







 本文提出了一种名为Iterlogic-E的新颖知识图谱完成方法,结合规则推理和嵌入学习,通过迭代过程优化知识图谱并处理不确定性。文章介绍了规则挖掘、推理和嵌入学习的详细过程,实验证明了Iterlogic-E在链接预测任务中的优越性能和可解释性。
本文提出了一种名为Iterlogic-E的新颖知识图谱完成方法,结合规则推理和嵌入学习,通过迭代过程优化知识图谱并处理不确定性。文章介绍了规则挖掘、推理和嵌入学习的详细过程,实验证明了Iterlogic-E在链接预测任务中的优越性能和可解释性。

KGC的方法及问题
KGC的方法可以分为两大类:基于规则的推理(使用显式推理规则)和基于嵌入的推理(基于表示学习而不是直接建模规则)。
基于规则的推理:通过归纳学习获得推理规则,然后演绎推理出新的事实,具有较高的准确性和良好的可解释性,但一个主要挑战是在大规模知识图谱上获得有效的规则,而且,在很多情况下,逻辑规则可能是不完善的,甚至是自相矛盾的。因此,有效地模拟(软)逻辑规则的不确定性至关重要。
基于嵌入的推理:将实体和关系嵌入到连续的低维空间中,这些嵌入保留了实体和关系的语义,可用于预测丢失的三元组。此外,它们可以使用随机梯度下降进行有效训练。旨在学习实体和关系的分布式嵌入并在数值空间中进行泛化,具有良好的效率和可扩展性,但严重依赖于数据的丰富性,无法以逻辑规则的形式充分利用领域知识。因此这些方法很难对稀疏实体学习表示。
主要贡献
• 提出了一种新颖的KGC方法Iterlogic-E,它在KGE框架中联合建模逻辑规则和KG。Iterlogic-E结合了规则和嵌入在知识推理中的优点。Iterlogic-E将结论标签建模为 0-1 变量,并使用置信度正则化器消除不确定的结论。
• 提出了一种新颖的迭代学习范式,可以在效率和可扩展性之间实现良好的平衡。 Iterlogic-E不仅使KG更加密集,还可以过滤错误的结论。
• 与传统推理方法相比,Iterlogic-E 在确定结论时更具可解释性。它不仅知道结论为什么成立,而且知道哪个是真的,哪个是假的。
• 我们通过多个基准数据集上的链接预测任务对 Iterlogic-E 进行实证评估。实验结果表明,Iterlogic-E 可以在多个评估指标上取得最先进的结果。定性分析证明Iterlogic-E对于不同置信水平的规则具有更强的鲁棒性。
提出的方法
本文提出了一种新颖的方法 Iterlogic-E(Iterative using logic rule for reasoning and learning Embedding,迭代使用逻辑规则进行推理和学习嵌入),可以迭代地注入规则并且学习表示,以充分利用规则和嵌入。具体来说,就是将规则基础的结论建模为 0-1 变量,并使用规则置信正则化器来消除结论的不确定性。所提出的方法具有以下优点:1)它结合了规则和知识图谱嵌入(KGE)的优点,并在效率和可扩展性之间实现了良好的平衡。 2)它采用迭代的方法不断改进KGE并且去除不正确的规则结论。
- 在这里,规则基础的结论通常指的是基于某些规则或逻辑推导出的结论。
- 将这些结论建模为0-1变量意味着,每个结论要么为真(用1表示),要么为假(用0表示)。在机器学习的上下文中,这通常是为了便于模型处理,将离散的结果转换为数值形式。
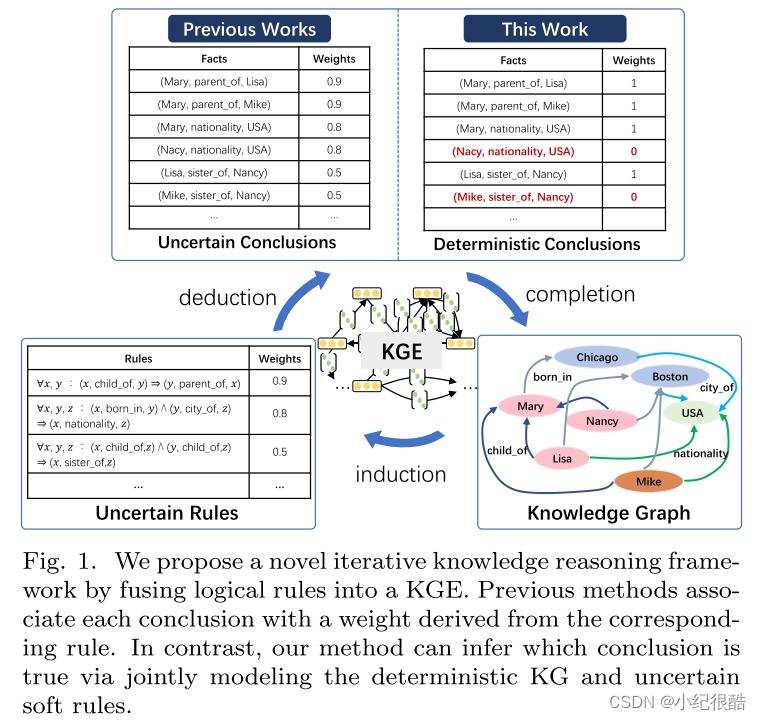
我们通过将逻辑规则融合到 KGE 中,提出了一种新颖的迭代知识推理框架。以前的方法将每个结论与从相应规则得出的权重相关联。相比之下,我们的方法可以通过对确定性知识图谱和不确定性软规则进行联合建模来推断哪
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









