






文件操作
说明:本blog绝大部分内容来自于Python数据分析与可视化(清华大学出版社,魏伟一,李晓红),仅用于 自己学习使用。
文件处理过程
(1)打开文件:open()函数
(2)读取/写入文件:read()、readline()、readlines()、write()等
(3)对读取到的数据进行处理
(4)关闭文件:close()
一.open()函数
file_object=open(file_name[,access_mode=“r”,buffering=-1])
file_object: 打开的文件对象;
file_name: 要打开文件名的绝对路径/相对路径的字符串,包含路径名及拓展名;
access_mode: 可选参数,打开模式,默认r(只读),此外还有w(只写)和a(追加);
buffering: 待打开文件的缓冲模式
二.数据的读取
| 方法 | 功能 |
|---|---|
| read([size]) | 读取文件所有内容,返回类型为字符串;参数size表示读取的数量,以byte为单位,可省略 |
| readline([size]) | 读取文件一行内容,返回类型为字符串;若定义了size则读出一行的一部分内容 |
| readlines([size]) | 读取所有的行到列表中,其中每一行即为list的一个成员,[line1,line2,…linen],参数size表示读取内容的总长 |

eg1:读取txt文件
书中代码:
file=open("泰戈尔的诗.txt",mode='r')
content=file.read()
print(content)
file.close()
原本按照书中这样写,运行却出现了两个问题:
①读取不到文件,因为没有保存到python我所指定的路径下,所以出现了读取失败的情况;
②添加到指定路径下后,又出现’gbk’ codec can’t decode byte 0x80 in position 92: illegal multibyte sequence错误,查阅了一下,知道了是因为文件的编码问题引起的,需要添加encoding=‘UTF-8’。
修改后:
file=open("泰戈尔的诗.txt",mode='r',encoding='UTF-8')
content=file.read()
print(content)
file.close()
运行结果:
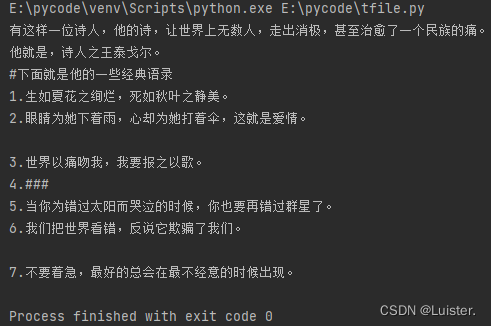
eg2:读取txt文件时指定读取数量
file=open("泰戈尔的诗.txt",mode='r',encoding='UTF-8')
content=file.read(10)#设置读取内容的长度size
print(content)
file.close()
print(type(content))
运行结果:
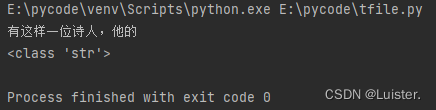
eg3:按行读取文件
file=open("泰戈尔的诗.txt",mode='r',encoding='UTF-8')
content=file.readlines()
print(content)
file.close()
print(type(content))
运行结果:

注:
①readlines()读取后得到的是每行数据组成的列表,一行样本数据全部存储为一个字符串,换行符也未去掉;
②每次用完文件后,都要关闭文件,否则文件就会一直被Python占用,不能被其他进程使用;
③可以使用with open() as f 语句来解决②中的问题,它会在操作后自动关闭文件。
三.读取CSV文件
CSV文件:字符分隔值(Comma Separated Values,CSV)文件,因为分隔符除了是逗号,还可以是制表符.它是一种常用的文本格式,用于存储表格数据,包括数字或字符。
CSV文件的特点:
①纯文本,使用某个字符集,例如ASCII、Unicode或GB2312;
②以行为单位读取数据,每行为一条记录;
③而每条记录又被分隔符分隔,成为字段;
④对于每条记录,都有同样的字段序列。
Python中内置了csv模块,import csv之后就可读取CSV文件了
eg:读取CSV文件
关于创建csv文件,首先在excel中完成内容的撰写,然后另存为csv格式,最后将其保存到python运行的路径中,方便程序运行时读取。
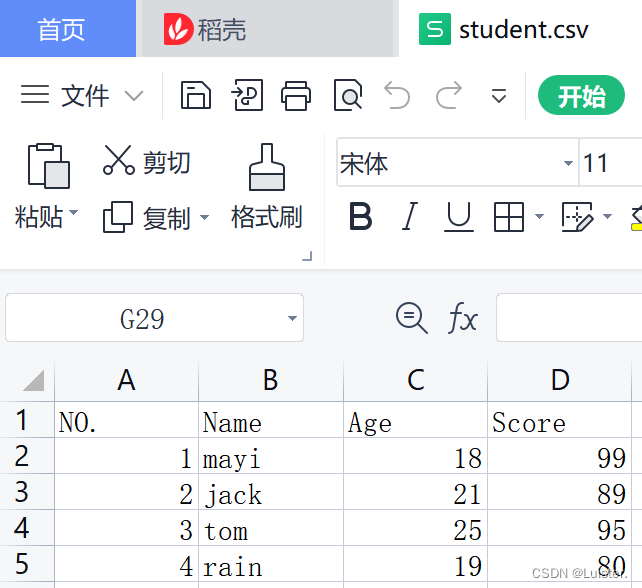
import csv
with open("student.csv","r") as f:
reader=csv.reader(f)
rows=[row for row in reader]
for item in rows:
print(item)
运行结果:
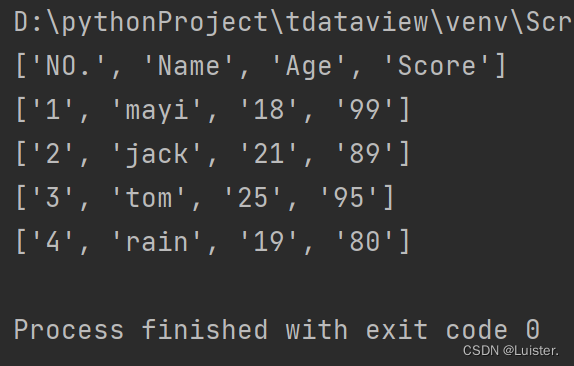
四.文件写入与关闭
1.文件的写入
①使用write()函数,用于向文件中写入指定字符串,同时需要将open()函数中文件打开的参数设置为mode=“w”;
②write()是逐次写入,writelines()可将一个列表中所有的数据一次性写入文件;
③如果有换行需要,则要求在每条数据后边增加换行符,同时使用“字符串.join()“方法将每个变量数据联合写成一个字符串,并增加间隔符”\t";
④对于写入CSV文件的writer方法,可以调用writerow函数将列表中的每个元素逐行写入文件。
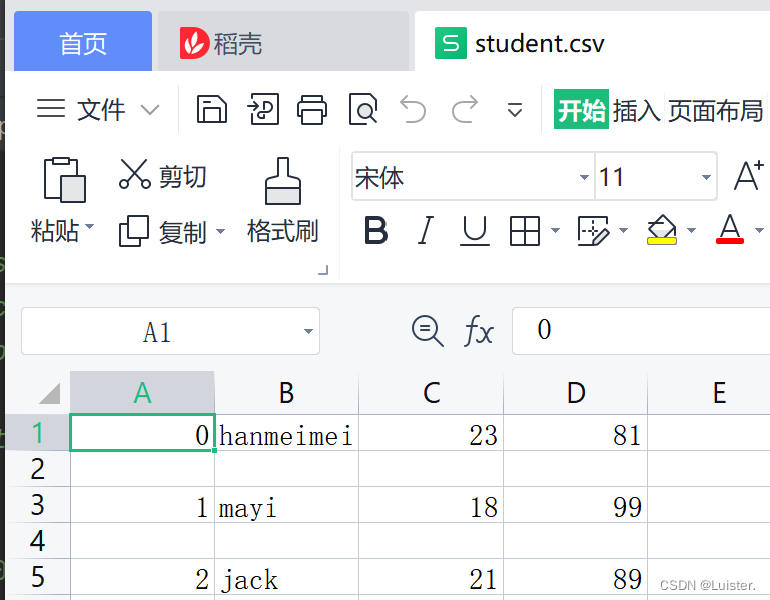
import csv
content=(['0','hanmeimei','23','81'],['1','mayi','18','99'],['2','jack','21','89'])
f=open("test.csv","w",newline='')
content_out=csv.writer(f)
for con in content:
content_out.writerow(con)
f.close()
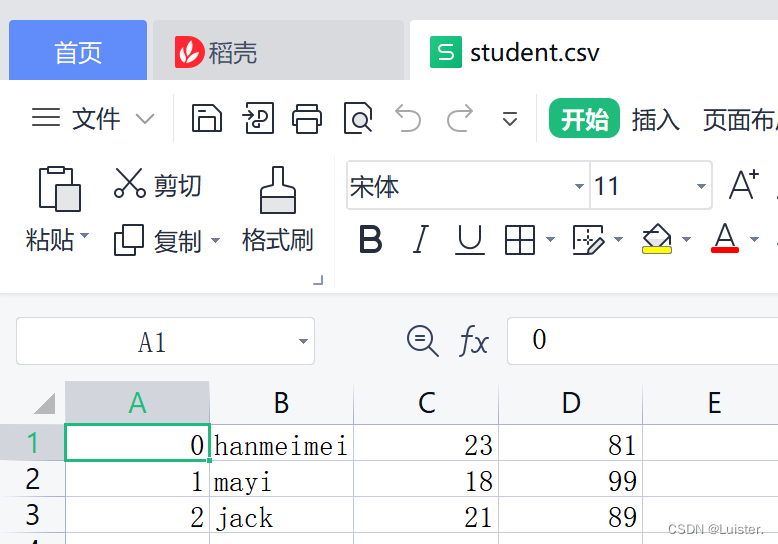
import csv
content=(['0','hanmeimei','23','81'],['1','mayi','18','99'],['2','jack','21','89'])
f=open("test.csv","w")#不加newline='',会出现空行
content_out=csv.writer(f)
for con in content:
content_out.writerow(con)
f.close()
2.关闭文件
eg:跳过文件中的注释内容和缺失值
补充:strip()函数,移除字符串头尾指定的字符序列,返回移除字)符串头尾指定的字符生成的新字符串。
详情见:link

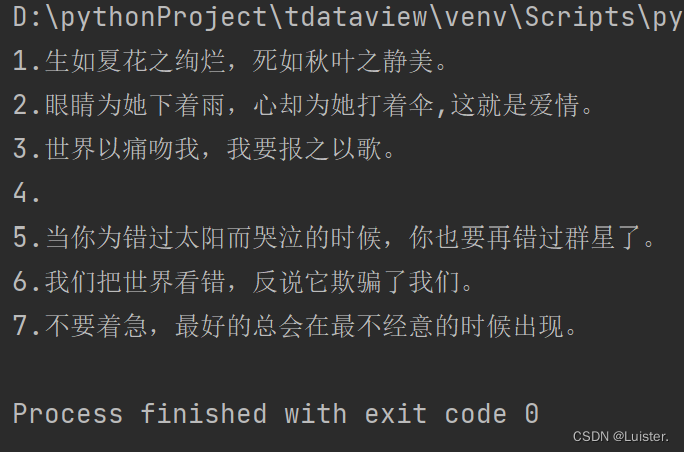
def skip_header(f):
line=f.readline()
while line.startswith('#'):
line=f.readline()
return line
def process_file(f):
#调用函数使其跳过文件头部
line = skip_header(f).strip()
for line in f:
if line.startswith("-") or line.startswith("#"):
line=f.readline()
line=line.strip()#去除空行
line=line.strip("#")#去除行中的"#"号
print(line)
if __name__=="__main__":
input_file=open("泰戈尔的诗.txt",'r',encoding='UTF-8')
process_file(input_file)
input_file.close()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









