






 渲染管线是实时渲染的核心,包括应用阶段、几何阶段、光栅化阶段和后处理。CPU负责设置场景数据、剔除不可见物体和复杂计算,如物理解算。GPU擅长并行计算,处理顶点着色、片元着色等大量计算任务。渲染管线利用GPU的并行处理能力加速渲染过程,提高效率。
渲染管线是实时渲染的核心,包括应用阶段、几何阶段、光栅化阶段和后处理。CPU负责设置场景数据、剔除不可见物体和复杂计算,如物理解算。GPU擅长并行计算,处理顶点着色、片元着色等大量计算任务。渲染管线利用GPU的并行处理能力加速渲染过程,提高效率。
1 什么是渲染管线
图形渲染管线是实时渲染的核心组件。通过给定虚拟相机、3D场景物体以及光源等场景要素来产生或者渲染一副2D的图像来显示在屏幕上。
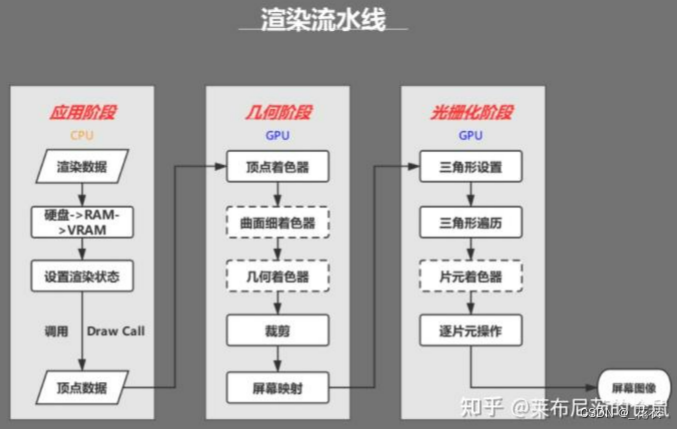
(渲染管线并非严格如图划分和命名,不同的教材划分方法不同如《Fundamentals of Computer Graphics 4th》与《Real-Time Rendering》划分便不一致,同时OpenGL与DirectX两大图形接口的描述也不太一致,但是基础原理相同,具体功能差异不大。)
应用阶段
该阶段由顶层表现为操作者来设置(操作者指渲染人员或游戏玩家等想要获得所需画面的计算机控制者),该部分底层上由CPU负责完成。
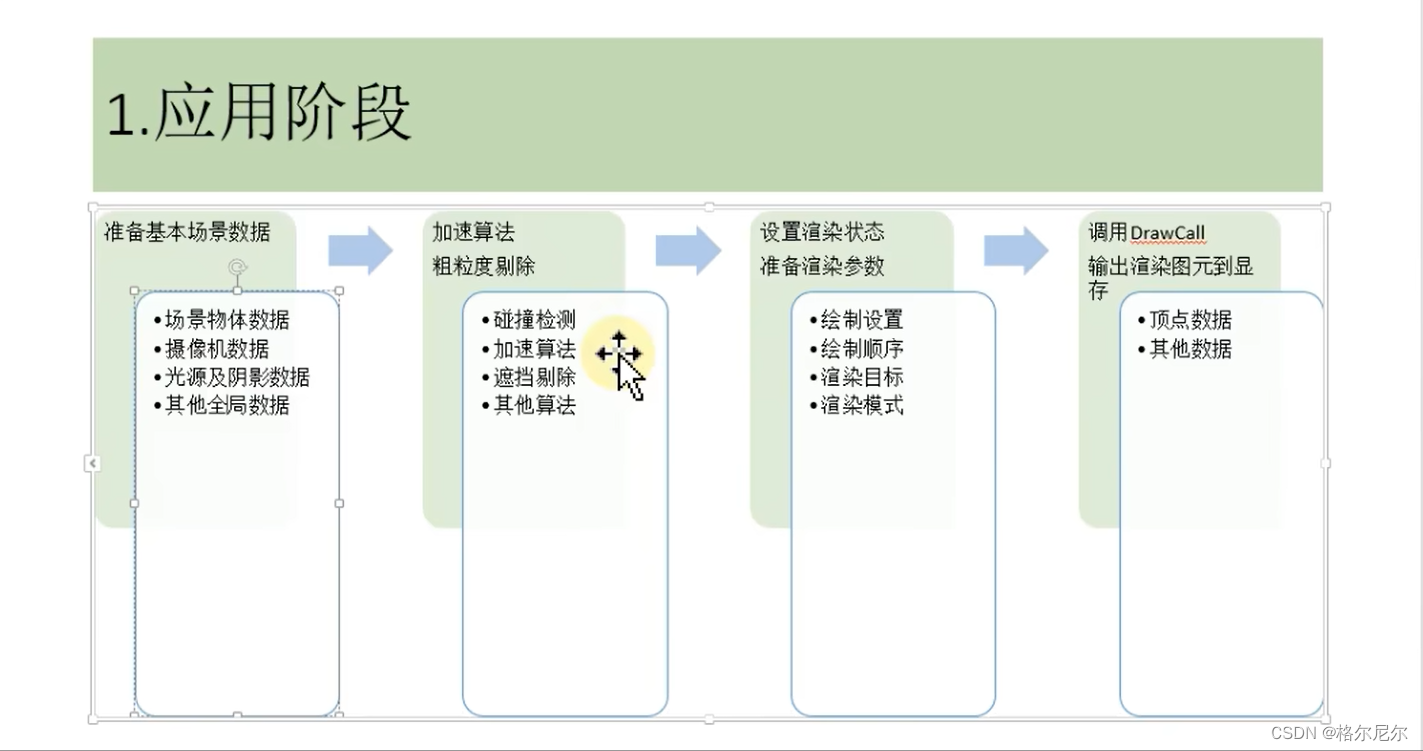
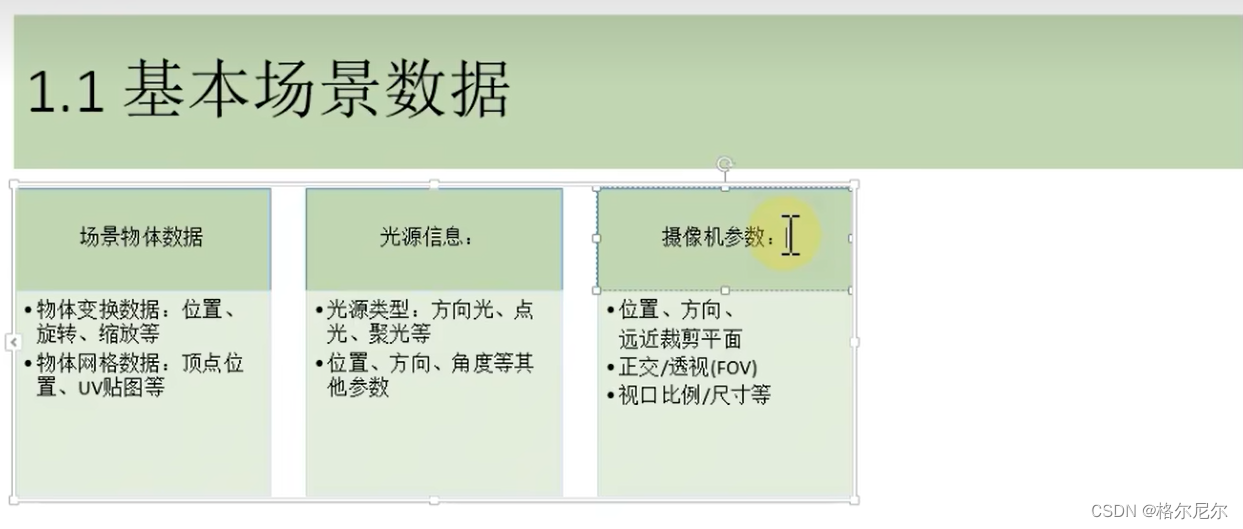
准备场景数据,例如摄像机的位置、视锥体、场景中包含了哪些模型、使用了哪些光源等等;
粗粒度剔除工作,把那些不可见的物体剔除出去,这样就不需要再移交给几何阶段进行处理;
设置渲染状态,包括但不限于使用的材质属性(漫反射颜色、高光反射颜色)、使用的纹理、使用的Shader,是否透明等;
物理解算部分(如布料解算、人物碰撞、水体模拟等等)由于其复杂的计算难度,也由CPU完成;
粗粒度剔除:包含视锥体剔除(Frustum Culling)和遮挡剔除( Occlusion Culling),减少无用的数据,避免后续 无效的计算。
视锥体剔除 (Frustum Culling) 只禁用相机视野外的对象渲染,不禁用视野中被遮挡的任何物体的渲染,在物体层面上对AABB或OBB做处理,剔除在视锥体外的物体运算量较低精度也较低。
遮挡剔除:遮挡剔除 (Occlusion Culling) 功能是在对象因被其他物体遮挡,当前在相机中无法看到时,禁用对象渲染。该功能一般不会在三维计算机图形中自动开启,因为在大部分情况下,离相机最远的对象最先渲染,离相机近的对象覆盖先前的物体(该步骤称之为“重复渲染 (overdraw)”)。透明物体慎重考虑。
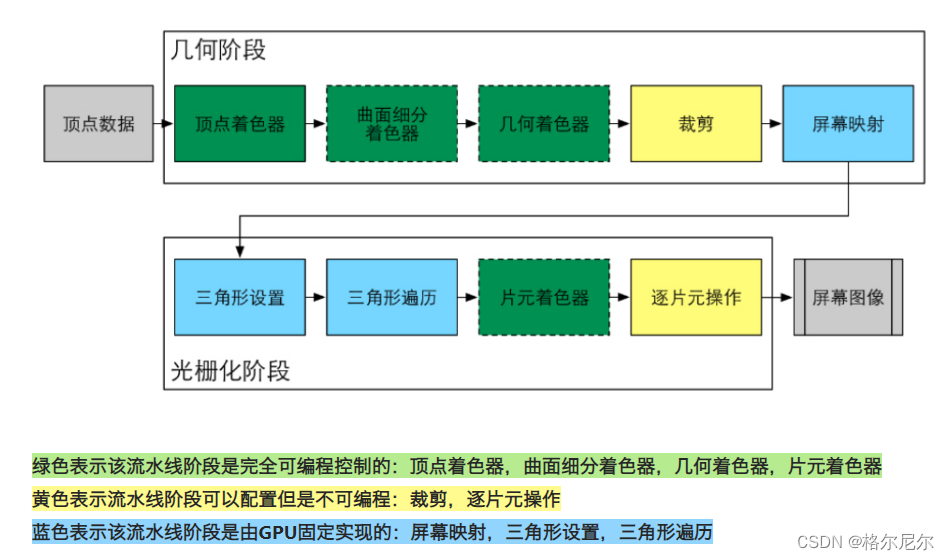
渲染管线的一个特点就是每个阶段都会把前一个阶段的输出作为该阶段的输入,就像工厂的流水线一样。
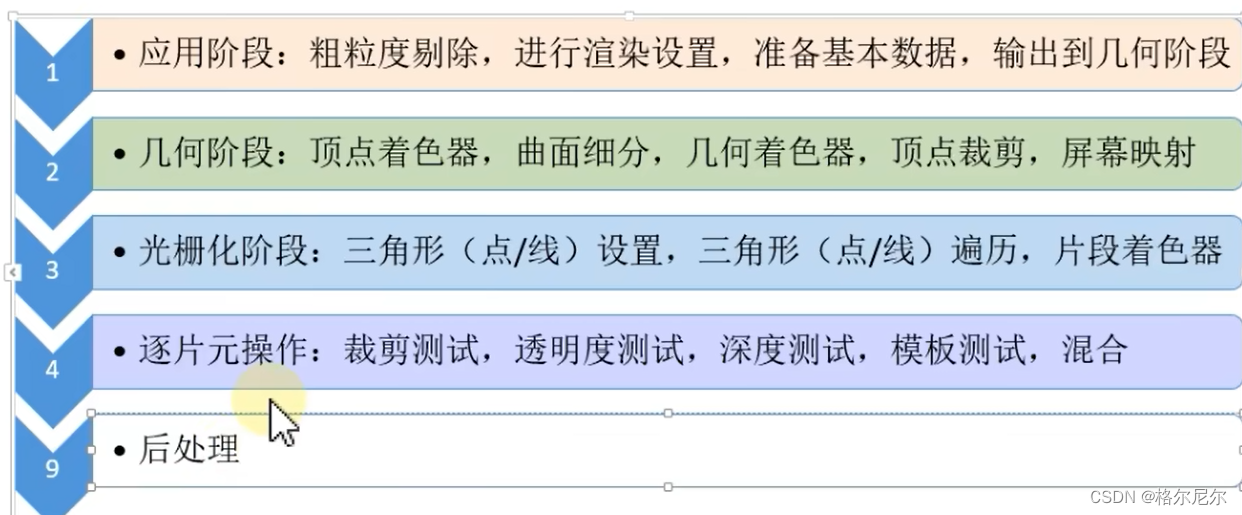
粗粒度剔除:根据物体之间的遮挡关系,剔除遮挡的物体。
多顶点分配到GPU不同单元执行,提升速度
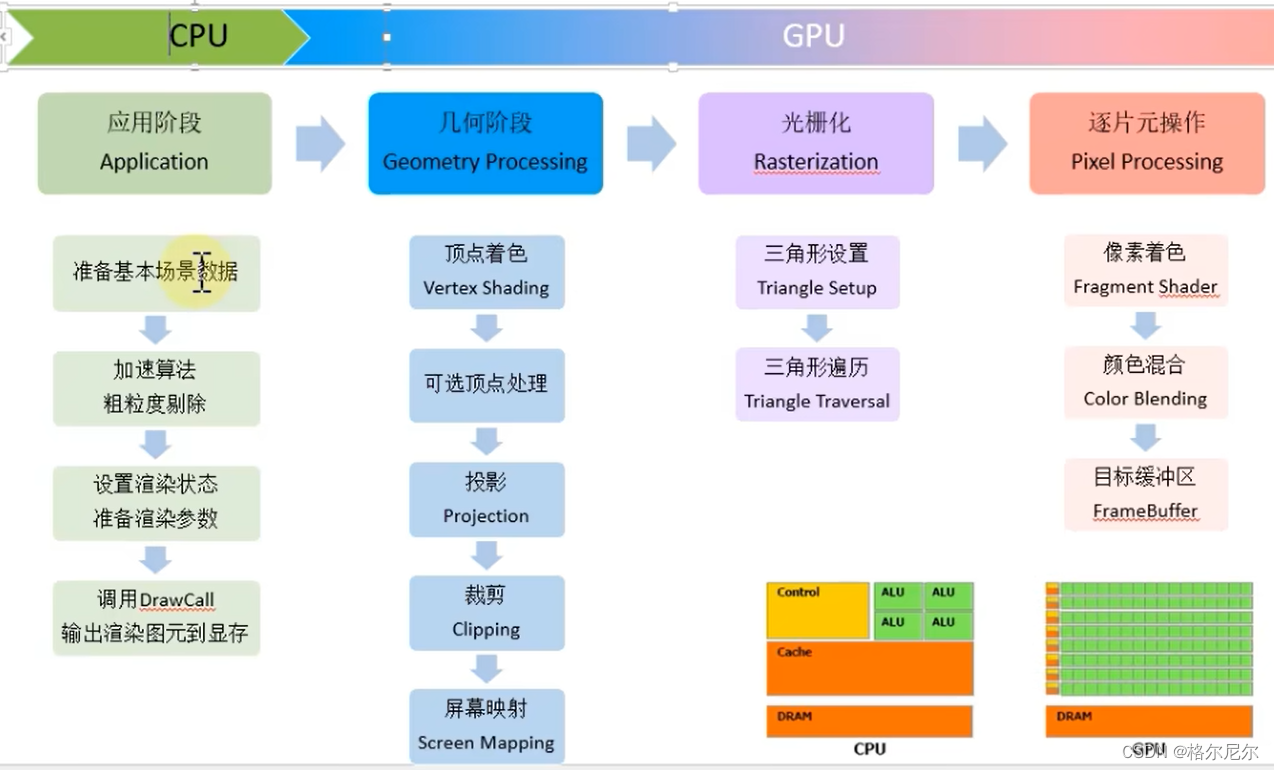
1 应用阶段
1.1 场景阶段
### 1.2 粗粒度剔除

剔除与摄像机与视锥体不相交的光源或者光线照射方向与与视角不重合的光源。
1.3 渲染设置

1.4 调用call draw

2 几何阶段
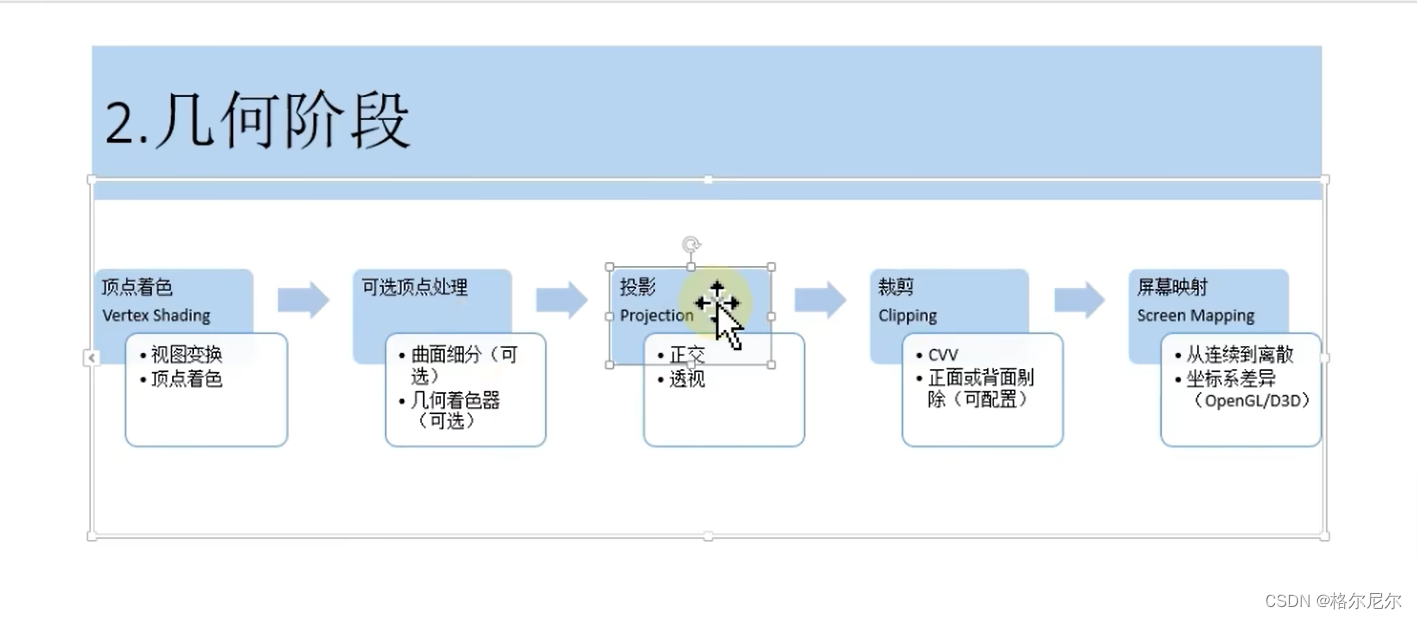
2.1 顶点着色器
投影变换:3D投影2D画面
第三步:MVP变换矩阵
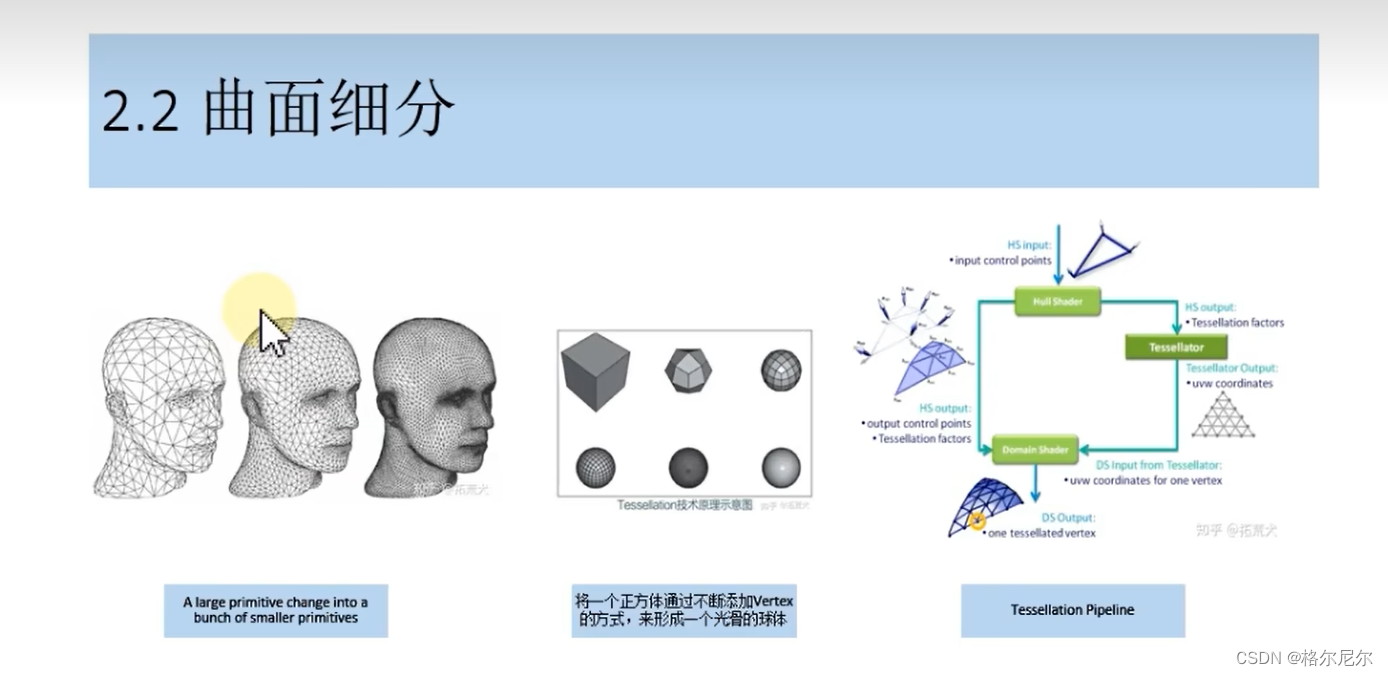
2.2 曲面细分着色器(插值计算) 几何着色器

2.3 投影
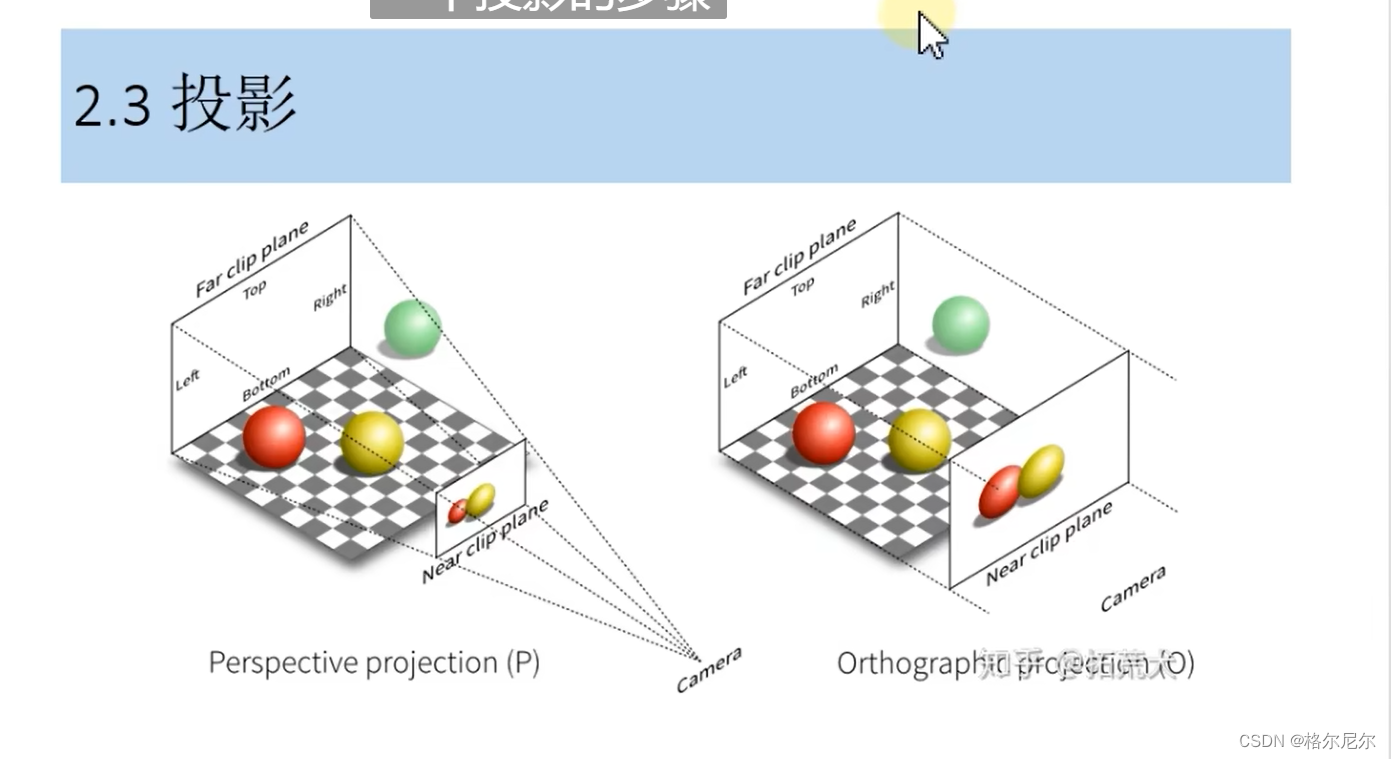
2.4 裁剪
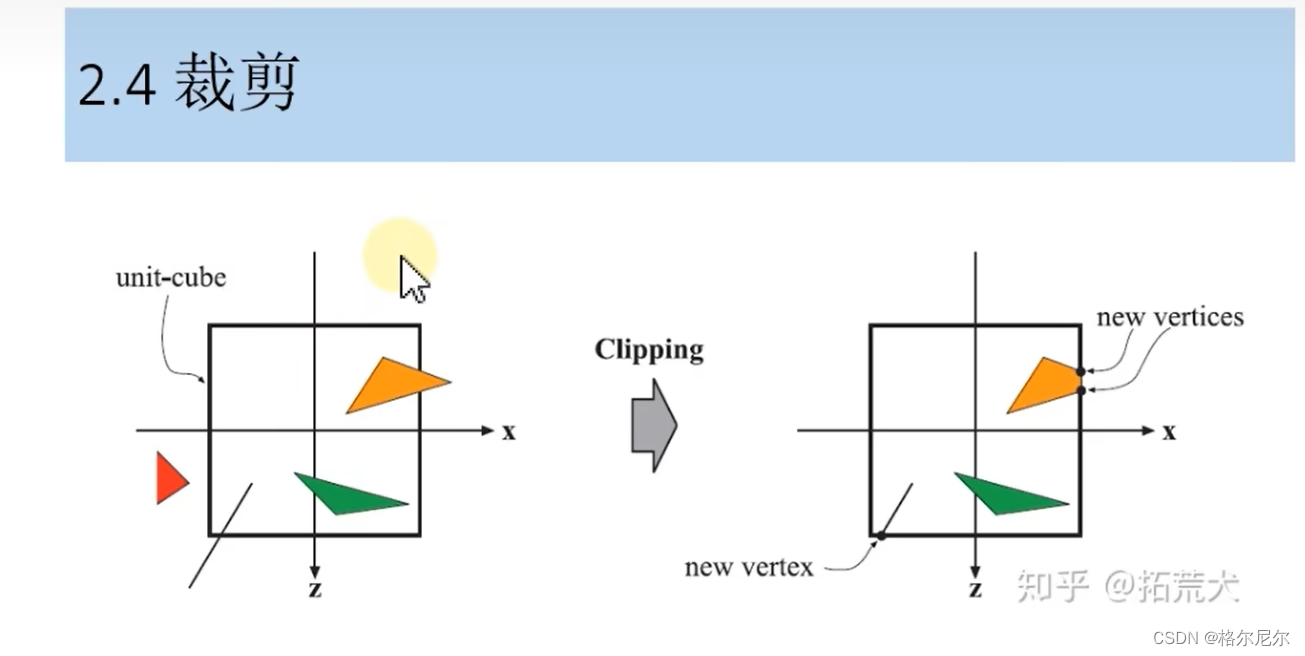
2.5 屏幕映射
投影画面映射到一定分辨率的屏幕画面
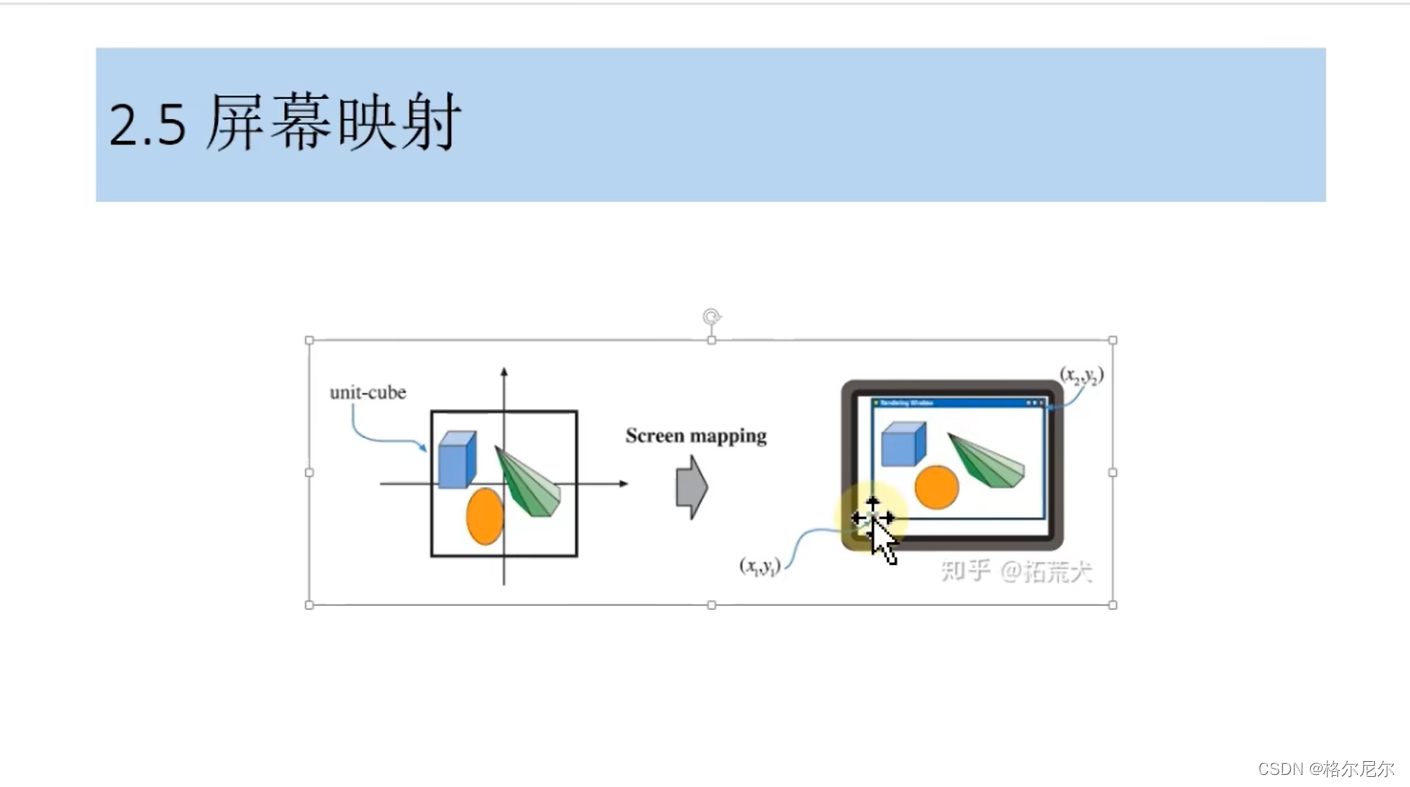
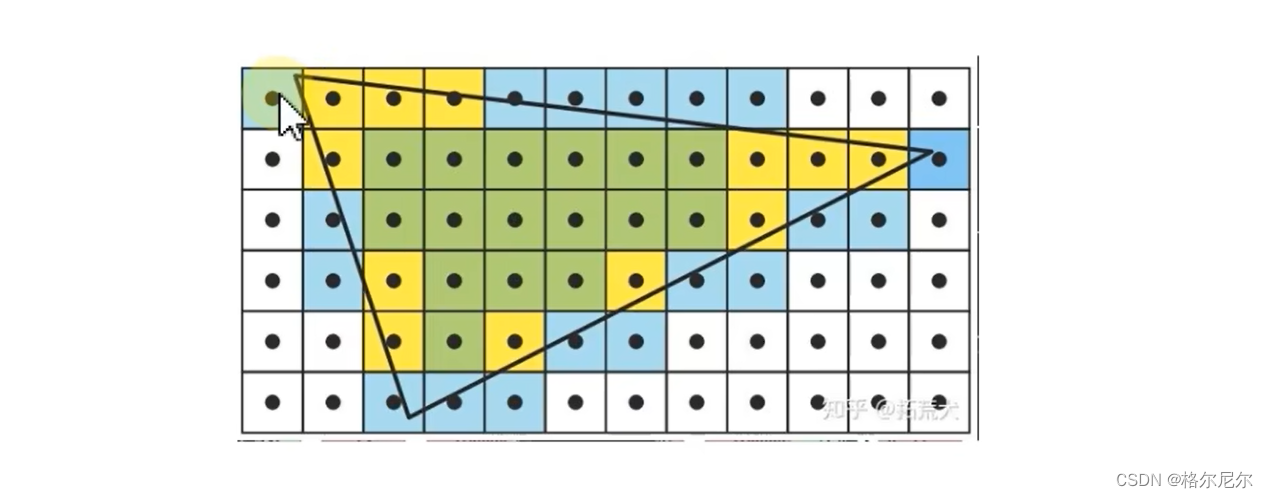
3 光栅化阶段
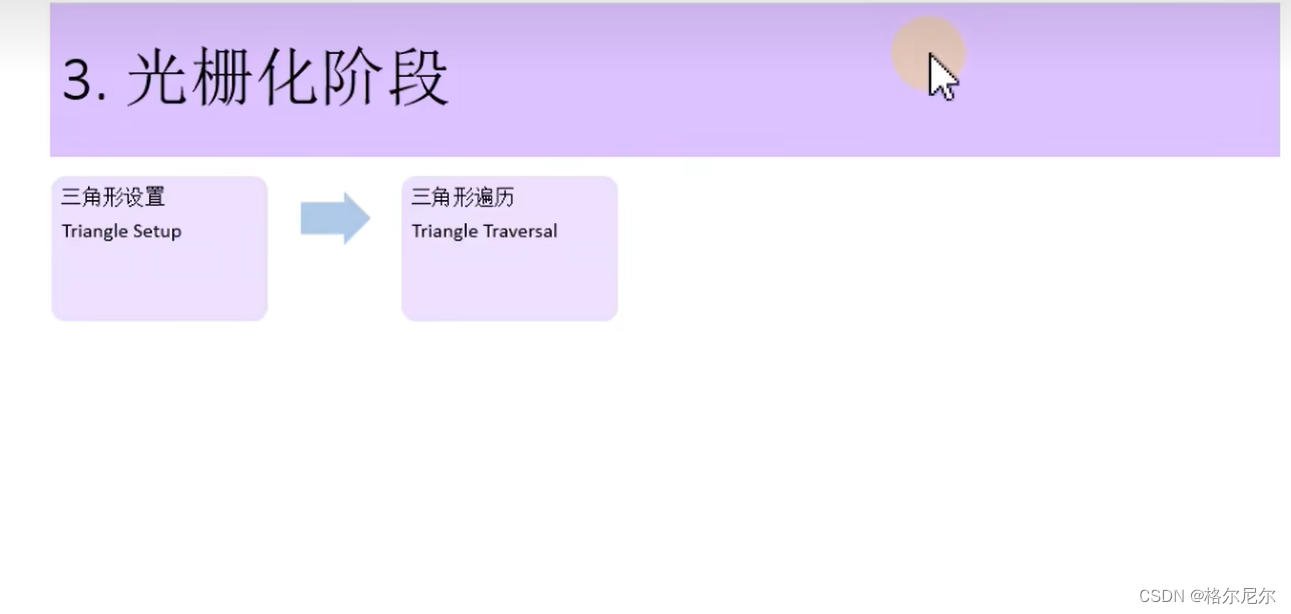
3.1 检查片元像素覆盖情况
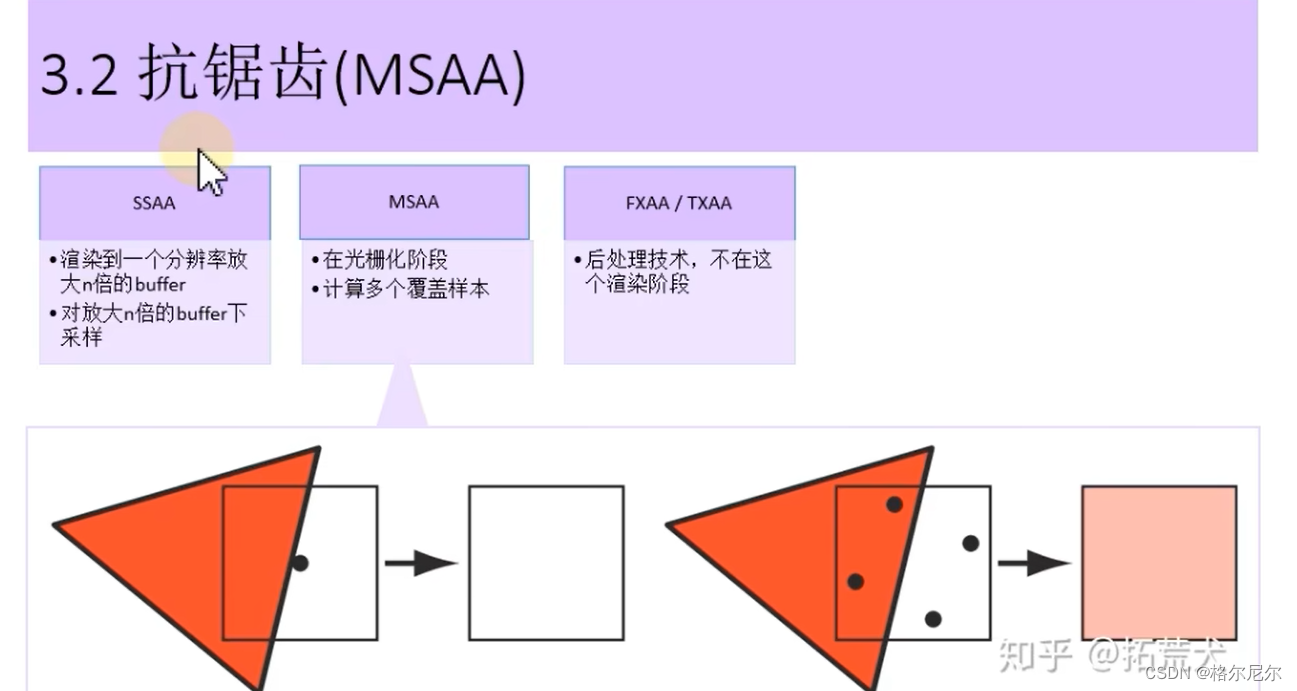
3.2
4 逐片元着色
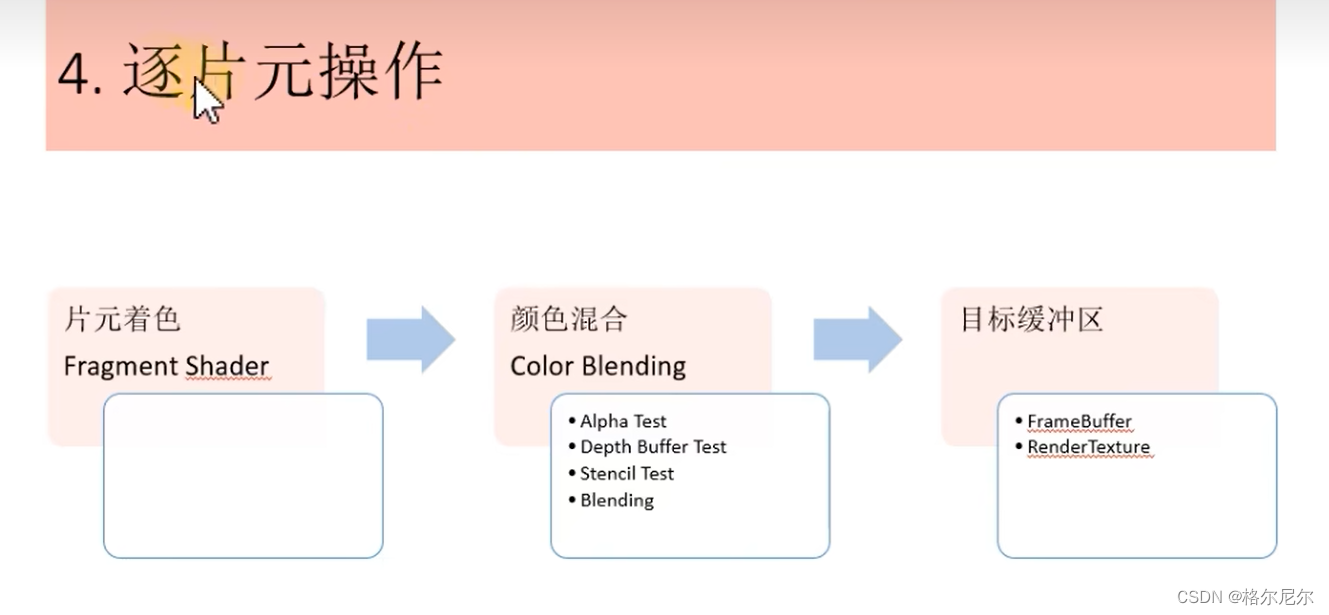
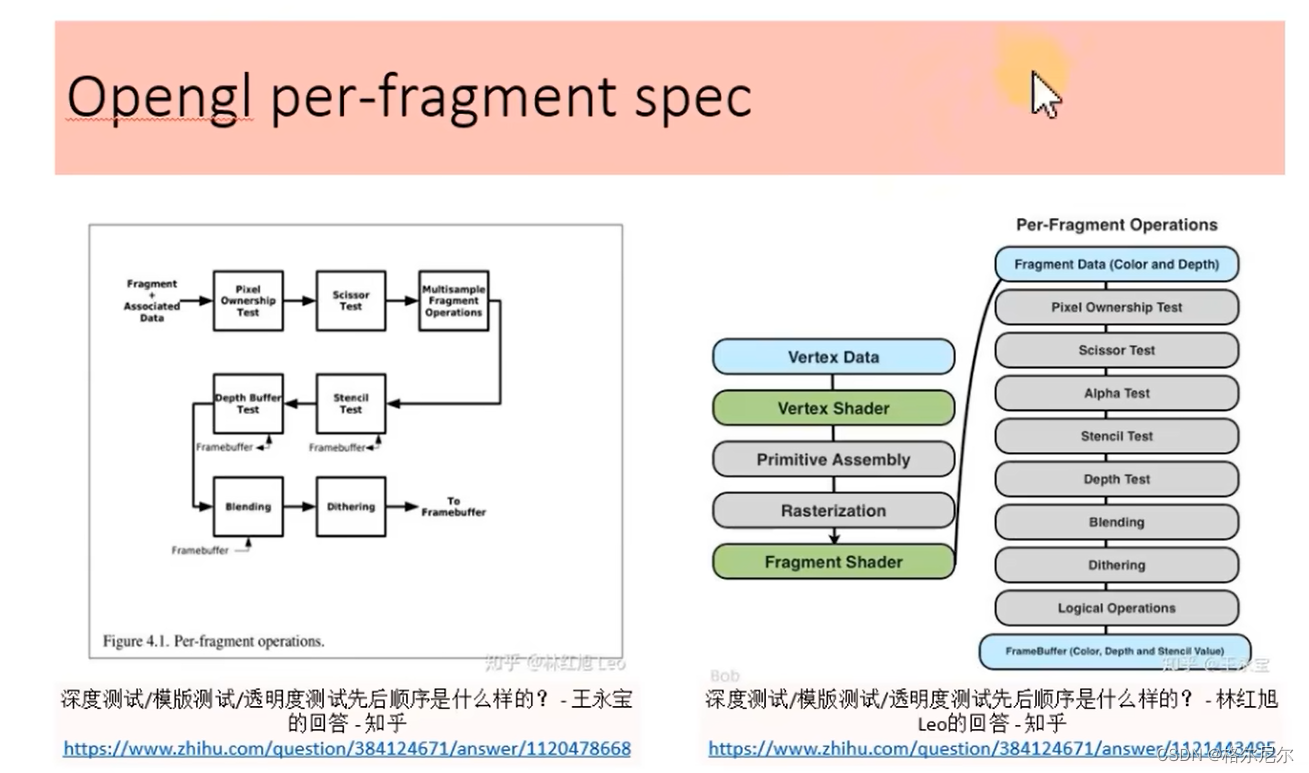
4.1 片元着色

4.2 颜色混合
- 透明度测试
- 深度测试
- 模板测试

4.3 混合

5 后处理

这个课程最好看完shader入门精要后
为什么会有渲染管线
CPU与GPU的区别
GPU架构概述
GPU是一种众核架构,非常适合解决大规模的并行计算,可以同时执行数千个线程。
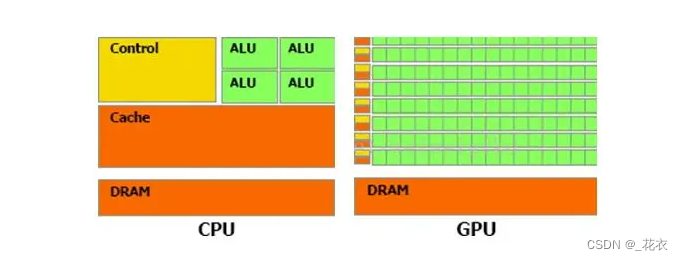
GPU是CPU的协处理器,必须通过PCIe总线与基于CPU的主机(Host)相连来进行操作,形成异构架构,如下图所示。其中CPU为主机端(Host),负责逻辑控制、数据分发,GPU为设备端(Device),负责并行数据的密集型计算。其中,ALU为算数运算单元。
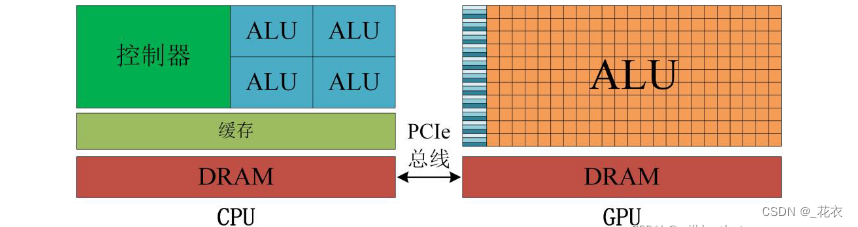
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache(高速缓存)。
CPU不仅被Cache(高速缓冲)占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路。
一个很形象的比喻:GPU的工作大部分就是这样,计算量大,但没什么技术含量,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,而不是雇佣教授。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生。GPU就是这样,用很多简单的计算单元去完成大量的计算任务。这种策略基于一个前提,就是任务A和任务B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如破解密码,虚拟货币计算和图形学的渲染计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。(该段参考知乎一个回答,但是找不到了)
计算密集型即大部分运行时间都在寄存器运算上面。
易于并行的程序,基于单指令多数据流的架构,GPU拥有远多于CPU的处理核心数量,每一个核最同一时间最好能做同样的事情。目前GPU所需的数据依旧需要CPU来指定和调配,能够处理一些稍微复杂一点的计算,但相较于CPU依旧算是十分简单的计算。具体到渲染领域,由于渲染管线所需计算的高并发性,比如说对于不同点或者不同片元上都要对法线,光照,着色等信息的处理,很多步骤当中各个点和片元相互独立,并且这些计算本质上来说大部分都是一些矩阵或者向量的运算,较为简单。所以在图形渲染领域大量地使用了GPU进行计算。
加载所有渲染所需的数据都需要从硬盘(Hard Disk Drive)中加载到系统内存(Random Access Memory, RAM) 。然后 ,网格和纹理等数据(顶点位置信息,法线方向,顶点颜色,纹理坐标,顶点索引)又被加载到显卡上的存储空间一显存(Video Random Access Memory, VRAM)中。这是因为显卡对于显存的访问速度更快,而且大多数显卡对于 RAM 没有直接的访问权利 。当把数据加载到显存当中,RAM中的数据便可以移除。但对于一些数据来说,CPU仍然需要访问它们(例如物理解算,布料、水体等等,碰撞检测属于复杂的运算),CPU依旧需要网格数据。那么该部分的RAM数据不会移除,毕竟从硬盘加载在RAM十分耗时。
CPU与GPU就像法拉利与卡车,两者的任务都是从随机位置A提取货物(即数据包),并将这些货物传送到另一个随机位置B,法拉利(CPU)可以快速地从RAM里获取一些货物,而大卡车(GPU)则慢很多,有着更高的延迟。但是,法拉利传送完所有货物需要往返多次:相比之下,大卡车虽然起步没有法拉利快,但它可以一次提取更多的货物,减少往返次数.
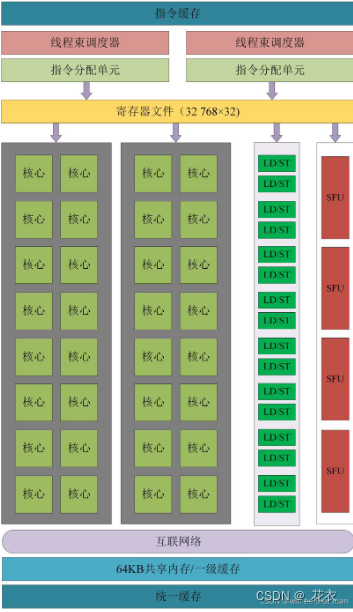
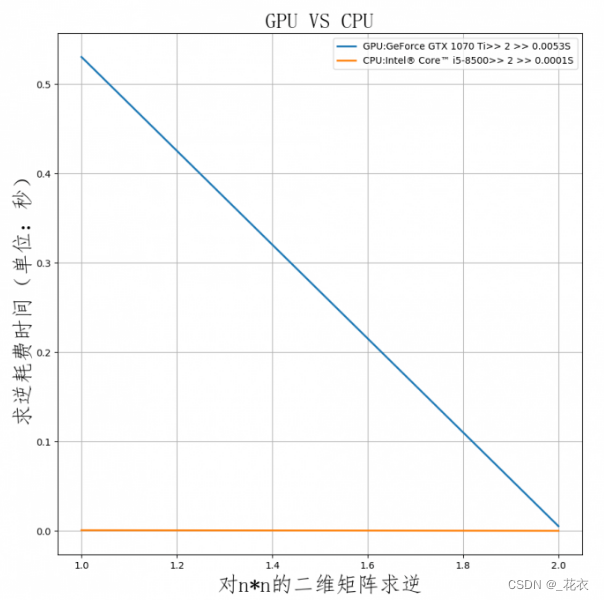
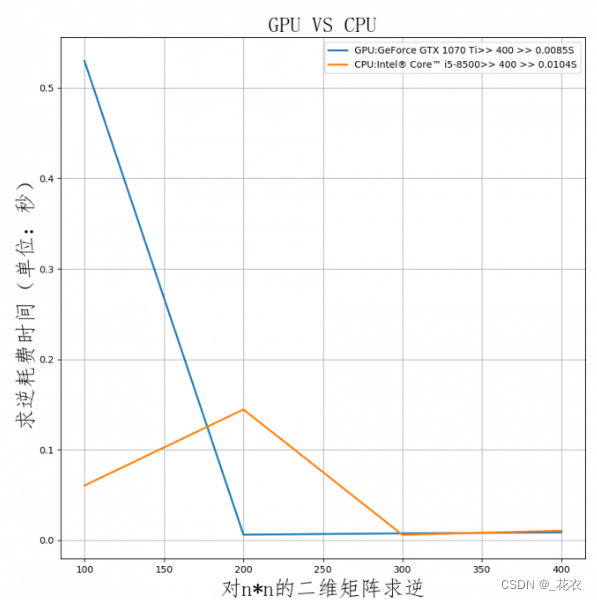
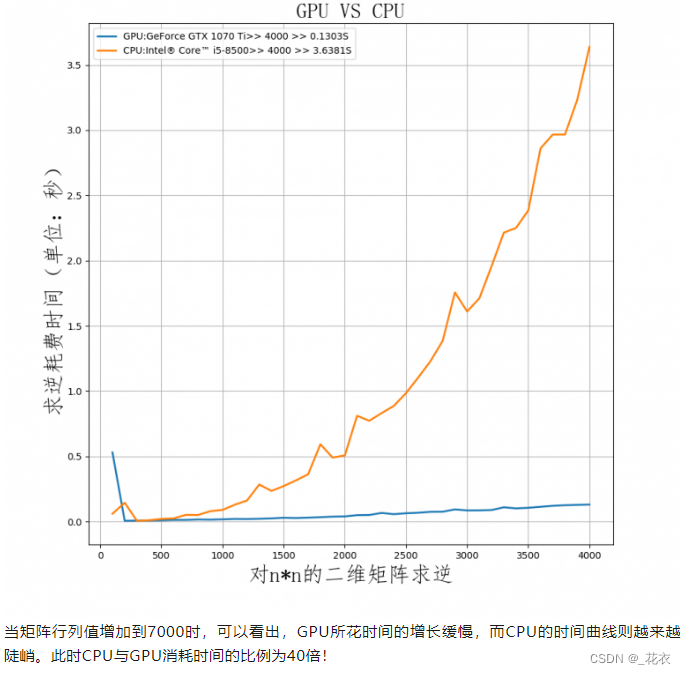
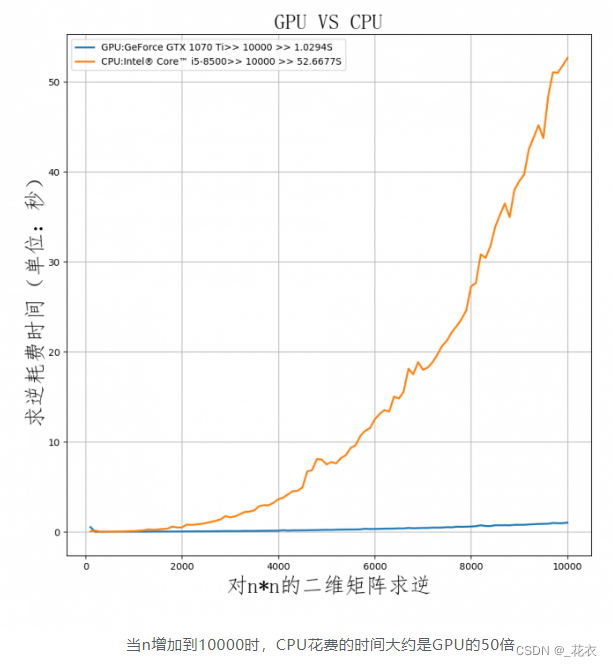
打个比方,CPU在处理一个48x48的像素任务时,假设4x4打包为一块,每周期执行一次,那么CPU需要12个周期。而GPU可以把4x4的任务分成12份,分发到12个ALU内一次性执行完成。反映到帧数上,那么CPU只有1帧,而GPU有12帧。这就是高度并行化的好处,GPU在处理细碎而多且重复的任务时,拥有得天独厚的优势。 作者:合成電波 https://www.bilibili.com/read/cv18976247 出处:bilibili


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









