







 本文首次探讨了如何有效利用LLMs进行知识图谱(KG)推理,提出知识前缀适配器KoPA,通过整合KG结构信息增强LLM的推理能力。实验在多个数据集上验证了这种方法,包括医学知识图谱UMLS等。
本文首次探讨了如何有效利用LLMs进行知识图谱(KG)推理,提出知识前缀适配器KoPA,通过整合KG结构信息增强LLM的推理能力。实验在多个数据集上验证了这种方法,包括医学知识图谱UMLS等。
1、写作动机:
关于LLM-based KGC的研究有限,并且缺乏对LLM推理能力的有效利用,这忽视了KGs中重要的结构信息,阻碍了LLMs获取准确的事实知识。
2、主要贡献:
1)是第一个全面探讨利用LLMs进行KGC的工作,具体通过将KG结构信息整合到LLMs中以增强LLM推理。
2)提出了知识前缀适配器(KoPA),它有效地将预训练的KG结构embedding与LLMs整合。
3、KoPA的架构:
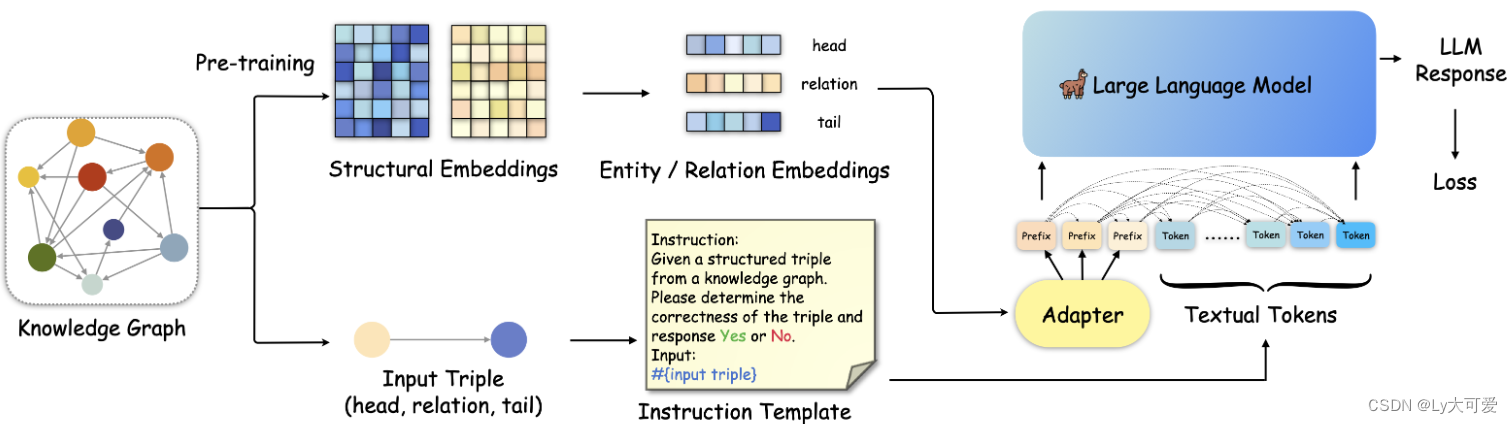
KoPA的设计分为两个部分。首先,通过结构embedding预训练从KG中提取实体和关系的结构信息,然后通过结构前缀适配器将这些结构信息注入到输入序列S中。LLM M进一步通过注入结构的序列进行微调。
3.1结构embedding预训练:
对于每个实体 𝑒 ∈ E 和每个关系 𝑟 ∈ R,分别学习结构embedding 𝒆 ∈ R𝑑𝑒,𝒓 ∈ R𝑑𝑟,其中 𝑑𝑒,𝑑𝑟 是嵌入维度。定义一个得分函数F(ℎ, 𝑟, 𝑡)来衡量三元组(ℎ, 𝑟, 𝑡)的合理性。采用了通过负采样的自监督预训练目标:
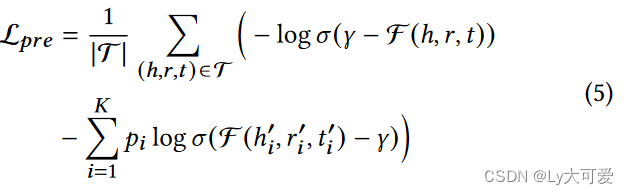
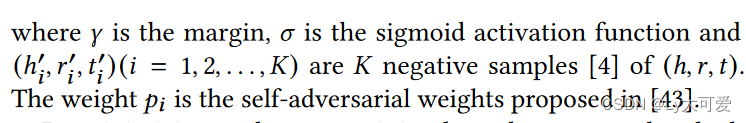
通过最小化这样的预训练损失,每个实体和关系的结构embedding被优化以适应其所有相关三元组,从而捕获KG的结构信息,如子图结构和关系模式。
3.2知识前缀适配器KoPA:
用知识前缀适配器P将3.1中学到的结构embedding投影到LLM的文本标记表示空间中。具体来说,通过P将结构嵌入转换为几个虚拟知识tokenK:
![]()
在实践中,适配器P可能是一个简单的投影层。然后,将K放在原始输入序列S的前面,作为指令和三元组文本提示S的前缀:
![]()
这样,由于在解码器中仅有单向注意力,所有后续文本标记都可以看到前缀K。通过这样做,文本标记可以单向关注输入三元组的结构embedding。这样的结构感知提示将在微调和推断过程中使用。
4、实验:
数据集:
使用三个公共知识图谱基准:UMLS (一个医学知识图谱)、CoDeX-S]和 FB15K-237N ,来评估提出的基于LLM的KGC方法的能力。
微调方法:Lora
backbone:LLaMA、Alpaca
4.1主要结果:
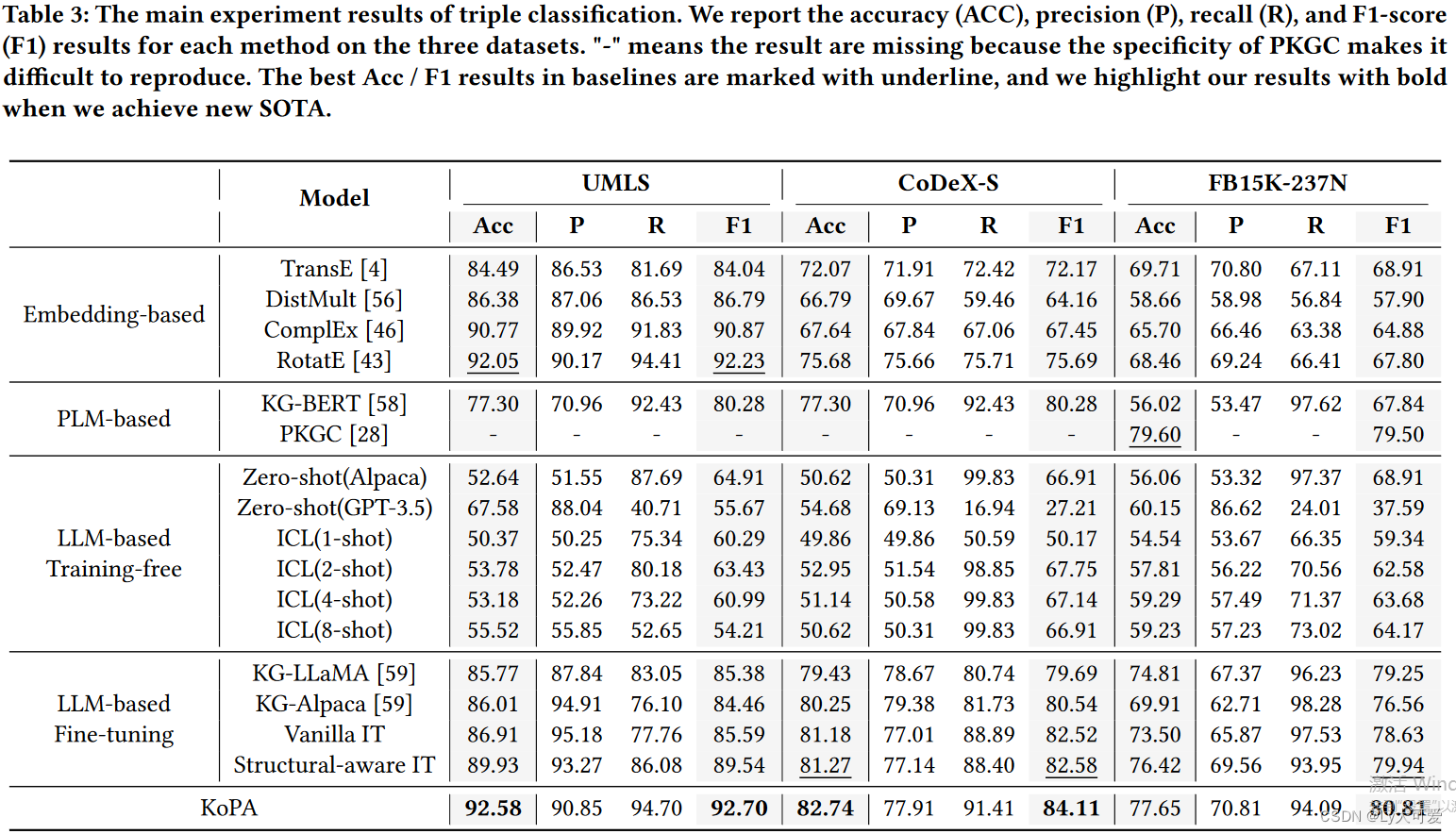
4.2消融实验:
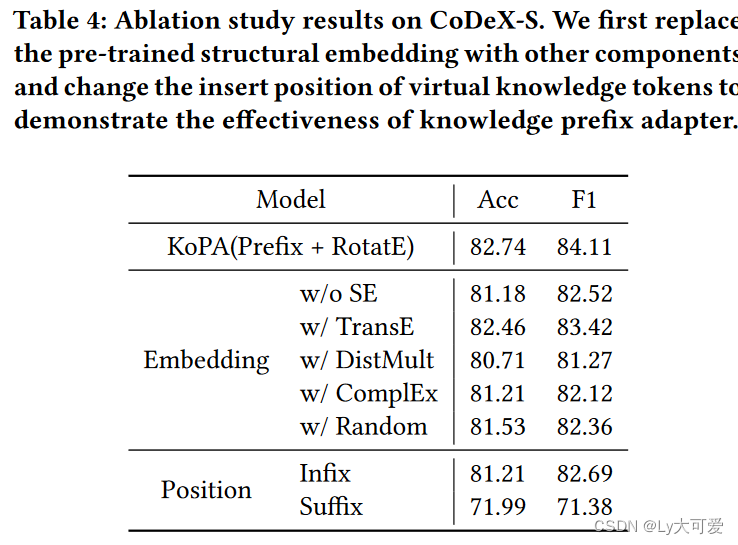
4.3案例研究:
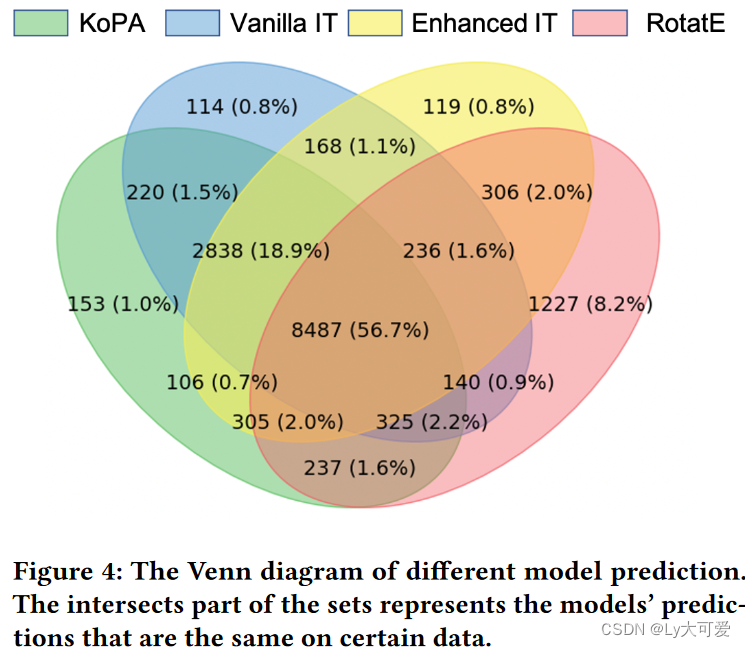
5、局限性:
目前,尚未将该模型方法推广到所有类型的KGC任务,如实体预测和关系预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









