞控制,向每个client发送一条消息。Client接收到消息后,将回到慢启动阶段,推送速率也会降低。
流量控制方面,基于Credit Based的实现。具体来说,Client发送数据之前,先向Worker获取一定的Credit,这意味着Worker为Client预留一部分内存,Client推送不超过Worker分配的Credit的数据。这种机制保证了对内存的精准控制。但是,对性能有一定的损耗。
总体上,该特性在保证了Shuffle Write阶段,Celeborn能够同时兼顾瞬时流量的高峰和稳定态的性能的一种能力。
3)支持Spark 2.x AQE
Celeborn天然支持Spark 2.x AQE特性,因为中通Spark是基于Intel的Spark2.3.2 AQE分支衍生出来的。该特性的支持大大降低了集成RSS上的复杂度。
4)支持主流离线计算引擎
Celeborn不仅仅支持Spark离线计算引擎,还支持MR、Flink Batch等离线计算引擎,并覆盖了中通的所有的离线计算场景,未来我们完全可以使用一个组件覆盖所有的shuffle场景。

我们今年在4月份开始对celeborn0.3.0做深度测试工作,期间也遇到了一些问题,下面我们整理了一些我们所遇到问题做一些分享。

现象:多个大数据量的Spark作业执行速度慢,Worker日志出现大量的Trim Action,如下图所示:

原因:这是由于Netty的Thread-Local Cache引起的,社区的这两个patch CELEBORN-796和CELEBORN-897, 就是全局地将Thread-Local Cache关闭,从而改善了Netty的内存使用。
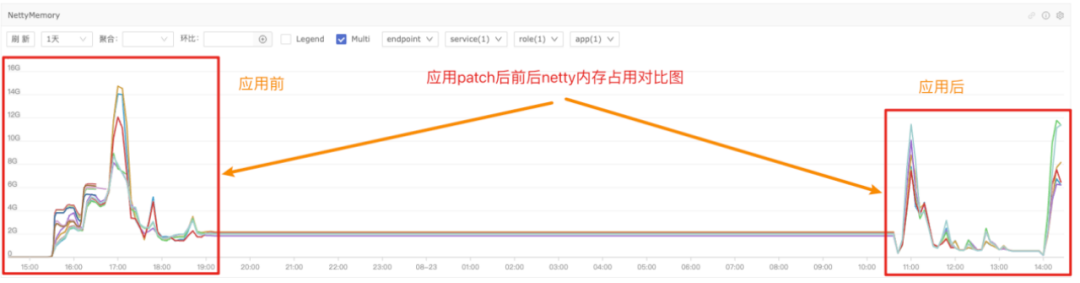
解决:通过合并上述两个Patch,重新测试,多个大数据量的Spark作业明显变快,Netty内存使用也得到很好的改善,如下图所示:

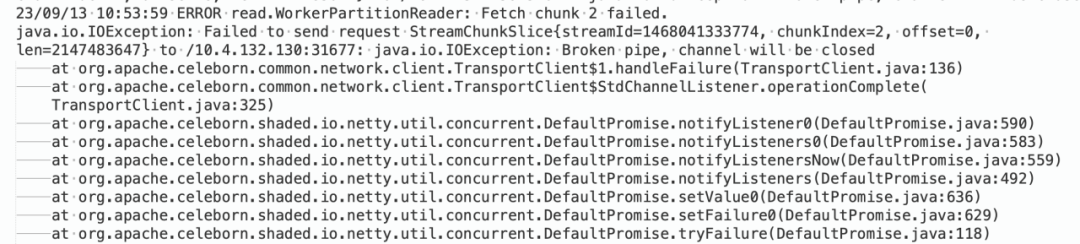
现象:Spark作业执行总是不成功,Task的异常堆栈,如下图所示:
原因:StorageManager中存在并发数据清单fileInfos,当spark app开始往worker写入shuffle数据时,先在磁盘创建shuffle file, 然后将该file添加至fileInfos。另外一个清理过期app的线程直接从磁盘读取shuffle file, 通过fileInfos进行过滤出不在其中的shuffle file,进行清理。两个并发的线程之间会导致fileInfos数据与磁盘shuffle file不一致,从而导致新创建没来得及写入数据的shuffle file被误删,进而导致spark app由于文件误删而失败。
解决:我们修复了这一块的代码bug。
为此,我们为社区贡献了pr CELEBORN-1005。

原因:过期app清理数据机制和shuffle运行结束的清理数据机制逻辑存在重合,使得过期app数据清理时,一并将该app的新的shuffle阶段的数据给删除了,导致spark的reduce任务无法读取到被删除的数据而失败。例如,一个app的shuffle(application_1689848866482_13046341_1-18)触发了cleanupExpiredShuffleKey,那可能这个时候fileInfos清单为空。
接着cleanupExpiredAppDirs这个线程就可能就会把/rss/application_1689848866482_13046341_1所有的子目录删除,删除的时候可能有新的ReserveSlots,这个时候可能会把新创建的目录给删除。
解决:在cleanupExpiredAppDir使用参数celeborn.worker.storage.expireDis.timeout增加判断,只删除12小时之前的app过期的目录,即可避免该问题。
为此,我们为社区贡献了pr CELEBORN-1046。

现象:如下所示,当Driver内存溢出时,通过dump内存分析,可以看到内存中积压PbPartitionLocation对象达500多万个。
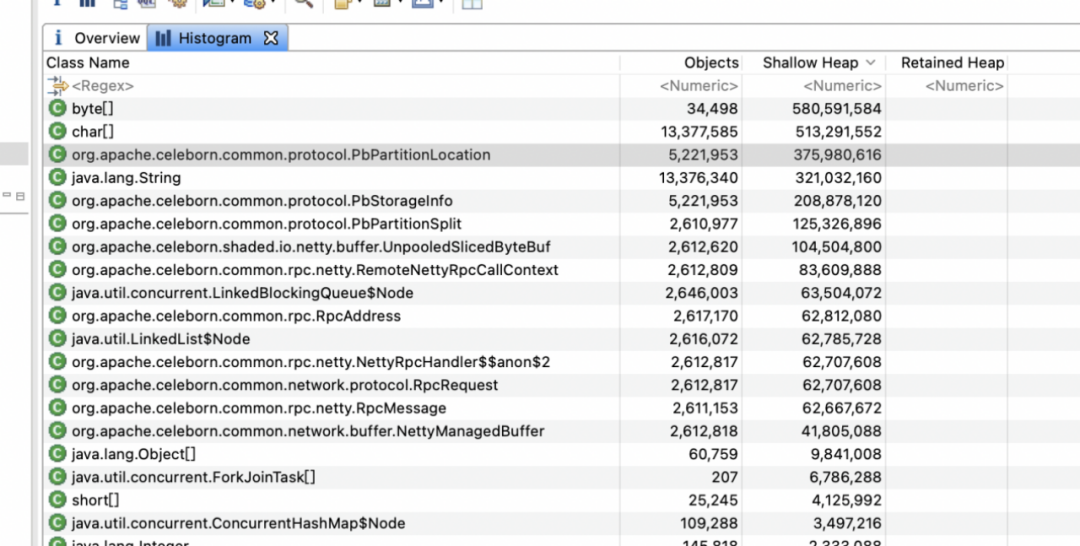
原因:假一个Spark作业并发度为3000, 每个MapTask处理1000个分区,如果Mapper处理的数据压缩率比较高,解压后每个分区数据的大小都大于1GB,就达到了Split的触发阈值1GB。如果所有MapTask写入的数据同时触发PartitionSplit, 每个MapTask产生1000个Split消息,在一瞬间至少会产生300(3000*1000)万条rpc请求,堆积在Driver的rpc收件箱,Driver端处理线程处理不过来,或者GC不过来或不及时等原因,最终导致Driver内存溢出。
解决:正常情况下只有少数异常分区才会触发split请求,由于数据的压缩率导致的大规模split的场景还是比较少见的,所以我们适当了提高了参数spark.celeborn.client.shuffle.partitionSplit.threshold阈值由1G改为10G,规避了这种场景下导致的driver oom。

现象:这意味着该机器几乎不参与rss的工作,如下图所示,查看机器的磁盘负载几乎没有负载,磁盘可用空间富余,对于已经分配出去的Slots也能正常工作。
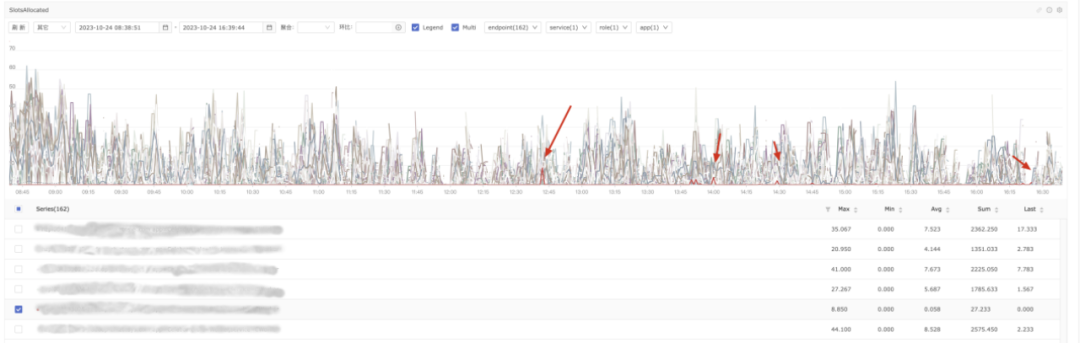
原因:磁盘资源Slots分配机制使用的是loadAware。可能的情况是,部分机器被loadAware排序到尾部,而loadAware机制排序时参照的指标是fetchTime。由于fetchTime的滑动窗口指标采集门槛阈值设定过高(为100),导致磁盘指标数据无法进入该窗口,从而fetchTime指标一直不更新。这导致该机器的磁盘一直排在最后,无法参与Slot的分配。
解决:经过研究源码,发现将参数celeborn.worker.diskTime.slidingWindow.minFetchCount由100改为0,可以避免该问题。这样做的原理是:30秒一个采样点,如果这个30秒里面没有数据,填进去是0,那这个窗口出来的平均值也是逐步降低的。这样一部分slot就可以分配出去,当Spark作业启动后,fetchTime应该会越来越准确。

现象:查看Worker日志发现,出现大量的NPE异常,如下图:
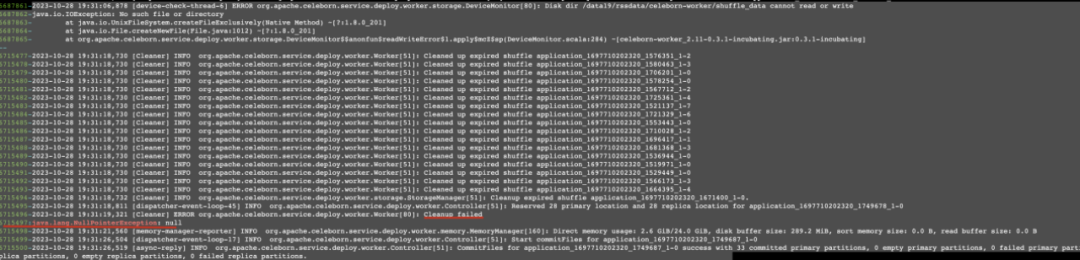
原因:一个坏盘出现时,如果清理过期的shuffle keys,从StorageManager中字段diskOperators获取某个shuffle key对应的线程池会抛出NullPointerException,导致后续shuffle key对应的过期数据无法清理,使得磁盘的可用容量减少,直至磁盘容量告警。
解决:celeborn清理机制,过滤掉状态异常的磁盘,只清理状态正常的磁盘,就不会抛出NPE异常,从而导致退出逻辑。
为此,我们为社区贡献了pr CELEBORN-1103。

由于我们的监控系统没有采用prometheus,celeborn原生提供了prometheus的支持,对于我们的监控系统只支持json格式不是很友好,我们定制了支持json格式指标采集。
为此,我们为社区贡献了pr CELEBORN-1122。

今年4月份开始我们开展调研和验证Celeborn的工作, 8月份开启非核心etl时段的部分测试队列灰度测试,并在10月底将灰度时间延长到凌晨1点,10月份我们将celeborn升级至最新的0.3.1,并平稳度过整个双十一大促,12月份我们已将所有的spark任务接入celeborn并稳定运行至今。Celeborn落地的整个里程碑如下图所示:

至此,Celeborn基本在中通已经完全落地,架构升级后给我们带来了巨大的收益,主要体现以下几个方面:

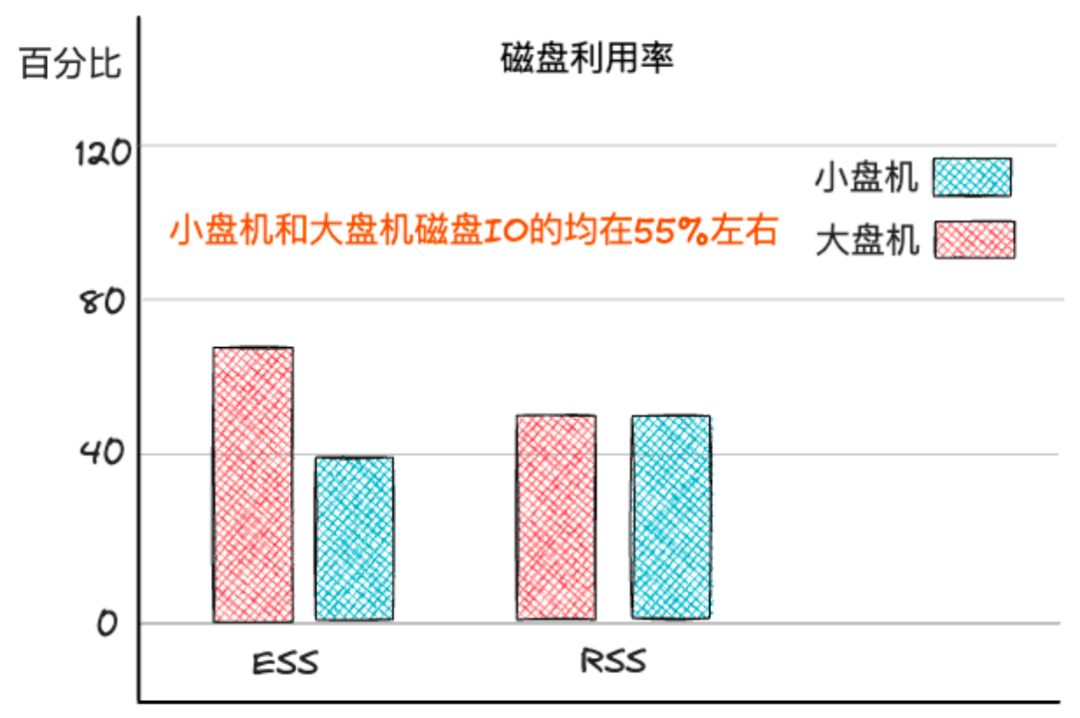
落地celeborn,本质利用其磁盘感知能力,充分利用小盘机快IO能力,提高小盘机器磁盘利用率,降低大盘机器的磁盘利用率,使得整体集群的磁盘利用率更均衡,从而提升spark etl任务的执行效率,提高稳定性。如下图所示,落地Celeborn后,大盘机和小盘机的磁盘利用率均在55%左右,整体上均衡了集群磁盘利用率。

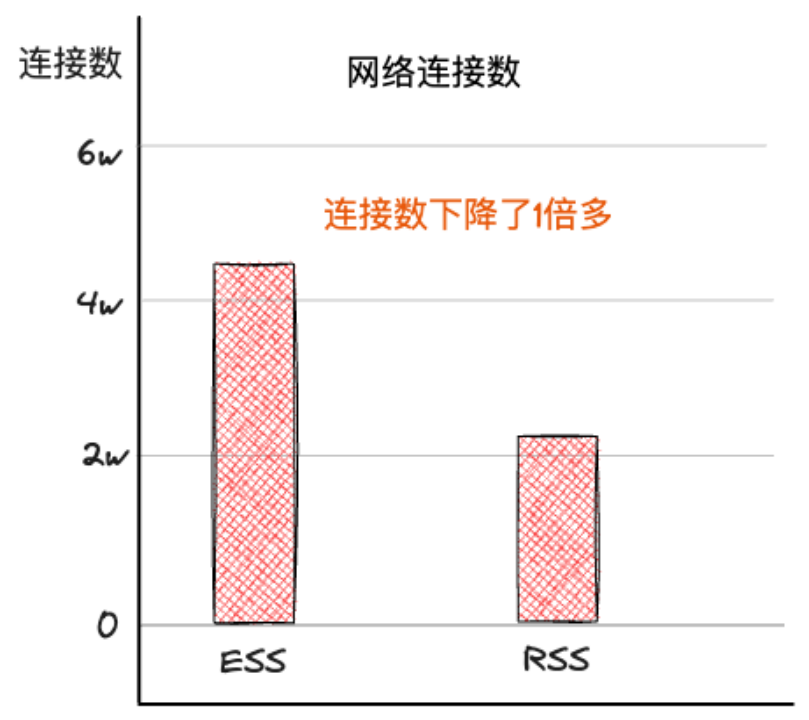
Celeborn的落地大幅降低机器间网络连接数的使用,落地前后,单台机器网络连接数从4万左右下降到2万左右,网络连接数下降一倍多,大大地节省了网络连接资源。如下图所示:

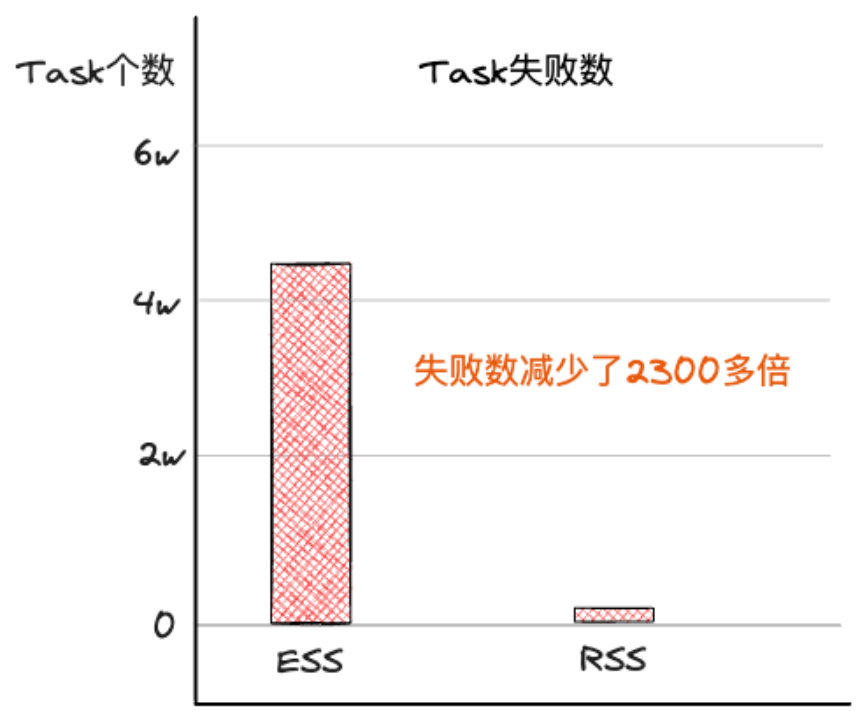
在ESS架构下,我们采集了RegisterExternalShuffle超时报错和FetchFailed报错,统计出总的Task失败数为4w6左右。接入celeborn后,我们采集Task Failed中关键字包含CelebornIOException的个数,统计出Task失败数下降到20左右,减少了2300多倍,效果是相当亮眼的。如下图所示:

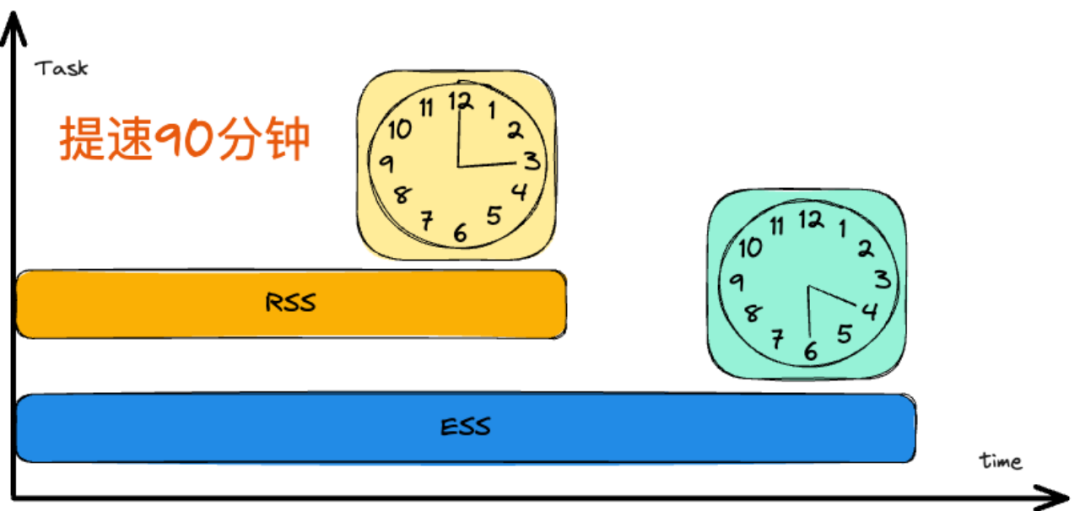
在使用ESS架构下,中通的核心宽表任务平均产出时间大概在4点30分左右,Celeborn上线之后,核心宽表提速90分钟以上,目前平均产出时间在3点左右,得到了数仓与业务方的高度认可与肯定。

Celeborn落地过程我们取得了很大的成果,整体上大大提升了spark中的shuffle执行效率、可靠性和稳定性。后续我们计划打造基于Celeborn的统一中间数据服务,逐步接入MR、FLINK。
同时我们也关注到了社区的一些新特性,例如,Memory Cache、Spark Stage重算等功能。未来,我们也计划逐步落地和实践。

在这里特别感谢Celeborn社区的 @一锤 @明济 @履霜等老师,在中通Celeborn落地的过程中,给予的大力技术支持。他们的专业知识和耐心指导为我们解决了许多问题。愿Celeborn社区蓬勃发展,不断壮大,为更多企业的成功发展贡献力量。

















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









