






AdaVLN:面向连续室内环境中移动人类的视觉语言导航
摘要
视觉语言导航(VLN)是一项挑战机器人基于自然语言指令在现实环境中导航的任务。虽然以往的研究主要集中在静态环境中,但现实世界中的导航通常需要应对动态的人类障碍。因此,我们提出了该任务的扩展,称为自适应视觉语言导航(AdaVLN),旨在缩小这一差距。AdaVLN要求机器人在充满动态人类障碍物的复杂3D室内环境中导航,这为导航任务增加了一层复杂性,使其更贴近现实世界。为了支持这一任务的探索,我们还提出了AdaVLN模拟器和AdaR2R数据集。AdaVLN模拟器能够方便地将完全动画化的人类模型直接集成到常见的数据集中,如Matterport3D。我们还引入了一种“freeze-time”机制,用于导航任务和模拟器,在代理推理过程中暂停世界状态更新,从而在不同硬件上进行公平比较和实验可重复性。我们对多个基准模型进行了评估,分析了AdaVLN所带来的独特挑战,并展示了其在缩小视觉语言导航(VLN)研究中的仿真到现实(sim-to-real)差距方面的潜力。
介绍
室内环境中的视觉导航是体现性人工智能(Embodied AI)研究领域中的一个主题,专注于代理/机器人基于指令在未知环境中导航到目标的能力。解决这个问题通常需要代理/机器人:1)理解并记住它所处的环境;2)解读自然语言指令;3)利用前两者的信息决定一系列行动,以便充分执行给定的指令[39]。
尽管这个任务的前提非常直接,但随着时间的推移,出现了不同的变体,可以根据通信复杂度(单轮/多轮交互)、任务目标(行动/目标导向)和行动空间(离散/连续空间)进行大致分类[39, 10, 4, 27]。
在这个框架内,视觉语言导航(Visual Language Navigation,VLN)通常是一个单轮、行动导向的任务,根据任务的变体,行动空间可以是离散的或连续的[4, 16]。连续室内环境中的视觉语言导航(VLN-CE)最近得到了显著关注,因为它与日益可能的现实世界应用(例如家庭机器人助手)对接[16]。然而,现有的VLN任务常用的数据集和模拟器大多是静态的,缺乏现实场景中动态复杂特征,比如移动障碍物和变化的空间。在现实环境中,人类和其他实体常常与机器人在同一空间内移动,这要求代理不仅要执行指令,还需要预测这些动态障碍物的未来位置,并在推理时相应地调整路径。这些能力对于在其他相关导航任务(如SOON、HANNA、VLNA和VDN)中取得成功至关重要[40, 37, 20, 25, 30]。
为了缩小这一差距,我们提出了自适应视觉语言导航(Adaptive Visual Language Navigation,AdaVLN),这是VLN-CE问题的扩展,旨在将移动的人类障碍物纳入广泛使用的Habitat-Matterport3D环境中[26]。此外,我们为AdaVLN模拟器提出了一种“冻结时间”机制,在该机制下,当代理进行决策处理时,原本持续运行的模拟将会暂停,从而确保在不同硬件速度下进行公平比较。
具体而言,我们引入以下两个工具,以促进该主题的研究:
- AdaSimulator:一个提供基于物理的3D环境的模拟器,具有动态移动障碍物(如人类)和精确的移动机器人运动(参见图2和图3)。AdaSimulator基于IsaacSim[19],与Matterport3D环境[6]兼容,支持人类生成点和路径逻辑的轻松定制。
- AdaR2R:一个基于R2R [4]和Matterport3D数据集的样本变体,包含动态障碍物的生成点和轨迹,为导航任务增添了一层现实感。
最后,我们使用几个基准模型进行实验,评估我们新任务的影响,分析这些附加复杂性对代理行为和性能的影响。
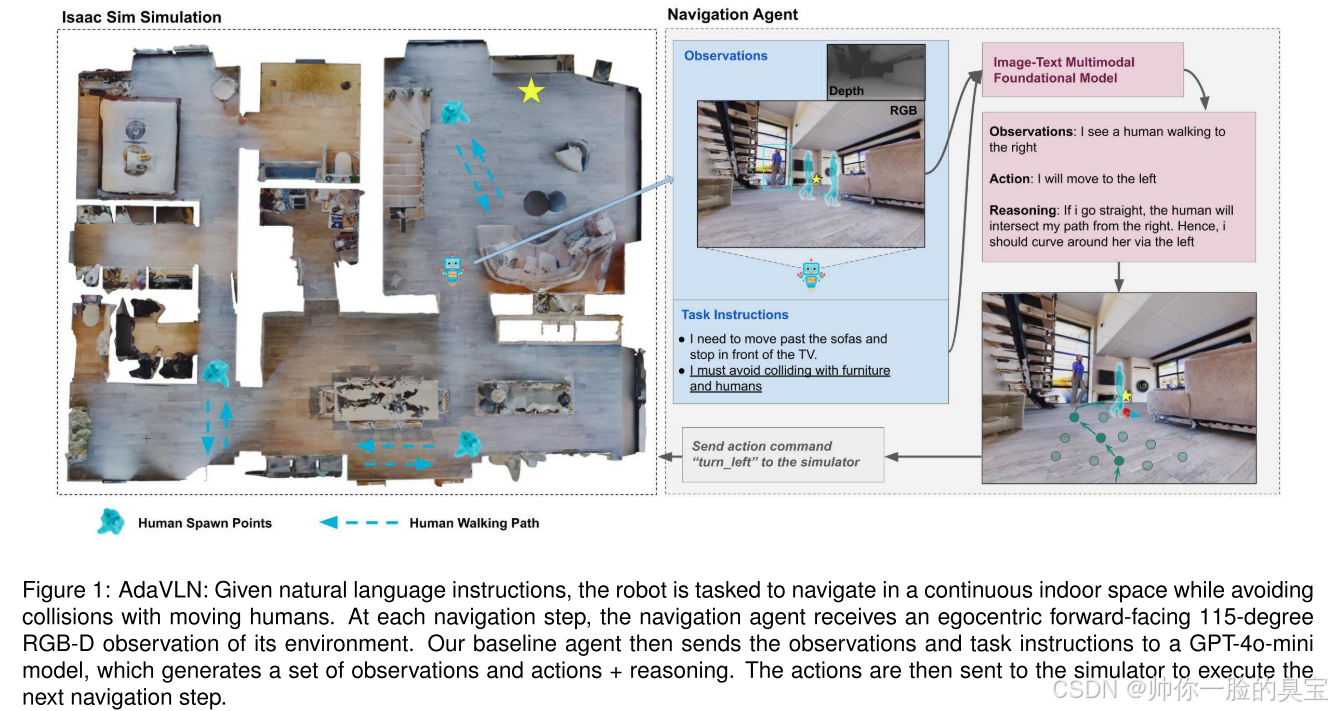
总之,我们的贡献如下(参见图1):
- 我们介绍了AdaVLN任务,作为VLN-CE的一个变体,加入了动态人类障碍物在3D环境中移动,以模拟现实生活场景。
- 我们介绍了AdaSimulator,一个基于IsaacSim的模拟器,支持基于物理的网格和动画人类,以及AdaR2R(样本)数据集,这是基于R2R-CE的示例数据集,支持配置上述环境。
- 我们运行了基于基础模型的基准代理,并讨论了代理在这种新的现实环境中导航时将面临的困难。
相关工作
VLN
多年来,VLN任务经历了演变,产生了多个变种,旨在缩小模拟环境与机器人在实际环境中可能遇到的情况之间的差距。最初的视觉语言导航任务和“Room-to-Room”(R2R)数据集由Anderson等人提出[4],要求机器人在静态3D环境中,根据单一的初始指令进行导航。在每个导航步骤中,机器人会获得一个360度全景的RGB-D视图,并需要从预先确定的邻接节点中选择一个进行传送。这个任务广泛使用了Matterport3D扫描数据集[6]作为真实3D环境的来源,并提供了最初的Matterport3D模拟器。该模拟器后来被适用于类似的静态环境任务,例如场景导向的对象导航(SOON)[40]和远程具身视觉指代表达(REVERIE)[25]。
不久之后,原始的R2R数据集得到了扩展,例如创建了R4R[14]和RxR[17],以增加导航任务的多样性和难度。同时,也有一些新的任务出现,重点放在视觉导航领域中的不同复杂性和问题上。例如,具身问答任务(EQA)[37]和带动作的视觉语言导航(VLNA)[20]被提出,这些任务不仅要求代理执行导航,还要求其基于视觉场景回答问题或执行特定动作。
随后的工作中,Habitat Sim模拟器[24, 29, 28]和Habitat-Matterport3D[26]网格数据集被引入,为在全物理启用的3D环境中进行实验提供了框架。Krantz等人[16]结合了这些工具,将VLN任务扩展到连续动作空间(VLN-CE),机器人需要通过做出低级别的移动决策(如:左转/右转15度、前进0.25米、停止)来进行导航。自此之后,围绕VLN-CE任务的RxR-Habitat竞赛在多个CVPR会议上组织,任务参数进行了一些微调[9, 2]。这个任务进一步缩小了模拟与现实之间的差距,并促使了新的世界状态建模技术的研究[1, 33, 36],以及特定于此任务的长期导航规划思想[35, 32]。[12]也展示了离散和连续变种之间的自然联系,以及它们如何在解决这两类任务时互为补充。
近期,Li等人[18]提出了一个“Human-Aware MP3D”(HA3D)模拟器,用于离散动作空间,提供了在Matterport3D环境中带有视角特定动画的人类角色,并引入了相应的“Human-Aware R2R”数据集,要求机器人在导航指令中解析这些动态元素。该论文还提出将碰撞统计信息纳入VLN实验的度量标准,例如成功率等。
导航过程中避障
碰撞避免是机器人学中一个经过广泛研究的课题,其中局部/离线路径规划特别重要,因为机器人需要能够在未知环境中表现出色。这通常要求模型预测其世界状态在轨迹上如何变化,以便在规划路径时预防性地避免障碍物。传统的机器人研究中,选择安全路径的方法使用了速度障碍(Velocity Obstacles)[8],根据周围物体和机器人自身的运动来计算潜在的碰撞路径。相互速度障碍(Reciprocal Velocity Obstacles)将此方法扩展到了现实世界场景中常见的多体交互场景。其他方法也展示了从RGB-D数据中提取运动信息的能力[11]。新的预测方法利用了强化学习技术,将动态障碍物建模为可变大小的椭球体,并考虑了代理与人类的交互动态,以便为路径预测提供基础[31, 23, 5]。这些方法通常与基于网格[7]、图[34]或3D[13]的世界建模方法相结合,为机器人提供了丰富的环境表示,以便更好地进行运动预测和环境理解。
视觉语言导航(VLN)任务已经集成了上述许多想法,用于未来规划和障碍物预测。特别是,DREAMWALKER[32]引入了利用心理模拟来预测候选轨迹上环境变化的方法。[1]聚焦于使用动态拓扑规划进行障碍物避免,之后Jeong等人[15]提出了VLN-CM代理,它利用深度图来预测候选轨迹上的预期占据图。
AdaVLN
现有的视觉语言导航(VLN)和连续视觉语言导航(VLN-CE)任务主要聚焦于静态环境的导航,未明确定义动态障碍物(如移动的人类)存在的场景。为提供更具现实感且包含人类的环境,本文提出了适应性视觉语言导航(AdaVLN),它是VLN-CE任务的扩展。
任务定义
AdaVLN基于VLN-CE任务,设置机器人在Matterport3D环境中进行导航,采用连续动作空间。在每次导航任务开始时(时间t0 = 0),机器人被初始化在位置(X0, θ0),并需要按照初始时提供的自然语言指令导航到目标位置XG。AdaVLN的一个关键新增元素是动态障碍物的引入,这些动态障碍物以人类的形式存在,并强调碰撞避免。动态障碍物的状态(X′t, θ′t)随着障碍物在AdaR2R数据集中的预定义路径(NavMesh)上的移动而不断更新。机器人需要避免与静态障碍物(例如环境网格)以及动态障碍物发生碰撞。
机器人的观测/动作
在每次导航步骤t中,机器人通过115度前向视角的RGB-D图像来观察其周围环境(如图4所示)。基于该观察结果和当前状态,机器人可以从以下四种可能的动作中选择:

- 以30度/秒的速度向左转15度
- 以30度/秒的速度向右转15度
- 以0.5米/秒的速度向前移动0.25米
- 停止
在AdaVLN任务中,时间的因素非常重要,因为机器人执行动作的速度会直接影响其表现。为了标准化各个动作的执行时间,机器人配置了线速度为0.5米/秒,旋转速度为30度/秒。这样设置的目的是使每个动作的执行时间固定为2秒钟。
"停止"命令与任务评估
当机器人执行完任务并接收到"停止"命令时,表示一轮任务的结束,此时机器人和仿真环境都会停止。机器人的表现会根据其最终状态(位置 XfX_fXf,方向角 θf\theta_fθf)以及整个路径进行评估。路径上的位置和方向随时间变化,可表示为 (Xt,θt)(X_t, \theta_t)(Xt,θt),其中 t∈[0,Tf]t \in [0, T_f]t∈[0,Tf],TfT_fTf 为任务的最终时间步。
任务步数限制
由于任务的距离相对较短,任务最大允许50步来完成导航。如果在50步内机器人未能到达目标位置,仿真会自动结束。这一限制确保任务可以在合理的时间范围内完成,并为机器人的表现提供一个明确的评价标准。
freeze-time
在AdaVLN任务中,动态障碍物的位置会在每次仿真更新(simulation tick)时发生变化。由于不同硬件的性能差异——特别是推理速度的差异——可能会导致仿真结果存在显著差异。为了确保实验结果的硬件无关性,研究人员提出了"冻结时间"(Freeze-Time)概念,用以解决这一问题。
冻结时间的作用
"冻结时间"是指在机器人预测下一步动作时,暂停仿真进程的一个机制。具体来说,当机器人正在进行动作预测(例如,基于当前观测推测下一步的行动时),仿真会暂停,直到机器人做出决策并执行动作。通过这样做,可以消除由于不同硬件推理速度造成的差异,从而保证实验在不同设备上的一致性。
可切换功能
"冻结时间"是AdaSimulator中的一个可切换功能,意味着研究人员可以根据需要启用或禁用此功能。如果未来的研究希望考虑推理速度对导航性能的影响,可以关闭该功能,让推理速度成为评估因素之一。然而,当启用"冻结时间"时,硬件性能差异对仿真结果的影响将被最小化,保证所有实验的公平性。
方法
Ada模拟器
AdaSimulator 是一个独立的扩展,基于 IsaacSim 实现,利用其物理引擎和 RTX 渲染器。该模拟器在加载场景时会自动设置所需的环境组件。具体来说,AdaSimulator 的实现包括以下功能:
-
静态障碍物的碰撞网格设置:
- 为场景中的静态障碍物设置碰撞网格(collider meshes),使机器人能够感知并避免与这些障碍物的碰撞。
-
生成 Jetbot:
- 在指定的初始位置
(X0, θ0)生成一个 Jetbot(NVIDIA 的两轮机器人平台)。该机器人通过差速控制器进行物理驱动的运动。
- 在指定的初始位置
-
设置相机渲染产品:
- 使用 IsaacSim 的渲染功能生成机器人的观察数据,即 RGB-D 图像。相机的视角通过 Jetbot 上的摄像头来确定。
-
加载环境照明设备:
- 设置适当的环境照明,以模拟真实的光照条件。
-
加载动态人类障碍物:
- 在指定的位置
(X′0, θ′0)加载动态人类障碍物,并配置他们的动画图(animation graphs),使他们在场景中能够按照预定的行为模式移动。
- 在指定的位置
机器人和人类障碍物设置
-
两轮 Jetbot:
- 所有的仿真场景使用两轮的 NVIDIA Jetbot,它通过差速控制器(differential controller)控制运动。该控制方式模拟了物理学中的运动行为,帮助机器人在环境中更精确地导航。
-
RGB-D 观察:
- 机器人通过其附加的摄像头捕捉周围环境的 RGB-D 图像(包括颜色和深度信息),并将这些图像用作其导航决策的依据。图像渲染是通过 IsaacSim 的 Replicator Core 模块完成的。
-
动态人类障碍物:
- 环境中引入了动态的障碍物,这些障碍物是通过 omni.anim.people 扩展定制的。这个扩展允许人类角色在场景中动态移动,成为机器人导航任务中的干扰因素。
控制与接口
- ROS2 接口:
- AdaSimulator 提供了 ROS2 接口,使得智能体(agent)能够从模拟器中提取 RGB-D 观察数据,并发送控制命令。这样,研究者可以利用 ROS2 进行机器人控制和数据处理。
模拟器模式
AdaSimulator 提供两种运行模式:
-
GUI 模式:
- 在 GUI 模式下,用户可以全程可视化机器人导航的过程,并手动输入机器人的控制命令。这对于调试和验证机器人行为非常有用。
-
无头模式(Headless mode):
- 无头模式则没有图形用户界面,适合进行大规模训练。在这种模式下,仿真不需要渲染界面,能最大化训练速度,适用于深度学习模型的训练任务。
AdaR2R(采样)
AdaR2R (示例数据集) 是一个包含 9 个导航任务的示例数据集,涉及 3 个 HM3Dv2 示例场景 [26]。这些场景中的环境和人类障碍物的快照如图 5 所示。该数据集对原始 R2R 数据集格式进行了修改,加入了人类生成点、路径关键点和运动参数的配置。示例配置手动设置,每个任务包含 1 到 2 个动态人类障碍物,其路径关键点的选择使得它们与关键节点之间的直线路径直接发生干扰。然而,这些干扰通常不会是永久性的,障碍物会被设计成要么通过绕过障碍物的替代路径,或者随着障碍物巡逻的进行,障碍物最终会离开。
任务的设计故意保持简化,主要关注人类障碍物的处理。每个导航任务的平均测地距离为 5.84 米。
作为一个示例数据集,AdaR2R (示例数据集) 旨在为未来的研究提供参考,帮助构建基于现有R2R的新任务变体。环境和机器人都使用由 IsaacSim 确定的默认偏移值的三角形碰撞网格。
实验
评估协议
为了展示任务和模拟器的基准使用,我们评估了一个基准代理的能力,检查其是否能够导航到目标并避免与人类及环境障碍物发生碰撞。VLN 任务的传统评估指标通常关注代理的导航表现 [3, 4, 38]。由于我们关注的是引入一个新的仿真框架,而非代理本身,因此我们将重点评估基准代理与环境和人类障碍物的碰撞情况。
导航碰撞 (Navigation Collisions, NC) 记录代理与人类或静态环境障碍物(如墙壁、家具等)发生碰撞的时间占总导航时间的比率。我们还将其细分为 人类导航碰撞 (Human Navigation Collisions, HNC) 和 环境导航碰撞。此外,我们还将对基准代理在若干导航任务中的观察和行为进行定性分析。
由于任务的测地距离比 R2R 和 R2R-CE 更短,代理每个任务的最大导航步数限制为 50 步。
物理设定
NVIDIA Jetbot 配备了差分控制器,轮子半径设置为 0.035 米,轮距(轮轴间距离)为 0.1 米。
GPT智能体的baseline
如图 6 和表 1 所示,碰撞率普遍较高,原因在于代理的环境解析能力较差。特别地,我们注意到代理经常做出虚假的观察,包括:
- 声明前方路径畅通,即使它们面朝墙壁。
- 声明前方没有人或障碍物,即使实际上有。
- 幻觉般地认为指令中的物体就在它们面前。
我们还注意到,由于机器人和环境的完全物理仿真,机器人很难从与墙壁的碰撞中恢复,相较于 HabitatSim 模拟器,这种情况更加困难。机器人不会在碰撞后简单地沿墙滑行;相反,由于机器人形状的特点,它很可能会在试图向墙壁推进时翻倒。即使机器人没有翻倒,它也无法有效地转动,因此无法逃脱,因为没有定义“倒退”动作。这使得一旦机器人陷入静态碰撞情境,就几乎不可能摆脱,从而为这种仿真带来了新的困难和更高的真实感。这与 HabitatSim 等其他仿真器不同,后者通过允许机器人沿墙“滑行”来解决这个问题。
虽然与人类的碰撞只占总碰撞的一小部分,但这主要是因为人类会继续沿路径移动,并在接触后离开碰撞区域。如图 6 所示,代理在绕过人类障碍物时几乎不做任何努力。我们假设这种行为是由于人类 3D 模型缺乏真实感,导致基础模型无法识别它们为障碍物。
总结和未来工作
我们提出了 AdaVLN,它扩展了 VLN-CE 问题,针对具有动态障碍物(如移动人类)的动态环境中的代理/机器人导航进行了研究。与此同时,我们介绍了 AdaSimulator,这是 IsaacSim 的扩展,旨在设置具有真实机器人和动画 3D 人物的完全物理仿真。我们的基线实验表明,仿真器的新增复杂性使得评估更加真实,并突显了新任务所面临的潜在挑战。
我们计划通过优化仿真环境、将任务形式化推广到更广泛的动态环境,以及开发能够有效导航这些复杂场景的代理,来扩展这一研究工作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









