







 本文深入探讨了机器学习中的朴素贝叶斯算法和Logistic回归。通过贝叶斯准则解释了朴素贝叶斯的核心思想,并展示了如何应用于侮辱性言论过滤器。接着,文章介绍了Logistic回归,讲解了Sigmoid函数和梯度上升法,以及在实际问题中的应用,如RSS源分类和垃圾邮件检测。
本文深入探讨了机器学习中的朴素贝叶斯算法和Logistic回归。通过贝叶斯准则解释了朴素贝叶斯的核心思想,并展示了如何应用于侮辱性言论过滤器。接着,文章介绍了Logistic回归,讲解了Sigmoid函数和梯度上升法,以及在实际问题中的应用,如RSS源分类和垃圾邮件检测。
朴素贝叶斯
| 朴素贝叶斯 |
|---|
| 优点:在数据较少的情况下仍然有效,可以处理多类别问题 |
| 缺点:对于输入数据的准备方式较为敏感 |
| 适用数据类型:标称型数据 |
| 朴素贝叶斯的一般过程 |
|---|
| 1.收集数据:可以使用任何方法 |
| 2.准备数据:需要数值型或者布尔型数据 |
| 3.分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好 |
| 4.训练算法:计算不同的独立特征的条件概率 |
| 5.测试算法:计算错误率 |
| 6.使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本 |
- 贝叶斯准则:
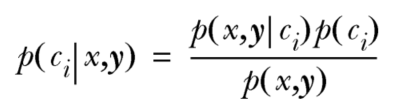
贝叶斯准则是整个算法的核心思想
 注意:由于每个p()的分母都相同,所有比较时只需比较分子即可
注意:由于每个p()的分母都相同,所有比较时只需比较分子即可
例:侮辱性言论过滤器
准备数据:从文本中构建词向量
- 词表到向量的转换函数:
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
def createVocabList(dataSet):
vocabSet = set([]) #create empty set
for document in dataSet:
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec下面测试上面的函数
listOPosts,listClasses = bayes.loadDataSet()
myVocaList = bayes.createVocabList(listOPosts)
print(myVocaList)
print(bayes.setOfWords2Vec(myVocaList,listOPosts[0]))
print(bayes.setOfWords2Vec(myVocaList,listOPosts[3]))输出结果:
['take', 'mr', 'so', 'I', 'not', 'flea', 'stop', 'worthless', 'how', 'my', 'buying', 'problems', 'food', 'has', 'ate', 'is', 'park', 'dalmation', 'maybe', 'garbage', 'licks', 'help', 'love', 'please', 'him', 'cute', 'quit', 'to', 'posting', 'stupid', 'steak', 'dog']
[0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1]
[0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0]训练算法:从词向量计算概率
下面拓展重写贝叶斯准则,将之前的x、y替换为w。w表示一个向量,它由多个数值组成。
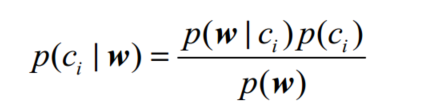
其中p(ci)可以通过类别 i (侮辱性留言或非侮辱性留言)中文档数除以总的文档数来计算;计算p(w|ci)就要用到朴素贝叶斯假设:将w展开为一个个独立特征,那么就有p(w|ci)=p(w0,w1,w2…wn|ci)=p(w0|ci)p(w1|ci)p(w2|ci)…p(wn|ci),从而简化计算。

- 朴素贝叶斯分类器训练函数(函数伪代码的实现):
def trainNB0(trainMatrix,trainCategory): #trainMatrix是某个文档矩阵(例如下面测试时的trainMat);trainCategory是某个类别标签的集合(像是classVec)
numTrainDocs = len(trainMatrix) #训练文档数
numWords = len(trainMatrix[0]) #特征个数
pAbusive = sum(trainCategory)/float(numTrainDocs) #p(1)
p0Num = ones(numWords); p1Num = ones(numWords) #change to ones()
p0Denom = 2.0; p1Denom = 2.0 #change to 2.0
for i in range(numTrainDocs): #遍历文档集合
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #change to log()
p0Vect = log(p0Num/p0Denom) #change to log()
return p0Vect,p1Vect,pAbusive下面测试函数:
listOPosts,listClasses = bayes.loadDataSet()
myVocaList = bayes.createVocabList(listOPosts)
trainMat=[] #创建一个空的文档矩阵
for postinDoc in listOPosts: #遍历文档集合
trainMat.append(bayes.setOfWords2Vec(myVocaList,postinDoc))
p0V,p1V,pAb=bayes.trainNB0(trainMat,listClasses)
print(pAb)
print(p0V)
print(p1V)输出结果:
0.5 #pAb
[-3.25809654 -2.56494936 -3.25809654 -1.87180218 -2.56494936 -2.56494936
-3.25809654 -2.56494936 -3.25809654 -2.56494936 -3.25809654 -2.56494936
-2.56494936 -3.25809654 -2.56494936 -3.25809654 -2.56494936 -2.56494936
-3.25809654 -3.25809654 -2.56494936 -2.56494936 -2.15948425 -3.25809654
-2.56494936 -2.56494936 -2.56494936 -2.56494936 -2.56494936 -2.56494936
-3.25809654 -2.56494936] #p0V
[-2.35137526 -3.04452244 -2.35137526 -3.04452244 -3.04452244 -3.04452244
-2.35137526 -3.04452244 -2.35137526 -3.04452244 -2.35137526 -3.04452244
-3.04452244 -2.35137526  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









