







 文章介绍了MaxPool2d的最大池化操作,包括参数如kernel_size、stride和ceil_mode,并通过代码示例展示其应用。同时提到了池化层在减少数据量、提高计算效率以及特征提取中的作用。还展示了如何在CIFAR10数据集上使用最大池化。
文章介绍了MaxPool2d的最大池化操作,包括参数如kernel_size、stride和ceil_mode,并通过代码示例展示其应用。同时提到了池化层在减少数据量、提高计算效率以及特征提取中的作用。还展示了如何在CIFAR10数据集上使用最大池化。
- MaxPool:最大池化(下采样)
- MaxUnpool:上采样
- AvgPool:平均池化
- AdaptiveMaxPool2d:自适应最大池化
1 关于池化操作
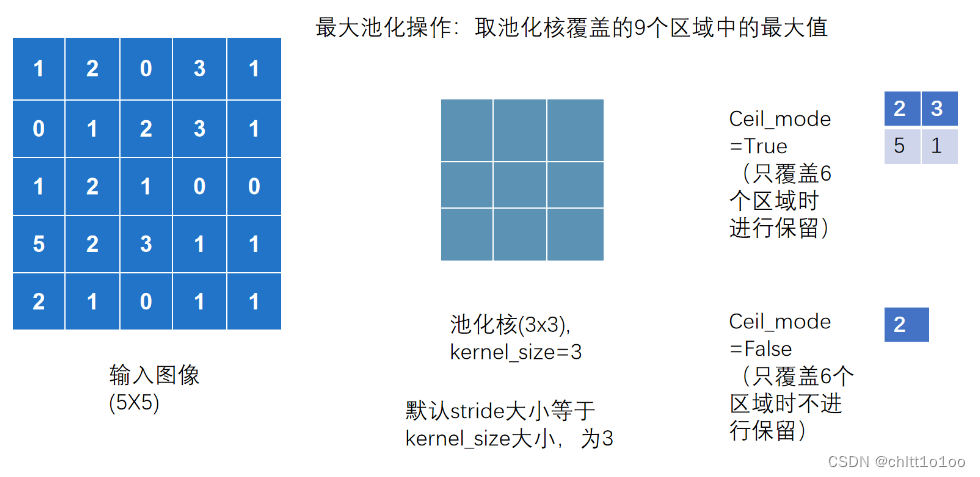
2 MaxPool2d


- kernel_size:池化核
- stride:步进。卷积层中的stride默认为1,池化层中的stride默认为kernel_size的大小
- padding
- dilation:空洞卷积
- return_indices
- ceil_mode:值为True时使用ceil模式,否则为floor模式

上图实现最大池化:
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) #最大池化无法对long数据类型进行实现,将input变成浮点数的tensor数据类型
input = torch.reshape(input,(-1,1,5,5)) #-1表示torch计算batch_size
print(input.shape)
# 搭建神经网络
class myNN(nn.Module):
def __init__(self):
super(myNN, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
# 创建神经网络
mynn = myNN()
output = mynn(input)
print(output) 
用数据集 CIFAR10 实现最大池化:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./datasets",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class myNN(nn.Module):
def __init__(self):
super(myNN, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
mynn = myNN()
writer = SummaryWriter("log4")
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = mynn(imgs) # output尺寸池化后不会有多个channel,原来是3维的图片,经过最大池化后还是3维的,不需要像卷积一样还要reshape操作(影响通道数的是卷积核个数)
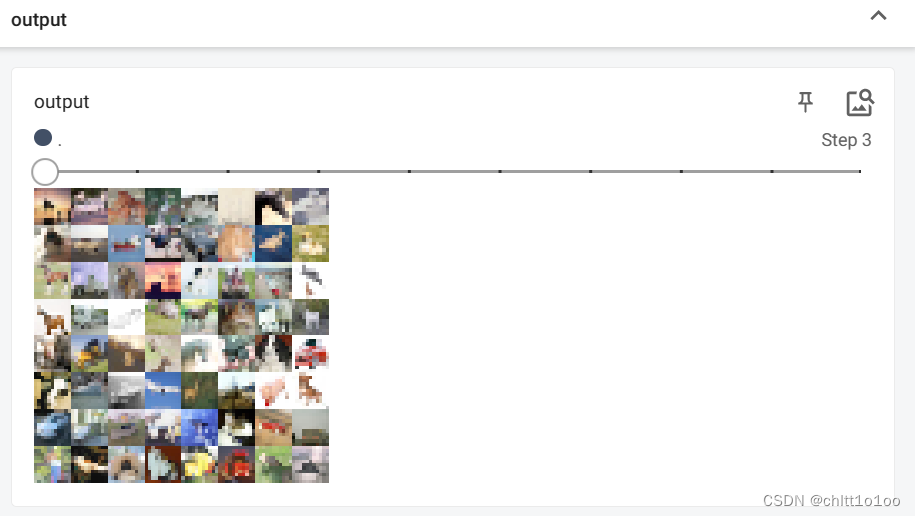
writer.add_images("output",output,step)
step += 1
writer.close()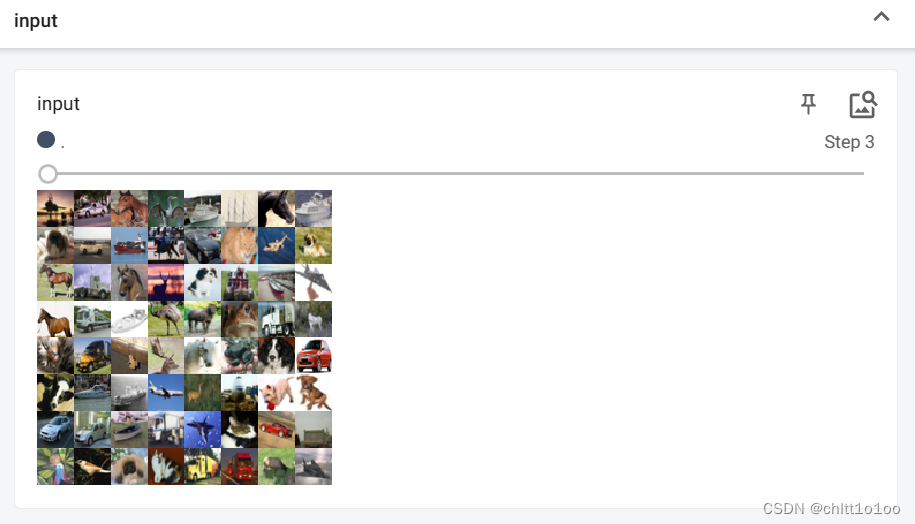
3 池化层的作用
最大池化的目的是保留输入的特征,同时把数据量减小(数据维度变小),对于整个网络来说,进行计算的参数变少,会训练地更快。如上面案例中输入是5x5的,但输出是3x3的,甚至可以是1x1的。类比1080p的视频为输入图像,经过池化可以得到720p,也能满足绝大多数需求,传达视频内容的同时,文件尺寸会大大缩小。
池化一般跟在卷积后,卷积层是用来提取特征的,一般有相应特征的位置是比较大的数字,最大池化可以提取出这一部分有相应特征的信息。
池化不影响通道数,池化后一般再进行非线性激活。

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









