



进程线程讨论
个人认为,并发追求的就是多核的效率加成,所以python并发应当首选进程,但偶尔有场景进程无法适用,比如有些变量(函数方法,类,生成器,文件,锁和进程等)是无法序列化(转为josn或者pickle),就无法使用工具包manager()的工具类进行共享。如果自己实现新的共享方法,可能开发量较大,且质量难以保证。此时可考虑用线程处理,规避进程的变量共享难题,而且实际场景中,IO大概率都是瓶颈,所以使用线程其实也的确有些优势。个人而言,选择进程和线程较为重视的安全性,进程数据隔离较好,互不干扰。其次就是公用数据占比,如果大多数数据都需公用,那么线程也会比进程更佳,避免了进程较多的数据共享问题。
线程数据
线程而言,难点在于各种数据的一致性。下面在一个复杂点的情况下区别数据共享情况。
import threading
import time
gnum = 1
class MyThread(threading.Thread):
# 重写 构造方法
def __init__(self, num, num_list, sleepTime):
threading.Thread.__init__(self)#交由一个特定的线程完成初始化
self.num = num
self.sleepTime = sleepTime
self.num_list = num_list
def run(self):
time.sleep(self.sleepTime)
global gnum
gnum += self.num
self.num_list.append(self.num)
self.num += 1
print('(global)\tgnum 线程(%s) id:%s num=%d' % (self.name, id(gnum), gnum))
print('(self)\t\tnum 线程(%s) id:%s num=%d' % (self.name, id(self.num), self.num))
print('(self.list)\tnum_list 线程(%s) id:%s num=%s' % (self.name, id(self.num_list), self.num_list))
if __name__ == '__main__':
mutex = threading.Lock()
num_list = list(range(5))
t1 = MyThread(100, num_list, 1)
t1.start()
t2 = MyThread(200, num_list, 5)
t2.start()
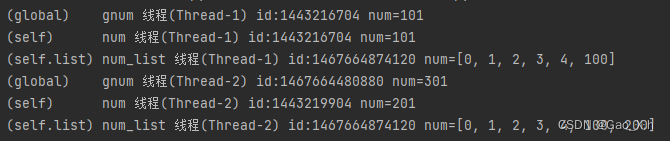
由global注明的gnum是共享的全局变量,每个类的self的num不共享,numlist因为是引用变量而共享。
共享数据的同步
最简单做法就是在凡是会在多个线程中修改的共享对象(变量),都加锁。这样可能会有部分锁多加了,但绝对好过不加,毕竟多加锁无非导致效率低下(也可能导致死锁),而一旦该加的没有加,则会导致数据错误。后者的影响明显更严重。
ThreadLocal变量
每一个线程可以使用自己环境进程中的全局变量。但如果一个线程修改了本进程的全局变量,会波及到本进程下的其他线程。为了避免多个线程同时对变量进行修改导致各种错误,引入了线程同步机制,通过互斥锁,条件变量或者读写锁来控制对全局变量的访问。
仅有进程的全局变量并不能满足多线程并发的本意,很多时候线程还需要私有数据,每个线程的私有数据对于其他线程来说都不可见。因此线程中也可以使用只有自己能访问的局部变量。
再给一个线程不安全的例子:
import threading
shared_value = 0
def increment():
global shared_value
for _ in range(1000000):
shared_value += 1
def decrement():
global shared_value
for _ in range(1000000):
shared_value -= 1
thread1 = threading.Thread(target=increment)
thread2 = threading.Thread(target=decrement)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("Final value:", shared_value)
答案就几乎是随机的,因为线程完全不知道会在字节码的哪一步被打断,然后读到脏数据。
python 线程库实现了 ThreadLocal 变量。ThreadLocal 真正做到了线程之间的数据隔离。
import threading
counter = threading.local()
def increment():
counter.value = 0
for _ in range(10000):
counter.value += 1
def worker():
increment()
print("Thread:", threading.current_thread().name, "Counter:", counter.value)
# 创建两个线程并启动
thread1 = threading.Thread(target=worker)
thread2 = threading.Thread(target=worker)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
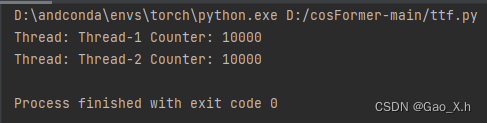
两个Counter都是计算各自的Counter,在实际使用时,Counter结果相加就行了。但是注意ThreadLocal对象的属性在线程结束后可能会被清除,导致无法访问。
import threading
# 创建ThreadLocal对象
my_data = threading.local()
def thread_add():
my_data.num = 0
for _ in range(1000):
my_data.num += 1
def thread_sub():
my_data.num = 1000
for _ in range(1000):
my_data.num -= 1
thread1 = threading.Thread(target=thread_add)
thread2 = threading.Thread(target=thread_sub)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(my_data.num)#结束线程后还试图访问数据
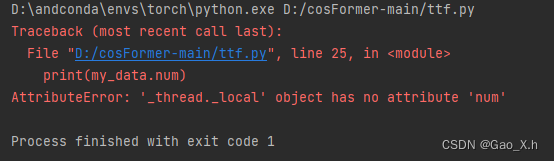
线程结束后就不存在my_data.num这个属性了。
阻塞
当一个线程执行 I/O 操作时,通常会发生阻塞,即线程暂时停止执行,等待 I/O 操作完成。在这种情况下,CPU 不会为阻塞的线程分配时间片。
当线程发起阻塞的 I/O 操作时,操作系统通常会将线程从可执行队列中移除,并将其状态设置为阻塞状态。CPU 不会浪费时间在等待 I/O 完成的线程上,而是将 CPU 时间片分配给其他可执行的线程,以提高系统的整体性能。 I/O 操作完成,操作系统会将线程的状态设置为就绪状态,然后将其重新放回可执行队列中,以便在下一个时间片中获得 CPU 的调度。
sleep()和wait()这两个函数被调用之后当前线程都应该放弃执行权,两者的区别主要在于sleep不会放弃锁,而wait会放弃锁。
因此在sleep() 阻塞期间,线程不会占用 CPU 但其他资源不会释放,等待时间过后,线程或进程会被重新激活并继续执行。sleep()函数本身就是time模块暂停执行的方法,和多线程没有直接联系。
在wait()等待期间,线程或进程不会占用 CPU和其他资源,故只有CPU和其他资源条件满足,它才会被重新激活并继续执行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









