







 本文详细介绍了如何在集群环境中部署Hive,包括原生的Derby数据库和使用MySQL作为元数据存储的两种方式。在过程中,提到了遇到的MySQL安装、权限配置等问题及其解决方案,最后成功启动Hive并进行数据库操作。
本文详细介绍了如何在集群环境中部署Hive,包括原生的Derby数据库和使用MySQL作为元数据存储的两种方式。在过程中,提到了遇到的MySQL安装、权限配置等问题及其解决方案,最后成功启动Hive并进行数据库操作。

一、hive安装----原生的数据库(可以简单的练手)
-
上传安装包
用xshell上传安装包

-
解压软件包
[root@node01 softwares]# tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /export/servers/
指定安装到目录 /export/servers/目录下查看一下:

-
进入hive这个目录,修改配置文件
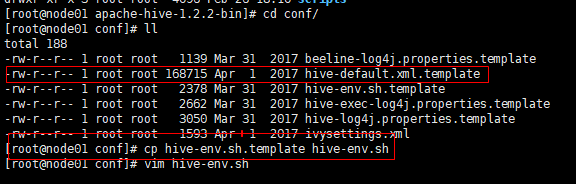
修改hive-env.sh.template—>直接复制一份叫hive-env.sh
**[root@node01 conf]# cp hive-env.sh.template hive-env.shvim hive-env.shl编辑
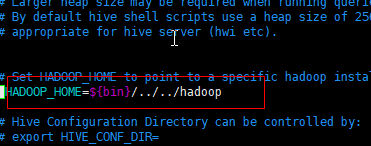
修改这一项,把注释#去掉,然后加上hadoop的绝对路径
/export/servers/hadoop-2.6.0-cdh5.14.0(绝对路径–>pwd)
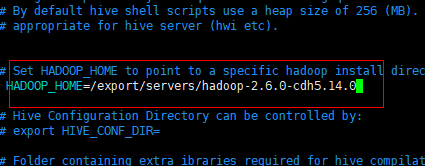
然后保存退出 -
用原生的hive的derby存放元数据–>不配置hive-site.xml
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









