




5、Redis数据类型你用过哪些?底层的数据结构?实际场景使用哪些数据结构?
8、二叉树、BST二叉查找(搜索)树、平衡二叉查找树AVL?
14、设计模式学过吗?结合项目,你的项目用到了哪些设计模式?
18、解释double类型计算为什么得不到精确结果?修改代码,使得得到精确结果(BigDecimal数据类型、字符串存储)
1、自我介绍
2、项目经历
-
技术难题:回答了线程池+消息队列相关的
-
JDK自带的创建线程池的方式
1.newFixedThreadPool
这个线程池的特别是线程数是固定的
2.newSingleThreadExecutor
这个线程池看名字就知道是单例线程池,线程池中只有一个工作线程在处理任务
3.newCachedThreadPool
当第一次提交任务到线程池时,会直接构建一个工作线程,
这个工作线程带执行完任务后,60秒没有任务可以执行后,会结束,
如果在等待60秒期间有任务进来,他会再次拿到这个任务去执行,
如果后续提升任务时,没有线程是空闲的,那么就构建工作线程去执行。
4. newScheduleThreadPool
这个线程池就是可以以一定周期去执行一个任务,或者是延迟多久执行一个任务一次。
本质上还是正常线程池,只不过在原来的线程池基础上实现了定时任务的功能原理是基于DelayQueue实现的延迟执行。
5.newWorkStealingPool
newWorkStealingPool是基于ForkJoinPool构建出来的。每个线程都有阻塞队列。
ForkJoin第一个特点是可以将一个大任务拆分成多个小任务,放到当前线程的阻塞队列中。其他的空闲线程就可以去处理有任务的线程中阻塞队列中的任务。
-
线程池用的Spring的还是Java自带的?区别?
Spring官方文档中写的很清楚,SpringFrameWork 的 ThreadPoolTaskExecutor 是辅助 JDK 的 ThreadPoolExecutor 的工具类,它将属性通过 JavaBeans 的命名规则提供出来,方便进行配置。
Spring中的ThreadPoolTaskExecutor是借助于JDK并发包中的java.util.concurrent.ThreadPoolExecutor来实现的。
ThreadPoolExecutor构造函数:
public ThreadPoolExecutor(int corePoolSize, //线程池维护线程的最小数量 int maximumPoolSize, //线程池维护线程的最大数量 long keepAliveTime, //空闲线程的存活时间 TimeUnit unit, //时间单位,现有微秒,毫秒,秒 枚举值 BlockingQueue<Runnable> workQueue, //持有等待执行的任务队列 ThreadFactory threadFactory, //线程工厂 RejectedExecutionHandler handler//拒绝策略四种 ) { ...}
-
底层的核心线程数、队列线程数、最大线程数怎么设置的?
如何确定核心线程数?
在设置核心线程数之前,需要先考虑线程池执行任务的类型
IO密集型任务
一般来说:文件读写、DB读写、网络请求等
推荐:假设N为计算机的CPU核数,核心线程数大小设置为2N+1
优点:可以让在等待IO的时候,有其他线程去处理别的任务,充分利用CPU的时间。
CPU密集型任务
一般来说:计算型代码、Bitmap转换、Gson转换等
推荐:假设N为计算机的CPU核数,核心线程数大小设置为N+1
缺点:使得CPU的使用率很高,若线程数过多,造成CPU过度切换
在实际的项目中,都是通过测试的方法调试出符合当前任务情况的核心参数,充分利用硬件资源,同时也要考虑到一个服务器上有多个项目。可以实现一个controller接口,通过线程池的get和set方法修改核心参数,实现动态的监控。
参考回答:
① 高并发、任务执行时间短 -->( CPU核数+1 ),减少线程上下文的切换
② 并发不高、任务执行时间长
IO密集型的任务 --> (CPU核数 * 2 + 1)
计算密集型任务 --> ( CPU核数+1 )
③ 并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,可以参考②
-
线程池怎么工作的?
ThreadPoolExecutor执行器的处理流程:
(1)当线程池大小小于corePoolSize就新建线程,并处理请求;
(2)当线程池大小等于corePoolSize,把请求放入workQueue中,池子里的空闲线程就去从workQueue中取任务并处理;
(3)当workQueue放不下新入的任务时,新建线程加入线程池,并处理请求,如果池子大小撑到了maximumPoolSize就用RejectedExecutionHandler来做拒绝处理.
(4)另外,当线程池的线程数大于corePoolSize的时候,多余的线程会等待keepAliveTime长的时间,如果无请求处理任务就自行销毁。
-
拒绝策略?
RejectedExecutionHandler handler: 用来拒绝一个任务的执行,有两种情况会发生这种情况。 一是在execute方法中若addIfUnderMaximumPoolSize(command)为false,即线程池已经饱和; 二是在execute方法中, 发现runState!=RUNNING || poolSize == 0,即已经shutdown,就调用ensureQueuedTaskHandled(Runnable command),在该方法中有可能调用reject。
Reject策略预定义有四种:
1.AbortPolicy:是默认的策略,当前拒绝策略会在无法处理任务时,直接抛出一个异常。
使用场景:你想要提示一些信息的时候
2.CallerRunsPolicy:当前拒绝策略会在线程池无法处理任务时,将任务交给调用者处理。
使用场景:一般在不允许失败的、对性能要求不高、并发量较小的场景下使用
3.DiscardPolicy:当前拒绝策略会在线程池无法处理任务时,直接将任务丢弃掉。
使用场景:如果你提交的任务无关紧要,你就可以使用它 。
4.DiscardOldestPolicy:当前拒绝策略会在线程池无法处理任务时,将队列中头部最早的任务丢弃掉,将当前任务再次尝试交给线程池处理(如果再次失败,则重复此过程)。
使用场景:发布消息和修改消息,当消息发布出去后,还未执行,此时更新的消息又来了,这个时候未执行的消息的版本比现在提交的消息版本要低就可以被丢弃了
3、动态规划可以解决哪些问题?实际应用场景?
回答了买卖股票的最佳时机
动态规划思想就是:通过将问题分解为更小的子问题并存储子问题的解,动态规划可以避免重复计算,提高算法的效率。 实际应用场景:包括爬楼梯、背包问题、最短路径问题、排班问题等
动态规划算法最重要的就是去定义这个状态转移方程:
比如爬楼梯问题的递推公式:dp (n) = dp (n-1) + dp (n-2)
动态规划算法与分治算法相似,都是通过组合子问题的解来求解原问题的解。但是两者之间也有很大区别:分治法将问题划分为互不相交的子问题,递归的求解子问题,再将他们的解组合起来求解原问题的解;与之相反,动态规划应用于子问题相互重叠的情况,在这种情况下,分治法还是会做很多重复的不必要的工作,他会反复求解那些公共的子问题,而动态规划算法则对相同的每个子问题只会求解一次,将其结果保存起来,避免一些不必要的计算工作。
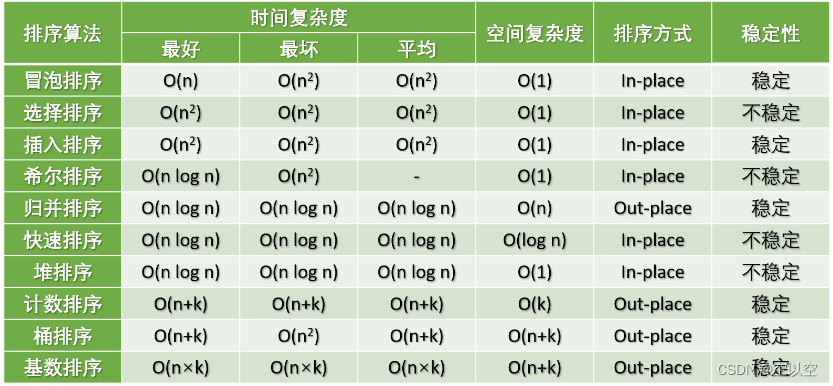
4、排序算法?时间复杂度?实际应用中使用过排序算法吗?
实际应用场景?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2879
2879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









