







学习参考视频:尚硅谷大数据Hadoop 3.x(入门搭建+安装调优)
Hadoop入门
hadoop概述
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
hadoop优势
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处 理速度。
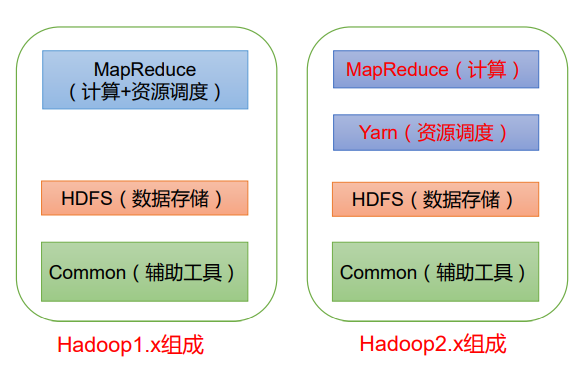
hadoop构成
在 Hadoop1.x 时 代 , Hadoop中 的MapReduce同 时处理业务逻辑运算和资 源的调度,耦合性较大。
在Hadoop2.x时 代,增 加 了Yarn。Yarn只负责 资 源 的 调 度 , MapReduce 只负责运算。
Hadoop3.x在组成上没有变化。
HDFS架构(分布式文件系统)
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
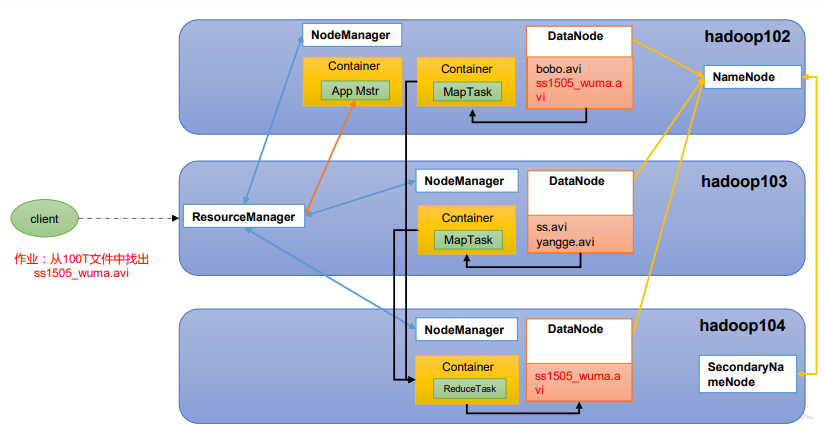
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、 文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件的块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
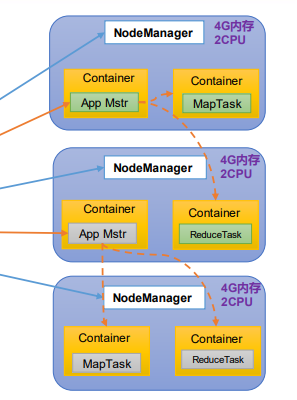
YARN架构(资源管理器)
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
2)NodeManager(N M):单个节点服务器资源老大
3)ApplicationMaster(AM):单个任务运行的老大
4)Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
Mapreduce架构
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对 Map 结果进行汇总
HDFS YARN Mapreduce三者关系
大数据技术生态体系
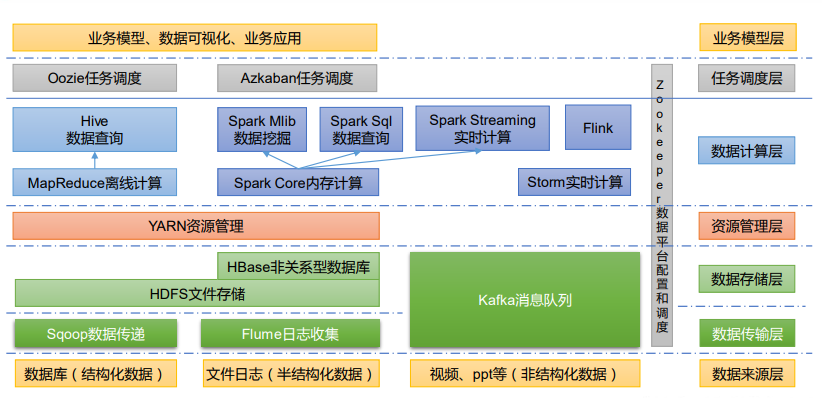
1)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL) 间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进 到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数 据进行计算。
5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运 行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开 发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、 名字服务、分布式同步、组服务等。
Hadoop运行环境搭建注意点
安装linux桌面标准版!!!
详细搭建步骤 参考视频:尚硅谷大数据Hadoop 3.x(入门搭建+安装调优) P18-38
为什么安装epel-release
安装 epel-release:Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包, 适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方 repository 中是找不到的)
yum install -y epel-release
为什么关闭防火墙
定义:所谓防火墙指的是一个由软件和硬件设备组合而成、在内部网和外部网之间、专用网与公共网之间的界面上构造的保护屏障.是一种获取安全性方法的形象说法,它是一种计算机硬件和软件的结合,使Internet与Intranet之间建立起一个安全网关。
有时候,在虚拟机上面开了服务,在外面访问不到,本机一切都正常,这时就应该想到防火墙。因为不清楚该放行什么端口,有些规则会阻止某些访问,很可能造成各种外部的连接不成功,比如ftp啊telnet,ssh。
所以索性在学习阶段关上防火墙。在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安 全的防火墙。
CentOS 7.0默认使用的是firewall作为防火墙。
systemctl stop firewalld ##停止firewall
systemctl disable firewalld.service ##禁止firewall开机启动
为什么要sudoers配置用户具有root权限
有关linux用户组参考视频:【小白入门 通俗易懂】2021韩顺平 一周学会Linux-P23
有关linux中su和sudo区别:slgkaifa-linux权限之su和sudo的差别
单纯使用su切换到root,读取变量的方式是non-login shell,这样的方式下非常多的变量都不会改变,这样的方式仅仅是切换到root的身份。而用su -这样的方式的话,是login shell方式,它是先以root身份登录然后再运行别的操作。
相比于su切换身份须要用户的password,常常性的是须要rootpassword,sudo仅仅是须要自己的password,就能够以其它用户的身份来运行命令,常常是以root的身份运行命令,所以sudo能够保护目标用户的password不外流的。也并不是全部人都能够用sudo:所以sudo是依赖于/etc/sudoers这个配置文件的。
- 当帮root管理系统的时候,su是直接将root全部权利交给用户。
- 而sudo能够更好分工,仅仅要配置好/etc/sudoers,这样sudo能够保护系统更安全,并且分工明白,有条不紊。
为什么要设置主机映射关系
详细请参考:为什么要配置hosts-风飘舞雪
用记事本打开hosts文件,它的作用是包含IP地址和Host name(主机名)的映射关系,是一个映射IP地址和Hostname(主机名)的规定,规定要求每段只能包括一个映射关系,IP地址要放在每段的最前面,空格后再写上映射的Host name(主机名)。对于这段的映射说明用“#”分割后用文字说明。
Hosts在Windows中是怎么工作的。
我们知道在网络上访问网站,要首先通过DNS服务器把网络域名((www.XXXX.com)解析成61.XXX.XXX.XXX的IP地址后,我们的计算机才能访问。要是对于每个域名请求我们都要等待域名服务器解析后返回IP信息,这样访问网络的效率就会降低,而Hosts文件就能提高解析效率。根据 Windows系统规定,在进行DNS请求以前,Windows系统会先检查自己的Hosts文件中是否有这个地址映射关系,如果有则调用这个IP地址映射,如果没有再向已知的DNS 服务器提出域名解析。也就是说Hosts的请求级别比DNS高。
scp安全拷贝和rsync远程同步工具区别
scp 可以实现服务器与服务器之间的数据拷贝。
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更 新。scp 是把所有文件都复制过去。
有关加密方式
对称秘钥加密∶客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密"这种方式存在安全隐惠。
非对称秘钥加密:“非对称加密"使用的时候有两把锁,一把叫做“私有密钥",一把是"公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。(SSH采用的就是非对称密钥加密)
证书秘钥加密:非对称加密很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起。服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。(https即http over ssl采用的就是证书密钥加密)
各端口
namenode的web端访问端口9870,内部通信端口8020
2namenod的web端访问端口9868
yarn的resourcemanager,查看执行任务端口的web访问端口8088
hadoop历史服务器jobhistory的web访问端口19888,内部通信端口10020
为什么要集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期 和公网时间进行校准;如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差, 导致集群执行任务时间不同步。
Hadoop启动步骤
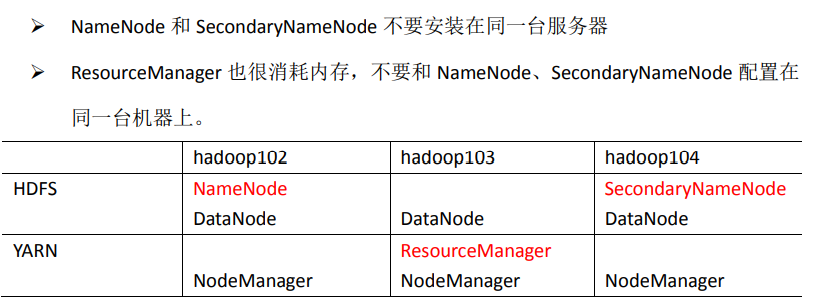
| tjyedu01 | tjyedu02 | tjyedu03 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
在tjyedu01上启动hdfs在/opt/module/hadoop-3.1.3下 :sbin/start-hdfs.sh
在tjyedu02上启动yarn在/opt/module/hadoop-3.1.3下:sbin/start-yarn.sh
在tjyedu01启动历史服务器/opt/module/hadoop-3.1.3/etc/hadoop/bin目录下:mapred --daemon start historyserver

















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









