







一、爬取目标
唯品会-(原Vipshop.com)特卖会:品牌特卖_确保正品_确保低价_货到付款
www.vip.com
二、爬取结果展示
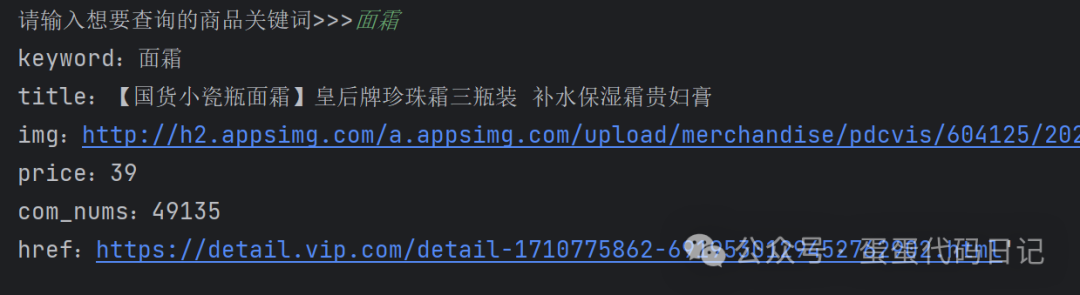
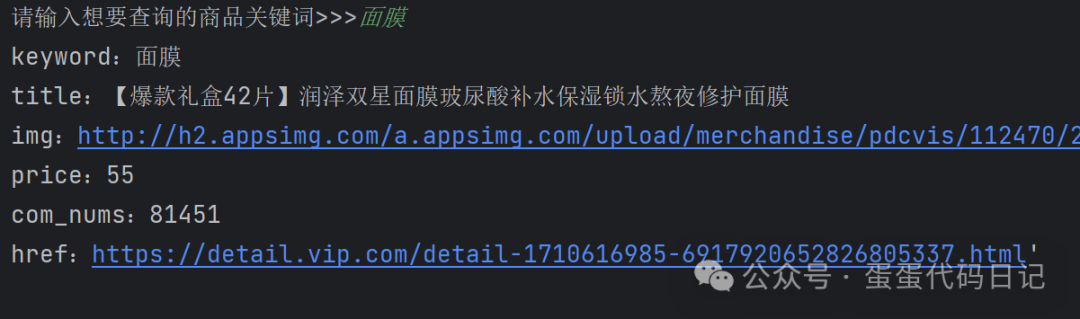
三、过程解析
我们先来到官网打开控制台输入关键字,这里搜索面膜简单看看
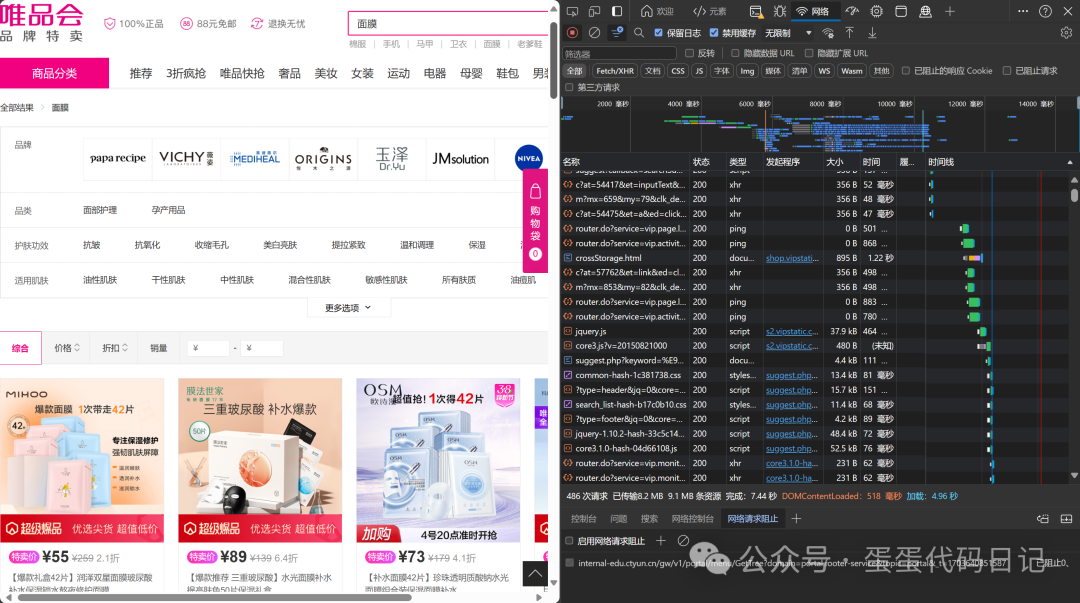
通过研究发现是先获取到相关的商品id,然后再用id去请求具体的商品信息在页面完成加载。这里先是getMerchandiseIds获取id
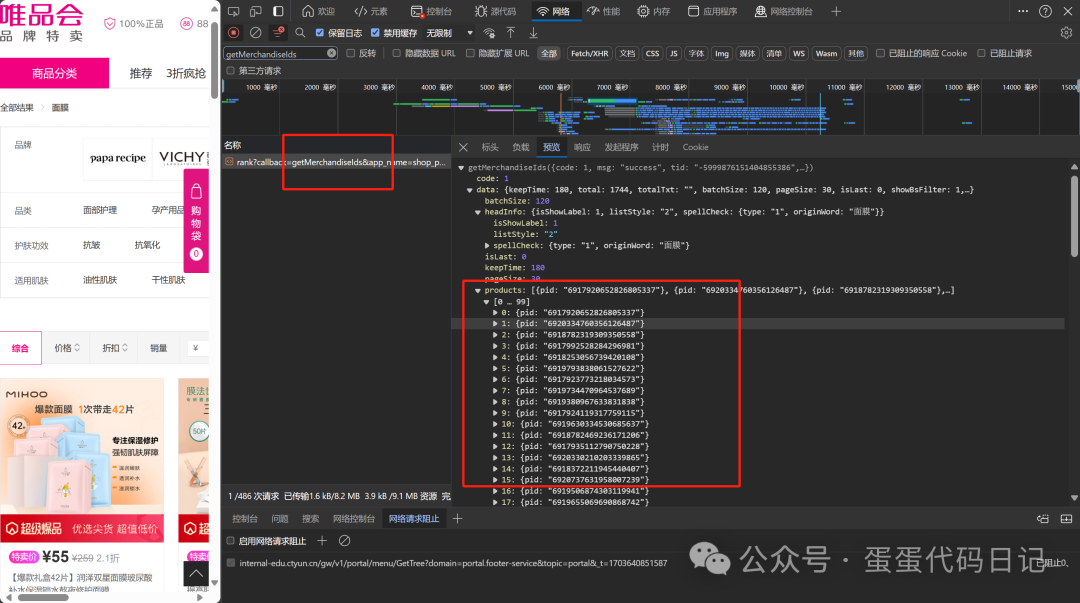
紧接着就是把这里的id数组拿到getMerchandiseDroplets1接口去请求具体的商品信息。
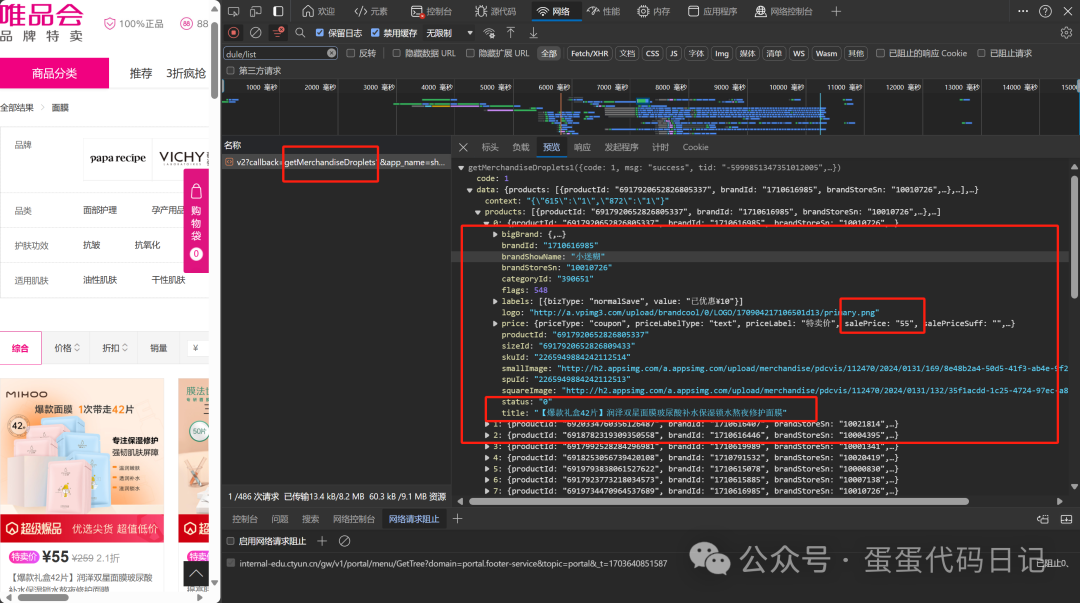
那么有了这个思路之后我们就可以开始写代码了,这里粘贴部分代码,那么有了这个思路 我们就可以很轻松的拿到商品信息数据,至于数据处理的部分 我相信不用我来说你也知道。
# 发起商品搜索请求,获取热门商品信息
for i in range(0, 1):
url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/search/product/rank?callback=getMerchandiseIds&app_name=shop_pc&app_version=4.0&warehouse=VIP_HZ&fdc_area_id=104101108&client=pc&mobile_platform=1&province_id=104101&api_key=70f71280d5d547b2a7bb370a529aeea1&user_id=&mars_cid=1628070214309_e7fbca2c43dda020cc7734c00466d49c&wap_consumer=a&standby_id=nature&keyword={}&lv3CatIds=&lv2CatIds=&orderId=6&lv1CatIds=&brandStoreSns=&props=&priceMin=&priceMax=&vipService=&sort=0&pageOffset={}&channelId=1&gPlatform=PC&batchSize=120&_=1628070503449'.format(
quote(keyword), 10 * i)
headers = {'referer': 'https://category.vip.com/', 'user-agent': 'Mozilla/5.0'}
html = requests.get(url, headers=headers)
start = html.text.find('{"code"')
json_data = json.loads(html.text[start:-1])['data']['products']
hot_product_id = json_data[0]['pid']
# 模拟浏览器请求
headers = {
# 防盗链 告诉服务器请求链接地址从哪里跳转过来
"Referer": "https://category.vip.com/",
# 用户代理 浏览器基本身份信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
# 请求链接
url = 'https://mapi.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2?'
# 请求参数
data = {
# "callback": "getMerchandiseDroplets1", # 回调函数 获取requests.json()错误,将其省略
"app_name": "shop_pc",
"app_version": "4.0",
"warehouse": "VIP_HZ",
'fdc_area_id': "104103105",
"client": "pc",
'mobile_platform': "1",
"province_id": "104103",
"api_key": "70f71280d5d547b2a7bb370a529aeea1",
"user_id": "",
"mars_cid": "1709020224623_93efa75c9405a664404d2796c42f476e",
"wap_consumer": "a",
"productIds": hot_product_id,
"scene": "search",
"standby_id": "nature",
"context": "",
"_": "1689389675519",
}
# 发送请求
requeston = requests.get(url=url, params=data, headers=headers).text
# 假设 requeston 是你的 JSON 字符串
response_data = json.loads(requeston)# 获取 'data' 下的 'products' 列表
products = response_data['data']['products']
四、源码获取
编码不易,请支持原创!
本案例完整爬虫源码及结果文件,关注后回复 唯品会 可全部免费获取↓
获取后,有任何代码问题请留言!
任何疑问可以直接后台留言,蛋蛋会及时回复

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









