






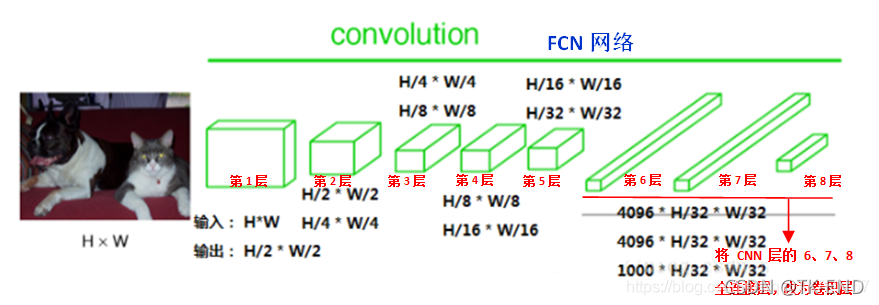
1 FCN
卷积层:
对原图像进行卷积 conv1、pool1后原图像缩小为1/2;
之后对图像进行第二次 conv2、pool2后图像缩小为1/4;
继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;
继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;
最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,
然后把原来CNN操作中的全连接变成卷积操作conv6、conv7、conv8,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
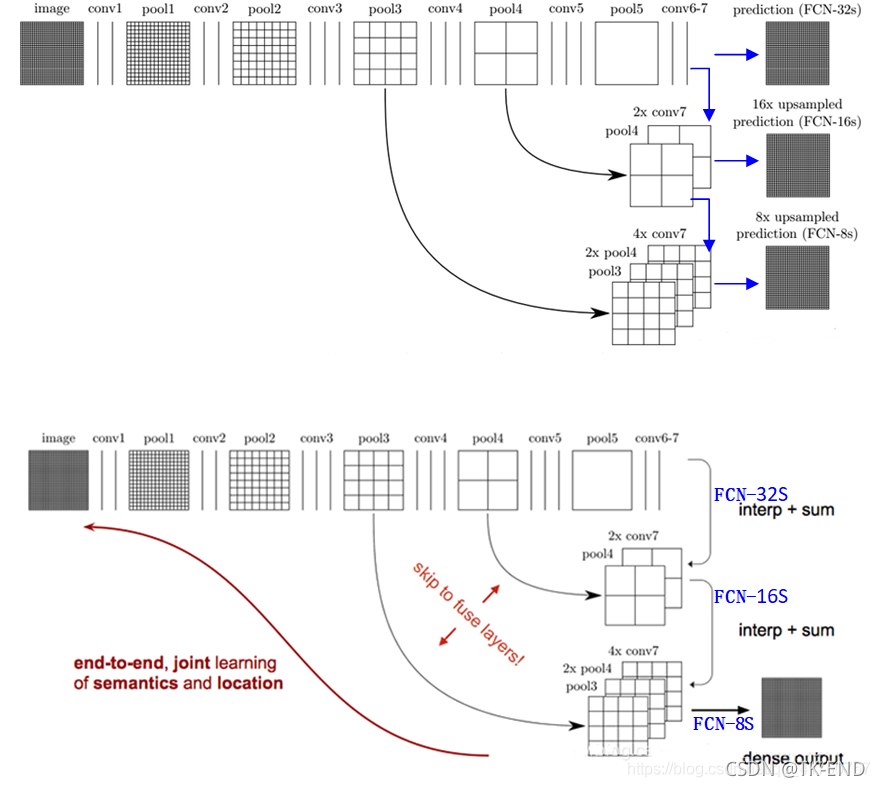
upsampling上采样操作:使用上卷积(一次上池化+一次反卷积)

跳级结构:将1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,进行upsampling操作之后,把三个不同深度的预测结果进行融合(求和运算, 使用逐数据相加,较浅的结果更为精细,较深的结果更为鲁棒)
最终输出:原图W原图H类别背景数
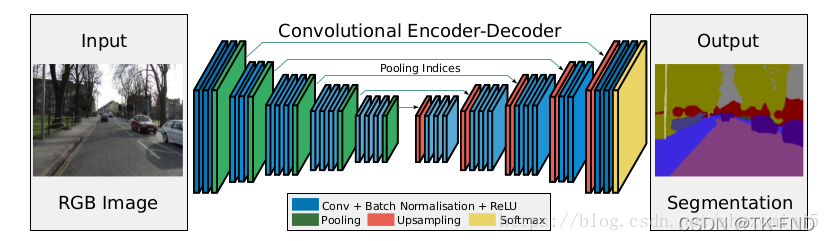
2 SegNet
结构的整体理解 本质上遵循编码解码结构,与FCN , Unet相同。
主要贡献 上采样采用下采样最大池化的位置索引,其余位置补充为0。
这样可以提升训练效率,同时节约内存,边缘更平缓,速度很快。
2.1 deepcrack
1 基于segnet改进,增加多尺度特征图融合,用于裂纹检测
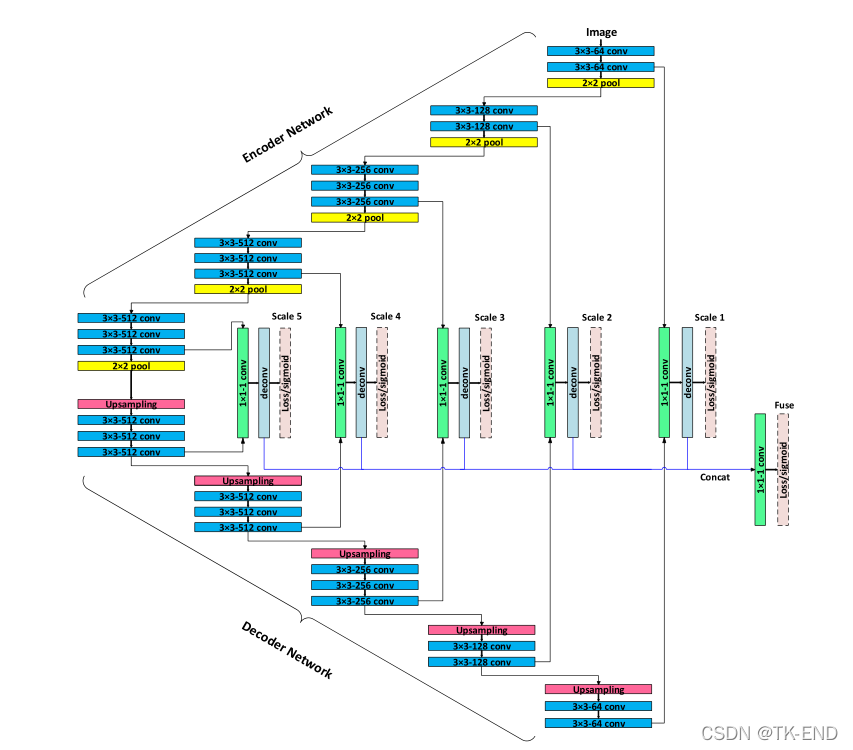
尺度融合(skip-layer fusion )详解:
每组对应特征融合
1 编解码对应特征图叠加连接
2 接着是1×1 conv层,该层将多通道特征映射减少到一个通道。
3 反卷积层进行上采样。为了计算每个尺度中的逐像素预测损失,将添加一个反卷积层来对特征图进行上采样
4crop层来将上采样结果裁剪为输入图像的大小。
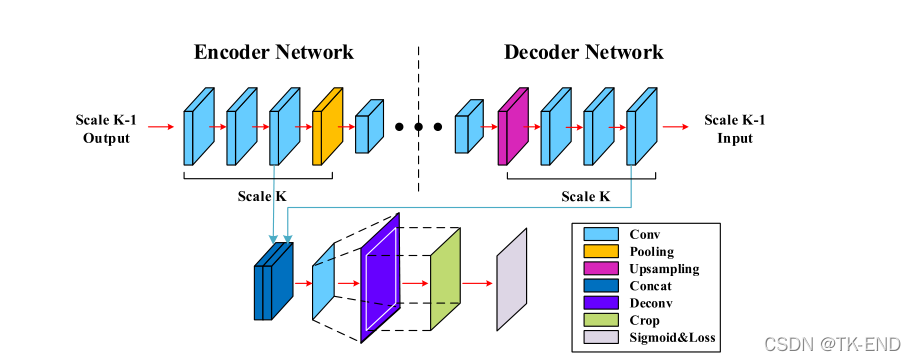
2 融合五组特征:
将五个一通道的融合特征图堆叠后,使用1*1-1conv层将其融合为一个通道预测图(fuse预测图),该图通过使用交叉熵损失来指示每个像素属于裂缝的概率。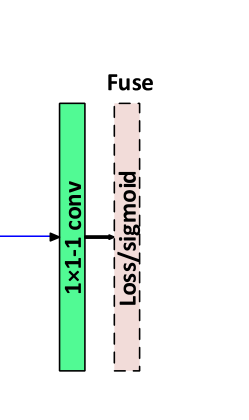
loss 函数:
像素loss:
Fi是网络的输出特征图中的像素i,W是网络层中的标准参数集,P(F)是标准sigmoid函数,其将特征图转换为裂缝概率图。

总loss:
I:每张图片中的像素点集合
k:不同尺度的融合特征图集合{ 1(压缩一次,浅层特征),2,3,4,5}
Fik值第k个融合特征层中i像素的输出值,deep crack的总损失为每个融合特征层的损失+fuse预测图的损失
ak :第k个融合特征图的权重
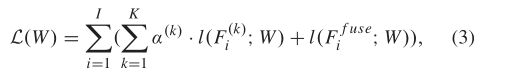
3 本文提出观点:
(1) 多尺度融合利于线检测
(2) 裂纹检测为二分类检测,裂纹像素占比少,这使其成为不平衡的分类或分割。可以通过给少数类增加更大的权重来处理这个问题,但在deepcrack中会导致误检率增加。
(3) deepcrack 的loss函数中涵括了不同尺度的特征融合图,并赋予不同权重进行了训练评估,结果表明:

(4)从0开始训练的模型效果比fine tune的更好,可能是公用数据集不适合做裂纹检测的迁移。
4 训练细节:
- input 512*512
- MSRA初始化
3 U-NET
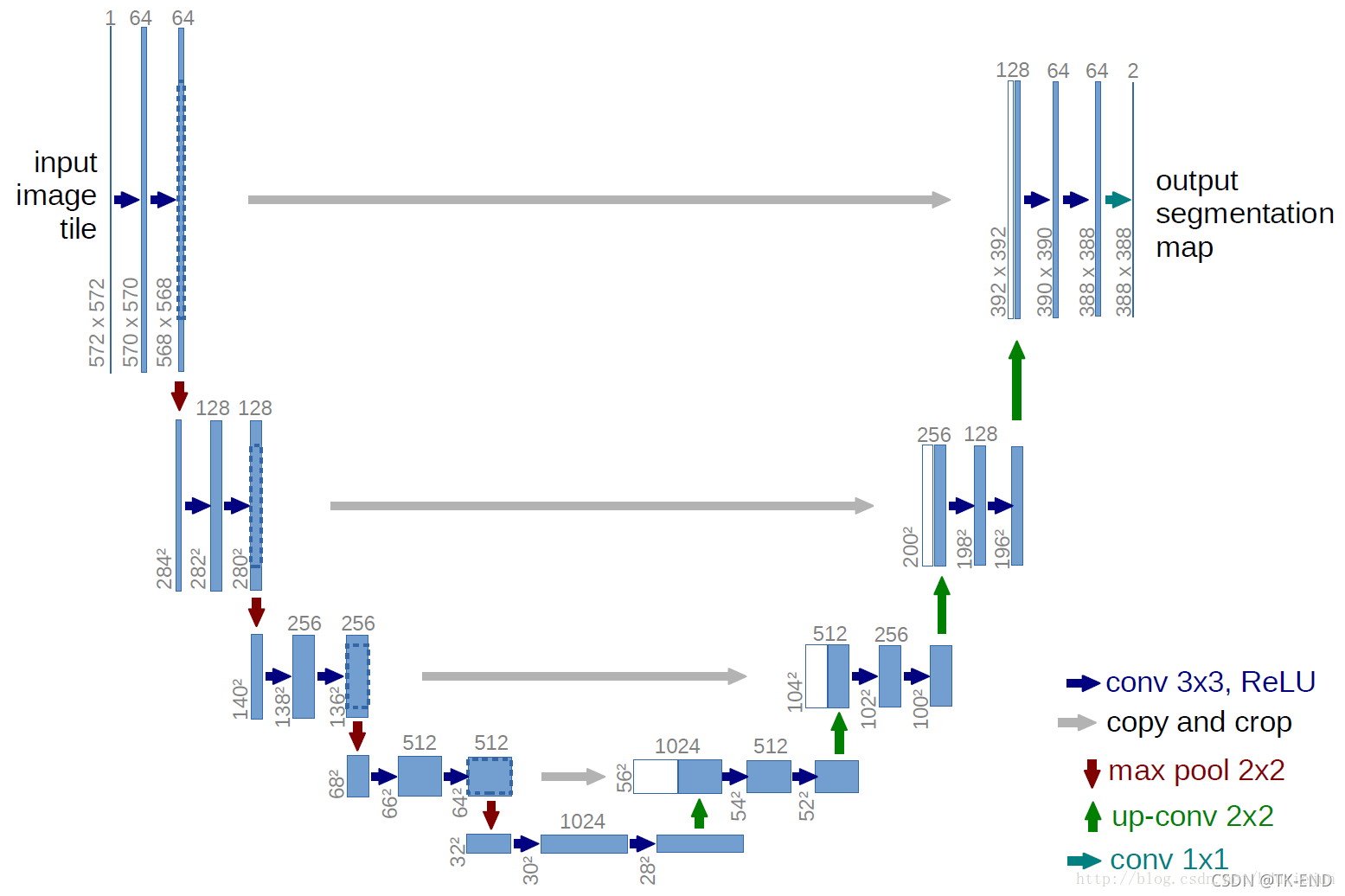
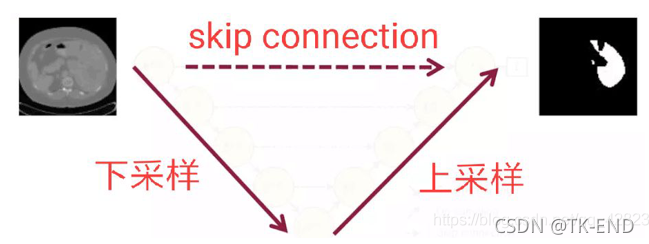
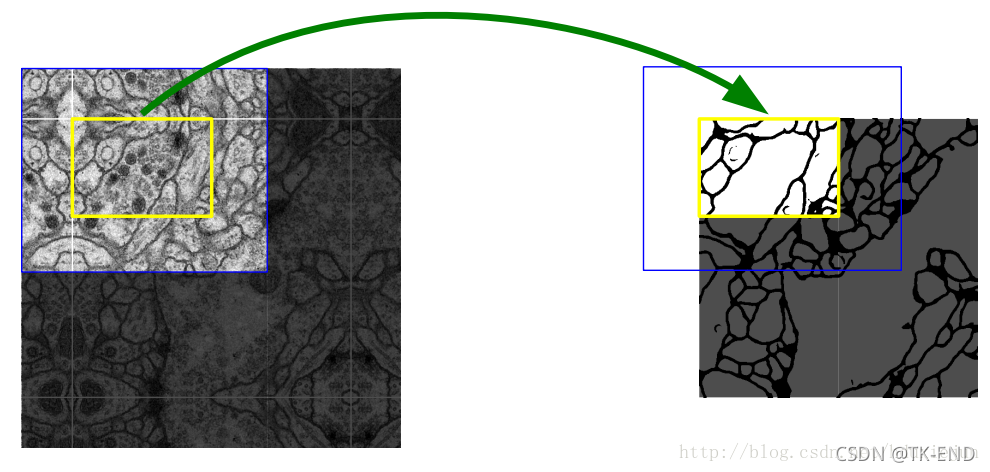
卷积层的数量大约在20个左右,4次下采样,4次上采样。输入图像大于输出图像,因为在本论文中对输入图像做了镜像操作。
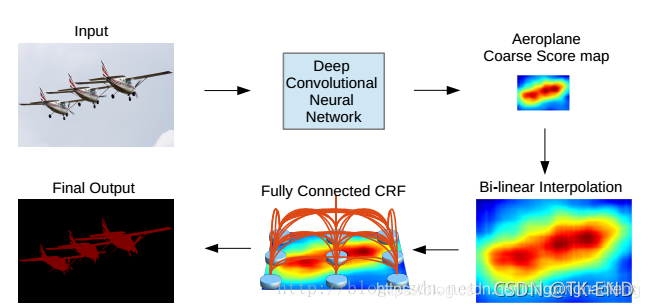
4 Deeplab V1
参考链接
DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成.第一步仍然采用了DCNNs得到 coarse score map并插值到原图像大小,然后第二步借用fully connected CRF对从FCN得到的分割结果进行细节上的refine.
1 DCNN设计
调整VGG16模型,

在VGG16中,卷积核大小统一为 3x3 ,步长为 1,最大池化层的池化窗口为 2 * 2 ,步长为2 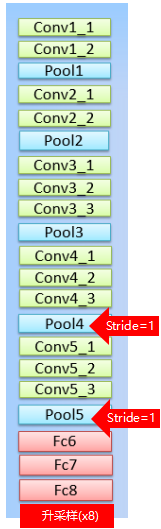
做出的调整:
- VGG16的FC层转为1x1的卷积层
- pool4,pool5步长由2改为1,VGG网络总的步长由原来的32变为8,问题:感知野相比五次池化,变小了。
- 为扩大感知野使其与VGG原模型相同,在conv5_1, conv5_2和conv5_3中采用空洞卷积,hole size为2。
- 空洞卷积的作用:不增加参数个数前提下,获得更大的感受野。
以VGG16为例子计算感知野
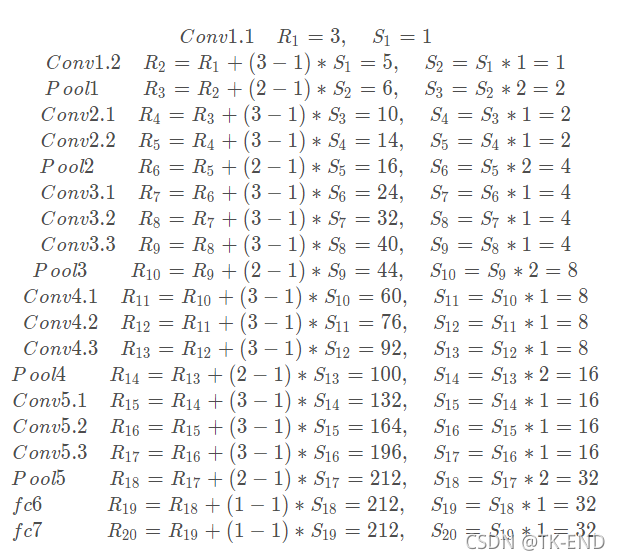
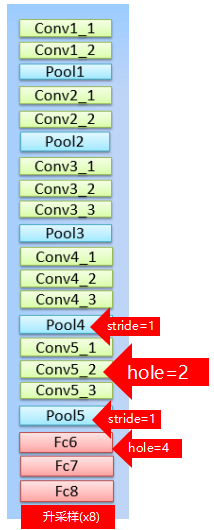
pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。接着pool5由2变为1, 则后面的fc6中hole size为4。 计算感知野。
2 解码及CRF处理
- CRF:决定一个位置的像素值时(paper里是label),会考虑周围像素点的值(label),做平滑处理。
- 通过CNN得到的概率图在一定程度上已经足够平滑,所以短程的CRF没有太大的意义。于是考虑使用Fully connected CRF,这样就会综合考虑全局信息,恢复详细的局部结构,如精确图形的轮廓。
- CRF几乎可以用于所有的分割任务中图像精度的提高。
在测试时对特征提取后得到的得分图进行双线性插值,恢复到原图尺寸,然后再进行CRF处理(后处理,不参与训练),因为缩小8倍的,所以直接放大到原图是可以接受的。如果是32倍,则需要上采样(反卷积)。
3 缺点
弊端有两个:
1、它需要在高分辨率特征上计算卷积,而这些特征通常高维,计算量很大,而且在使用空洞卷积时,往往限制最后的输出尺寸为原始输入的1/8;
2、空洞卷积过程产生的粗糙特征可能也会丢失一部分重要细节。
5 Deeplap V2
解决物体多尺度问题:
- 空洞卷积
- 通过resize多尺度输入图片,最终结果取对象像素点位置最大的响应结果。
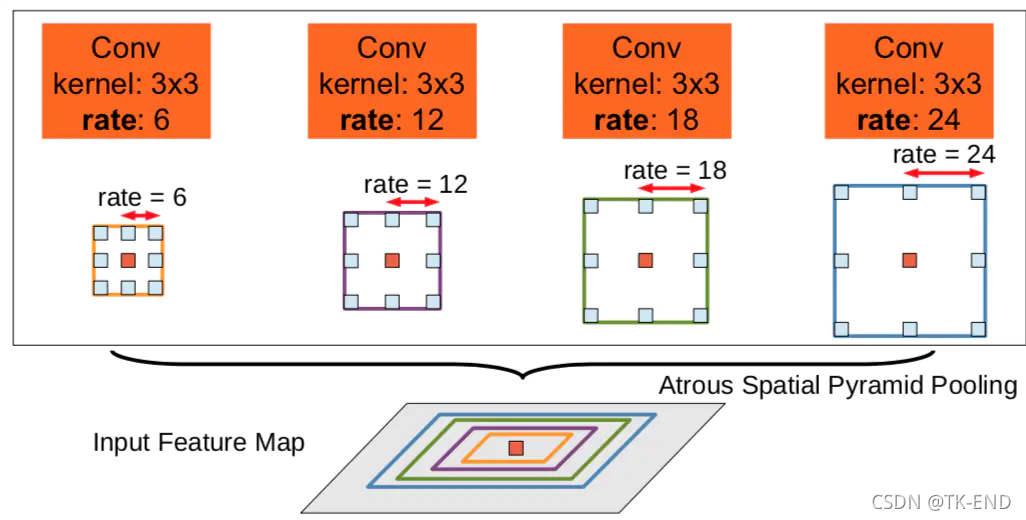
- 受R-CNN的spatial pyramid pooling(SPP)启发,得到atrous spatial pyramid pooling(ASPP)结构(和v1不同之处)
具体结构如图所示:
ASPP:通过不同的rate构建不同感受野的卷积核,串联不同膨胀率的空洞卷积或者并行不同膨胀率的空洞卷积,用来获取多尺度物体信息。
6 Deeplab V3
博客
1 DCNNs中语义分割存在三个挑战:
- 连续下采用和重复池化,导致最后特征图分辨率低
- 图像中存在多尺度的物体
作者的处理方案:
- 使用空洞卷积,防止分辨率过低情况
- 串联不同膨胀率的空洞卷积或者并行不同膨胀率的空洞卷积(v2的ASPP),来获取更多上下文信息
优势
- 当时在PASCAL VOC 2012 test上效果最好,并且没有使用DenseCRF
本文主要工作
- 探索更深结构下的空洞卷积探索(串行结构)
- 优化atrous spatial pyramid pooling—ASPP(并行结构)
7 RefineNet
1 设计初衷
- 相同感知野下残差卷积和空洞卷积优缺点对比:
- 残差卷积:防止梯度爆炸、计算量小,但会损失特征图分辨率
- 空洞卷积:计算量大,训练成本高,但能保存较大特征图分辨率,利于边界的定位细化。
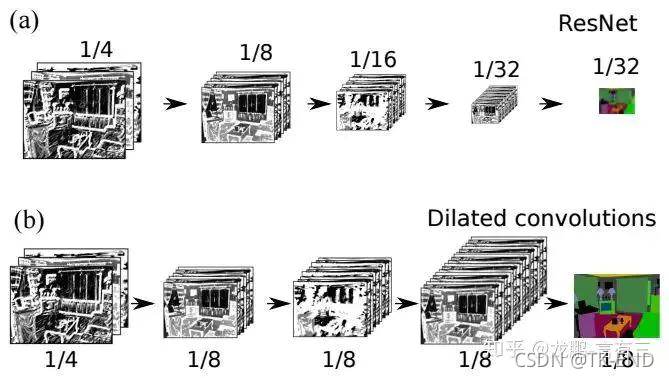
设计目的:利用残差卷积,做到全局特征融合
2 总体架构
与U-NET类似,采用编解码结构
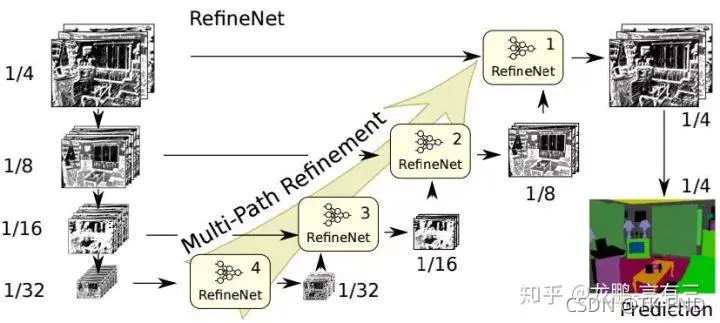
- 编码部分:RESNET,生成四个不同大小特征层
- 解码部分:提出refinenet模块,进行残差堆叠和特征融合。
3 refinenet模块
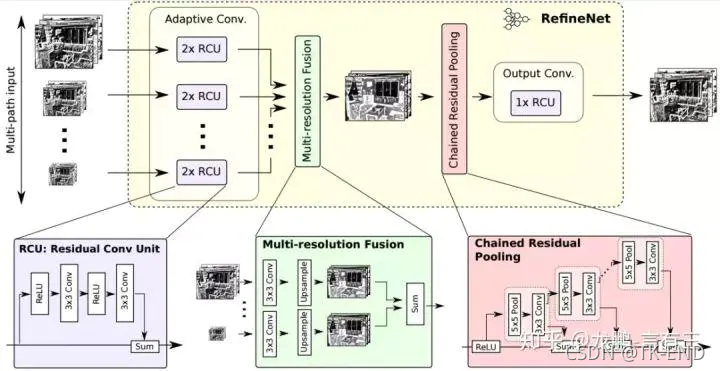
RefineNet总共包括三大模块:
残差卷积模块(RCU,Residual Convolution Unit)
多分辨率融合模块(Multi-Resolution Fusion)
串联残差池化模块(Chained Residual Pooling)。
(1) RCU模块
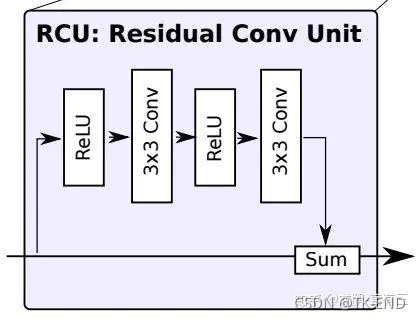
一个RCU模块包括一个Relu层和一个卷积层。两个RCU模块构成一条残差边。
网络结构中,每个分辨率的特征层应用两个串联的RCU模块,提取分割结果的残差,最后相加来校正原始分割结果。
除RefineNet 4中为512个卷积核外,其余所有输入路径上的卷积核个数均为256。
(2) 多分辨率融合
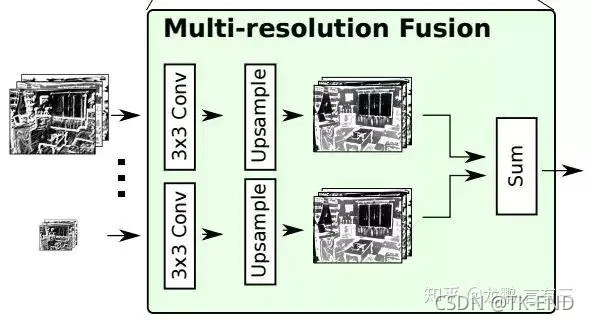
作用是将所有的输入通过这个模块融合到高分辨率特征图上。
特征层经过RUC残差处理后,得到的不同分辨率的特征层。
网络首先通过一个卷积层处理输入的不同分辨率卷积层,得到各通道下的适应性权重。随后,应用上采样,将所有输入卷积层上采样到所有输入中的最大size,并根据不同通道权重加权求和。
- 若只有一个输入路径,例如RefineNet-4,则输入将直接经过此块而不做任何更改。
- 若有多个输入,比如RefineNet-3,输入1为resnet压缩后为1/16原图大小的特征层,输入2为RefineNet-4输出的为1/32原图大小的特征层,则经过RefineNet-3,两个输入会上采样为1/16原图大小的特征层,再加权相加,最后输出1/16原图大小的特征层,作为RefineNet-2的输入。
(3) 串联残差池化
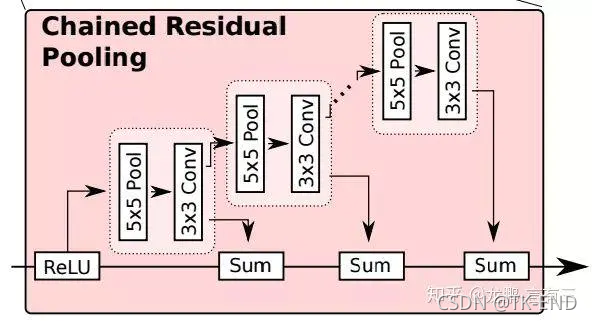
作用 : 进一步通过残差校正的方式,优化前两步融合得到的分割结果。
这个模块主要由一个残差结构、一个池化层和一个卷积层组成。其中,池化层加卷积层用来习得用于校正的残差。值得注意的是,RefineNet在这里用了一个比较巧妙的做法:用前一级的残差结果作为下一级的残差学习模块的输入,而非直接从校正后的分割结果上再重新习得一个独立的残差。
这样做的目的,RefineNet的作者是这样解释的:可以使得后面的模块在前面残差的基础上,继续深入学习,得到一个更好的残差校正结果。
最后,网络又经过一个一个RCU模块,平衡所有的权重,最终得到与输入空间尺寸相同的分割结果。
4 网络结构变种
除了上述的基础网络结构,RefineNet还可以存在下面几种变种。
(1) 单个RefineNet
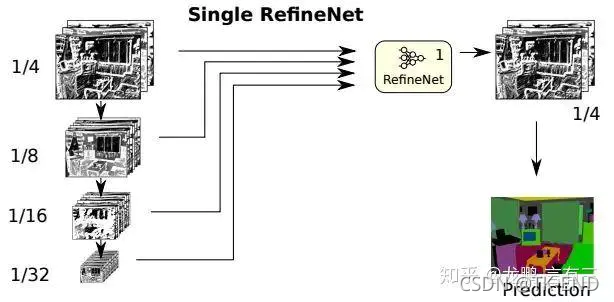
(2) 2次级联的RefineNet
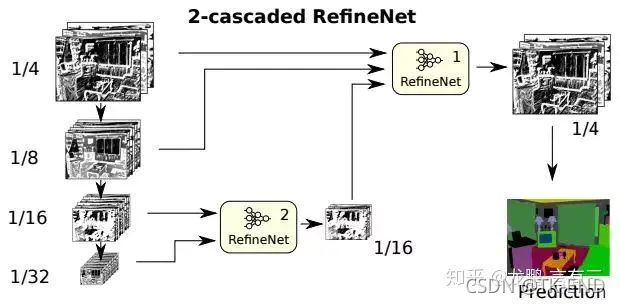
(3) 4次级联2倍RefineNet
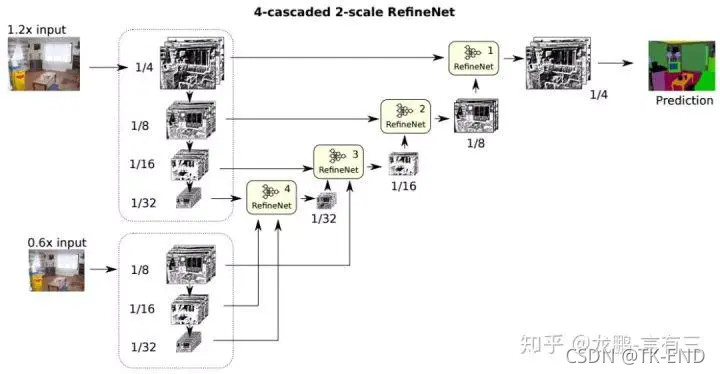
8 PSPNet
空洞卷积(dilated FCN,也叫扩张卷积)+全局金字塔池化(global pyramid pooling)
1 金字塔结构优点
特征金字塔并行考虑了多个感受野下的目标特征,好处如下:
- 1 利用上下文信息:
例如,我们判断一个东西的类别时,除了直接观察其外观,有时候还会辅助其出现的环境。比如汽车通常出现在道路上、船通常在水面、飞机通常在天上等。忽略了这些直接做判断,有时候就会造成歧义。比如下图中,在水面上的船由于其外观,就被FCN算法判断成汽车了。

从左到右分别为:图像、真值、FCN结果和PSPNet结果。
- 2 对于尺寸较大或尺寸过小的目标有更好的识别效果
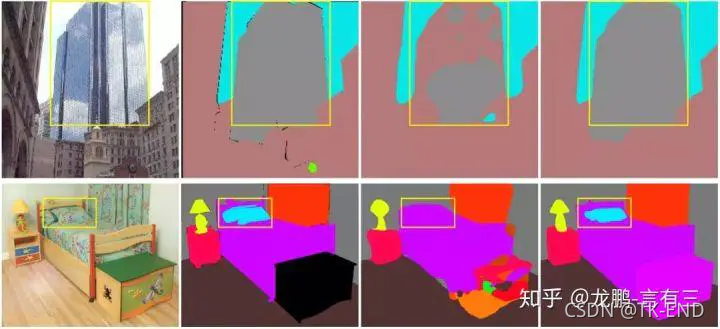
从左到右分别为:图像、真值、FCN结果和PSPNet结果
2 模型结构
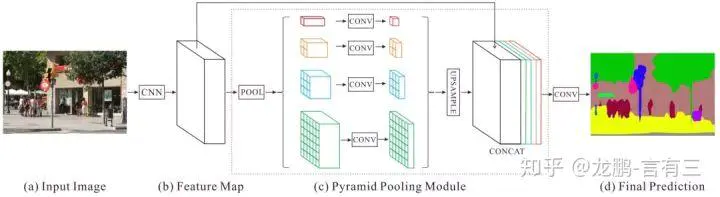
实验中分别用了1x1、2x2、3x3和6x6四个尺寸,最后用1x1的卷积层计算每个金字塔层的权重,再通过双线性恢复成原始尺寸。
最终得到的特征尺寸是原始图像的1/8。最后在通过卷积将池化得到的所有上下文信息整合,生成最终的分割结果。
此外,文中还应用了两个损失函数,分别用于约束主干分割网络和校正网络。以ResNet101为例,损失所处位置如下图所示。
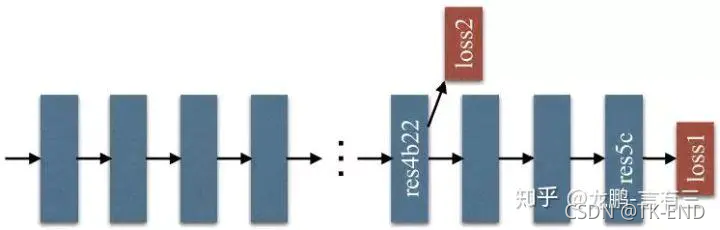
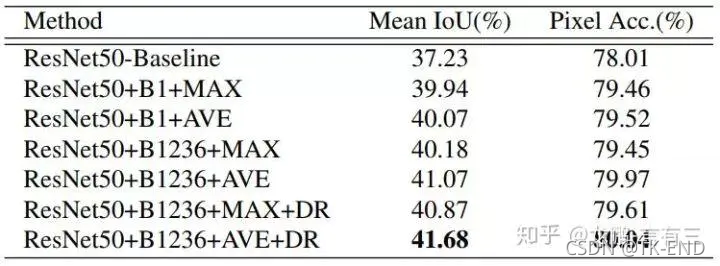
9 Large Kernel Matters
1 分类与定位的矛盾性
- 平移不变性与位置敏感性:
1、对于分类任务,模型需要具有平移不变性,无论关键物体是旋转还是位移缩放,模型都要能保持对目标的激活,从而进行分类。
2、对于定位任务,模型需要对物体的位置非常敏感,需要对物体的每个像素都判断其语义信息,并根据所有像素的语义信息来找到物体的位置,如果模型具有非常好的平移不变性,那就很难以确定物体的具体空间位置,定位的精度也会非常低。
2 解决方法:全卷积+大卷积核
- 1定位: 全卷积网络,因为全局池化和fc层会破坏原图的相关位置信息,而卷积可以保留这些信息。
- 2分类: 使用较大的卷积核(扩大感受野)使特征图和逐像素的分类器之间能够保持密集的连接,而不是通过小卷积核只保留较稀疏的连接。
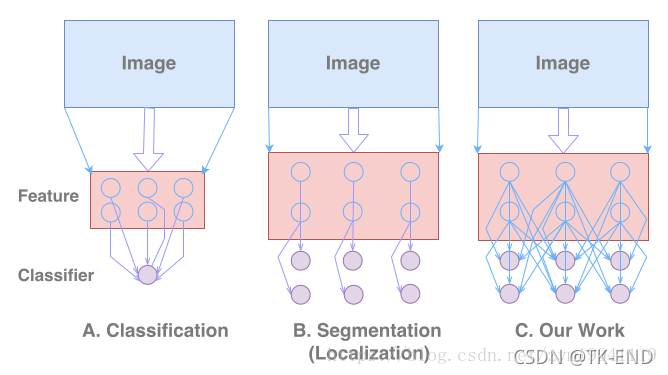
在分类网络中,所有特征都贡献给一个分类器,由分类器判断物体的种类。在传统的分割网络中,逐像素的分类结果由位置与之对应的特征图的特征来确定,特征图与分类结果之间是稀疏连接的,而文章所提出的网络,则是要实现特征图与每个分类结果之间的密集连接,使每一个像素的分类结果都能利用全局信息。
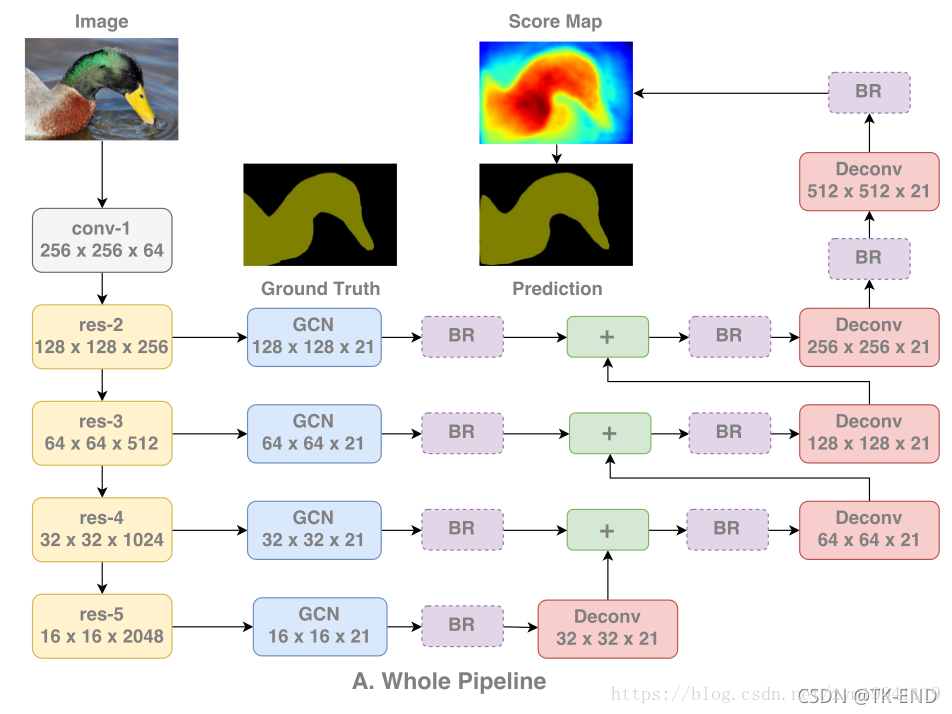
3 提出GCN网络
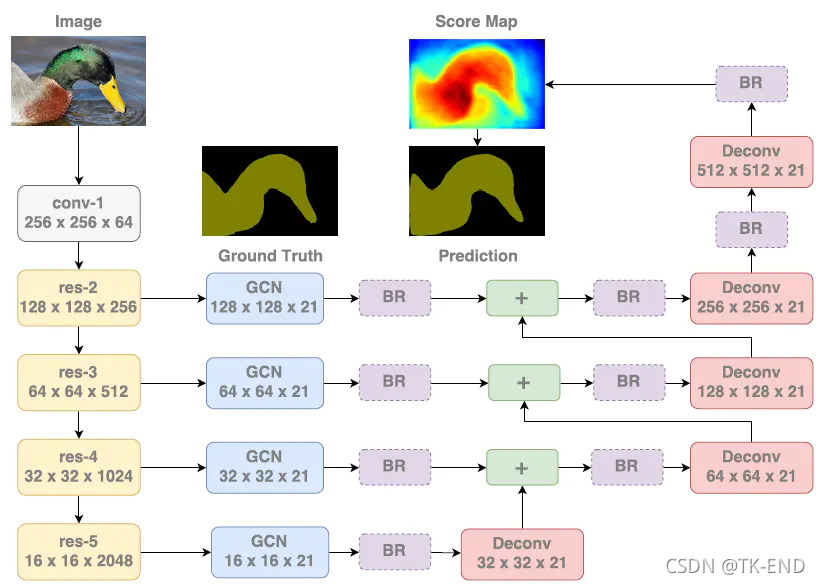
左边是预训练过的ResNet,每一层ResNet块输出的特征图被相应的GCN提取,经过BR(Boundary Refinement)形成score maps,低分辨率的score maps会被上采样,然后与更高层的score maps相加形成新的score maps,最终的score map是经过最后的上采样所形成的,并且被用作输出的预测结果。
1 GCN模块
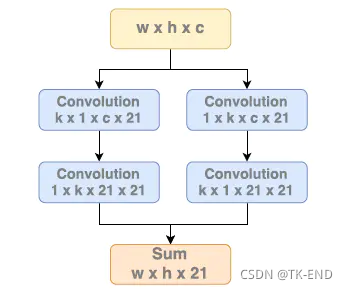
为减小参数量,将kxk的卷积核分解为两个1xk与kx1,并且中间不使用ReLU等激活函数
2 残差(Boundary Refinement)细化边界
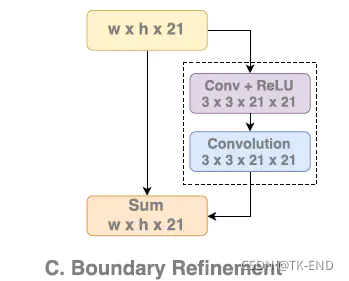
- 细化原理:
BR中的两个卷积层作为残差支路,学习到的是输出heatmap和输入heatmap之间的残差,对于某类物体的中间部位,heatmap的激活值已经很高了,过softmax之后的概率值也会非常大,而边缘位置相对于中心位置的激活值就要低很多,概率值也会低一些,这样在与ground-truth计算loss的时候,边缘部分的loss也会远大于中间部分,于是网络就会促使这两层卷积层去学习寻找边缘,得到的heatmap也会是边缘激活值高中间低,最终与原来的heatmap相加,就可以起到提高边缘激活值,锐化边缘的作用。
4 后续结论
在后续的实验中,文章发现了以下几个结论:
- 普通的大卷积核会使网络难以收敛,但GCN则不会
- 随着GCN中k值的增加,网络的性能越来越好,而普通卷积与堆叠3x3卷积在k>5之后性能均会下降
- GCN的确提升了物体内部的分割精度但对边缘精度没有什么影响,而BR的确提升了物体边缘的分割精度
附录
1 分割网络常用方法
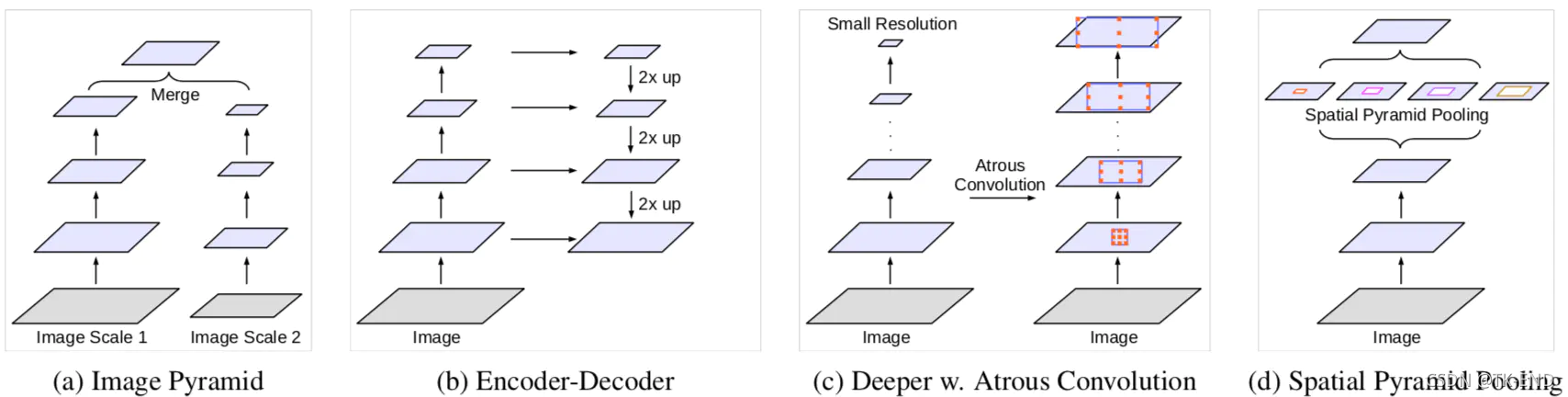
一、二、三、四如图所示
- 一: 把输入图片缩放成不同尺度,经过同一个网络,最终融合多尺度下的物体信息
- 二: 使用编解码结构,在decoder时融合encoder网络不同阶段的特征,U-net, mask-rcnn,refinenet
- 三: 在原网络最后层增加额外的context模块,比如DenseCRF,或者串联几个不同感受野的卷积模块
- 四: 在原网络最后层添加并行结构—空间金字塔池化,获取不同尺度的物体信息 ,比如PSPNet
- 五: 减少网络中stride的个数,使用空洞卷积等获得相同感受野,得到较大尺寸的特征图,使模型定位效果更优秀。
2 分割基础小知识:
- 1 分类与定位任务互相矛盾。
分类:平移不变性
分割:位置敏感性
- 2 相同理论感知野下,小卷积核堆叠的参数量会小于直接使用大卷积核。但CNN实际感受野其实小于理论感受野。
- 3 深层、浅层特征
所有层次特征都有助于语义分割。高层次的语义特征有助于图像区域的类别识别,而低层次的视觉特征有助于生成清晰、详细的边界,用于高分辨率预测。
3 感知野计算
1 计算公式
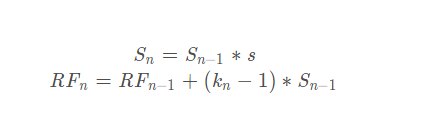
- Sn: 前n层的步长(stride) 之积
- s: 第n层的步长
- Sn-1: 前n-1层的步长(stride)之积
- RFn: 第n层的感知野
- RFn-1:第n-1层的感知野
- Kn: 第n层卷积核大小
如果使用空洞卷积,则其卷积核大小公式变为
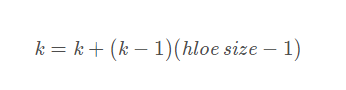
2 为什么要保证感知野大小不变
使用预训练模型,一是使用其网络结构,二是使用训练好的权重来进行初始化。
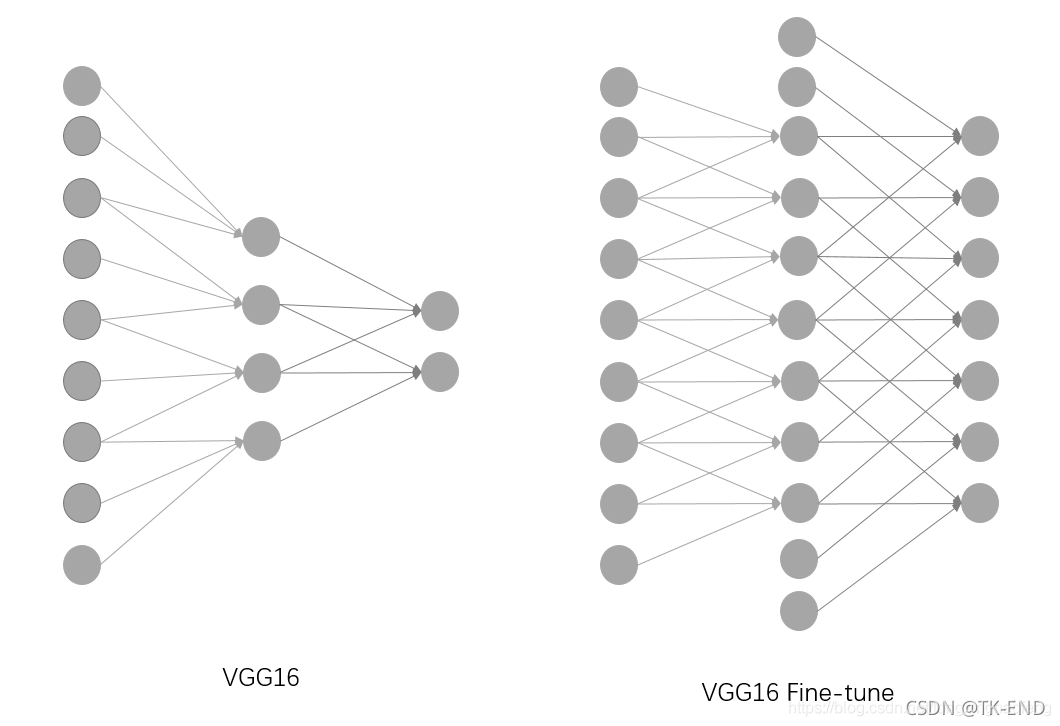
如图所示,这里我们对网络结构进行了微调,增加了一些网络节点,并且保证感知野大小不变。
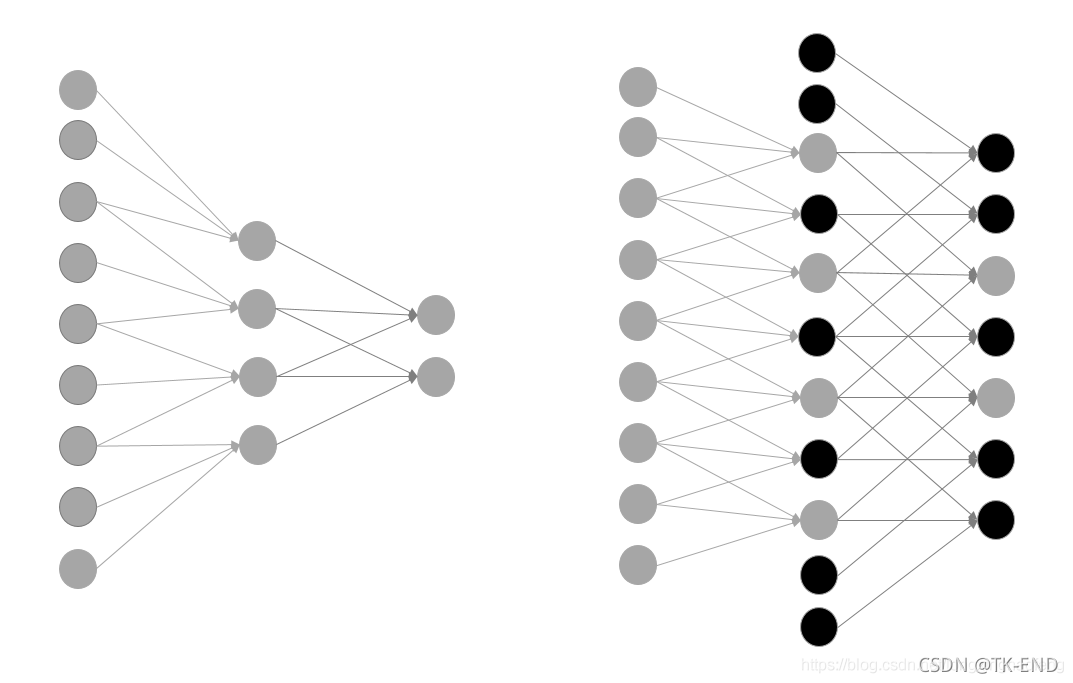
如右侧图像所示,只需要在新增加的节点处初始化为0(黑色节点),就可以使用预训练好的权重进行初始化。
4 评价指标
1 AP AR PA IOU
分割是像素点的分类问题,TP FP TN FN都是基于像素而言。
-
IOU
交并比 ,主要判断单图 -
MIOU :
基于类别的均交并比
MIOU=每个分类得出的分数进行平均一下
- FWIoU,
Frequency Weighted Intersection over Union(频权交并比)
为MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
- AP
Average Precision 平均精度
P = TP/(TP+FP)
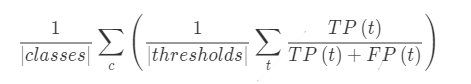
- AR
召回率 R = TP/(TP+FN)
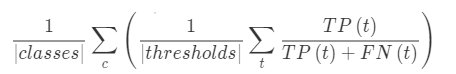
-
Accuracy(PA)
准确率 accuracy = (TP+TN)/(TP+TN+FP+FN)
即PA(Pixel Accuracy)像素精度 标记正确的像素占总像素的比例(计算所以类别)表示检测物体的准确度,重点判断标准为是否检测到了物体
IoU只是用于评价一幅图的标准,如果我们要评价一套算法,并不能只从一张图片的标准中得出结论。一般对于一个数据集、或者一个模型来说。评价的标准通常来说遍历所有图像中各种类型、各种大小(size)还有标准中设定阈值.论文中得出的结论数据,就是从这些规则中得出的。 -
MPA
mean pixel accuracy 平均像素准确率
MPA是对PA的改进,计算每个类内被正确分类像素数的比例,之后求所有类的平均
2 RQ SQ PQ
- RQ :(recognition quality)识别质量
- SQ : (segmentation quality)分割质量
- PQ : Panoptic Quality)全景质量:进一步评估分割和识别环节的表现
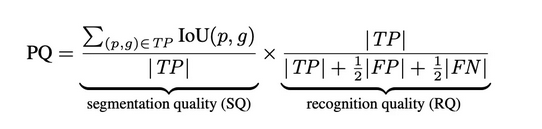
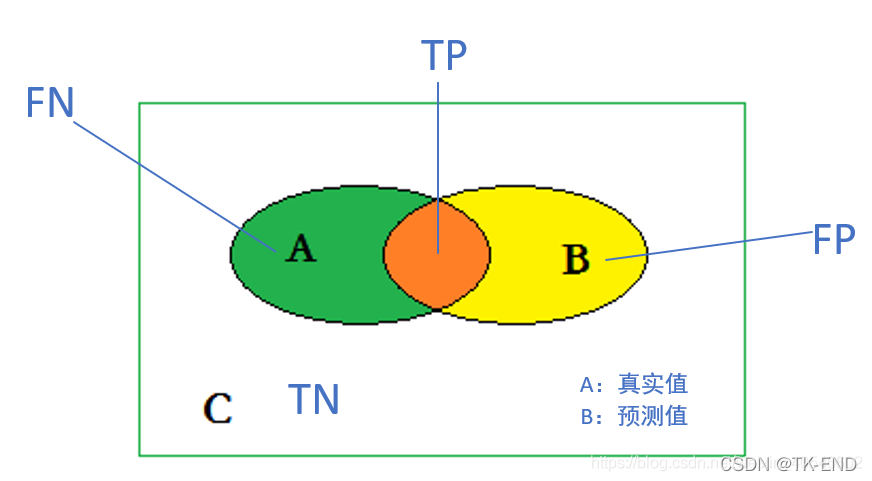
IoU(p,g)是预测的分割p和GroundTruth g的交并比, TP是指IoU>阈值(一般是0.5)的分割结果,FP (False Positives),和FN (False Negatives)如下图所示:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









