







 本文探讨了如何利用大规模语言模型如ChatGPT,在零样本条件下改进信息抽取任务。作者提出了一种多阶段方法,包括类型识别和链式信息抽取,通过多轮交互式问答获取结构化数据。实验结果展示了在PaddleNLPLIC2021EE和Text2event等数据集上的性能。
本文探讨了如何利用大规模语言模型如ChatGPT,在零样本条件下改进信息抽取任务。作者提出了一种多阶段方法,包括类型识别和链式信息抽取,通过多轮交互式问答获取结构化数据。实验结果展示了在PaddleNLPLIC2021EE和Text2event等数据集上的性能。

1、写作动机:
近来的大规模语言模型(例如Chat GPT)在零样本设置下取得了很好的表现,这启发作者探索基于提示的方法来解决零样本IE任务。
2、主要贡献:
提出了基于chatgpt的多阶段的信息抽取方法:在第一阶段找出可能存在于句子中的相应元素类型。然后在第二阶段,对第一阶段中的每个元素类型执行链式信息抽取。每个阶段都采用了多轮QA过程。在每一轮中,基于设计的模板和先前提取的信息构造提示,作为输入向ChatGPT提问。最后,将每一轮的结果组合成结构化数据。
3、方法:
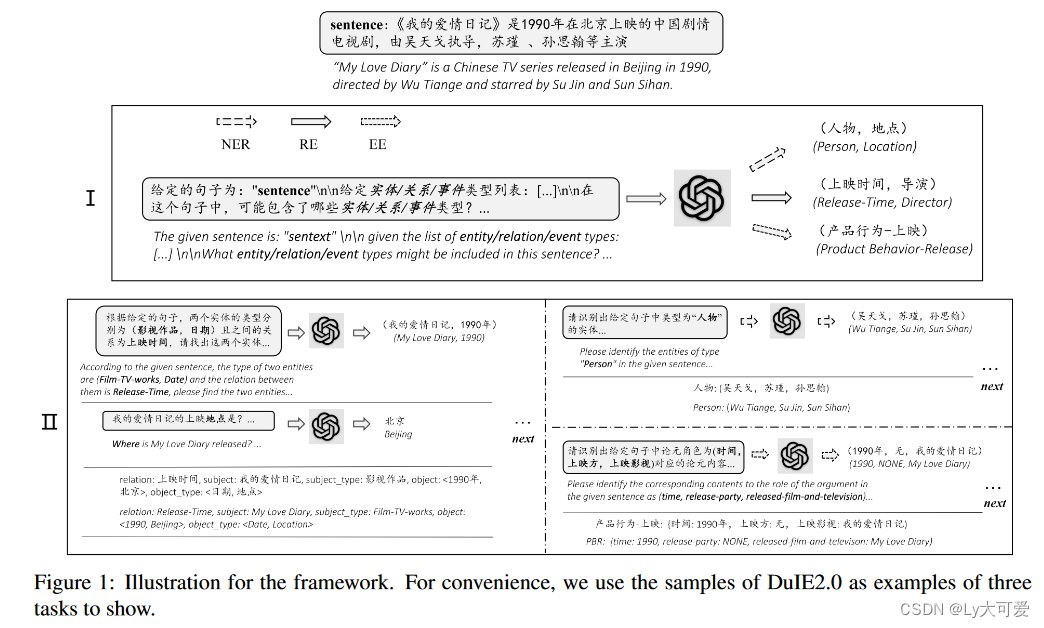

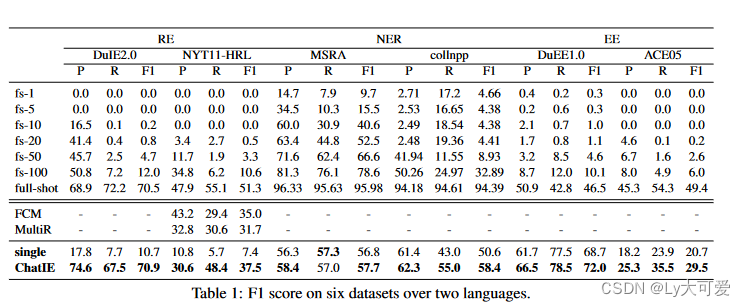
4、实验结果:
PaddleNLP LIC2021 EE、 Text2event


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









