







 本文全面复习了HBase的基础知识,包括HBase的数据模型、与传统数据库的区别、分布式架构及其读写流程。重点讲解了HBase的行键、列族、时间戳的概念,以及HBase在NoSQL数据库中的特性。此外,还介绍了如何在HBase Shell中进行常用操作,并通过Java API展示了HBase的数据操作代码示例。
本文全面复习了HBase的基础知识,包括HBase的数据模型、与传统数据库的区别、分布式架构及其读写流程。重点讲解了HBase的行键、列族、时间戳的概念,以及HBase在NoSQL数据库中的特性。此外,还介绍了如何在HBase Shell中进行常用操作,并通过Java API展示了HBase的数据操作代码示例。
HBase总复习
一、基础知识记忆
1、非关系型数据库又被称为NoSQL (Not Only SQL ),NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。
2、NoSQL的四大类型
1)键值数据库 2)列族数据库 3)文档数据库 4)图形数据库
3、HBase起源于2006年Google发表的BigTable论文
4、HBase是一种构建在HDFS之上的分布式,面向列的存储系统。
5、HBaseShell提供大量操作HBase的命令,通过Shell命令很方便地操作HBase数据库
6、HBase 是面向列的、是分布式的、是一种 NoSQL数据库。
7、HBase 是一个类似BigTable的分布式数据库,它是一个稀疏的长期存储的(存储在硬盘上)、多维度的、排序的映射表,这张表的索引是行关键字、列关键字和时间戳,HBase 中的数据都是字符串,没有类型。
8、HBase表中的单元格是由行,列族,列标识符,值和代表值版本的时间戳组成。
9、HBase同样是主从分布式架构,它隶属于Hadoop生态系统,由以下组件组成:Client,ZooKeeper, HMaster, HRegionServer 和HRegion;在底层, 它将数据存储于HDFS中
10、HBase 将数据以Hfile的形式存放在HDFS中。.
11、HBase 依赖Zookeeper提供消息通信机制。
12、HBase 集群部署完成后,执行start-hbase. sh命令,启动HBase集群,执行hbase shell 命令,进入HBase Shell 交互界面。
13、在老版本中,客户端首次查询HBase数据库时,需要从- ROOT-表开始查找,新版本需要从. META开始查询
14、当MemStore存储的数据达到-一个默认阈值128M时的,MemStore 里面的数据就会被flush到StoreFile文件。
15查看HBase中存在哪些表的shell命令为list,查看当前HBase的版本信息的shell命令为version。
16、HBase表的数据按照行键RowKey的字典序进行排列,并且切分多个HRegion存储。每个Region存储的数据是有限的,当Region增大到-一个阀值( 128M)时,会被等分切成两个新的Region。一个HRegionServer.上可以存储多个Region。每个Region也只能被分布到1个HRegion Server上。
17、Client 通过ZooKeeper、“-ROOT-” 表及“. META.”表查找到目标数据所在的RegionServer地址。Client通过请求RegionServer地址来查询目标数据。RegionServer定位到目标数据所在的Region,然后发出查询目标数据的请求。Region先在MemStore中查找目标数据,找到则返回;找不到,继续在StoreFile中查找。.
18、HBase分布式数据库的特点:容量大、面向列、数据多版本、稀疏性、可扩展性、高可靠性、高性能和数据类型单一。
19、HBase 中RowKey表示行键,每个HBase表中只能有-一个行键。RowKey 在HBase中以字典排序的方式存储。在HBase内部,RowKey保存为字节数组。
20、HBase 与RDBMS的区别在于: HBase的Cell (每条数据记录中的数据项)是具有版本描述的,行是有序的,列在所属列族存在的情况下,由客户端自由添加。
二、知识简答
1、HBase 的数据模型
(1) RowKey: 表示行键,每个HBase表中只能有一个行键,它在HBase中以字典序的方式存储。由RowKey是HBase表的唯一标识, 因此Row Key的设计非常重要。
(2) Column (列): HBase表的列是由列族名、限定符以及列名组成的,其中":"为限定符。创建HBase表不需要指定列,因为列是可变的,非常灵活。
(3) Column Family (列族):在HBase中,列族由很多列组成。在同一个表里,不同列族有完全不同的属性,但是同一个列族内的所有列都会有相同的属性,而属性都是定义在列族上的。
(4) Timestamp ( 时间戳):表示时间戳,记录每次操作数据的时间,通常记作数据的版本号。
(5) Cell (单元格):根据行键、列族和列可以映射到-一个对应的单元格,单元格是HBase存储数据的具体地址。
2、HBase 分布式数据库与传统数据库的区别。
(1) 存储模式:传统数据库中是基于行存储的;而HBase是基于列进行存储的。.
(2) 表字段:传统数据库中的表字段不超过30个;而HBase中表字段不作限制。
(3) 可延伸性:传统数据库中的列是固定的,需要先确定列有多少才会增加数据去存储、而HBase是根据数据存储的大小去动态的增加列,列是不固定的。
3、HBase 架构
(1) Client: 它通过RPC协议与HBase通信。
(2) Zookeeper:即分布式协调服务,在HBase 集群中的主要作用是监控HRegionServer的状态。
(3) HMaster: 即HBase的主节点,用于协调多个HRegion Server, 主要用于监控HRegion Server 的状态以及平衡HRegion Server 之间的负载。
(4) HRegion Server:即HBase的从节点,它包括了多个HRegion,主要用于响应用户的I/0请求,向HDFS文件系统读写数据。
(5) HRegion:即HBase表的分片,每个Region中保存的是HBase表中某段连续的数据。
(6) Store: 每一个HRegion 包含一或多个Store。 每个Store用于管理一个Region_上的一个列族。
(7) MemStore: 即内存级缓存,MemStore 存放在store中的,用于保存修改的数据. (即KeyValues形式)。
(8) StoreFile: MemStore中的数据写到文件后就是StoreFile,StoreFile 底层是以HFile文件的格式保存在HDFS上。
(9) HFile: 即HBase中键值对类型的数据均以HFile文件格式进行存储。
(10) HLog: 即预写日志文件,负责记录HBase修改。当HBase读写数据时,数据不是直接写进磁盘,而是会在内存中保留一段时间。
4、HBase读数据流程

5、HBase写数据流程

三、知识分析解答
1、下面关系表在HBase中的物理模型和逻辑模型。
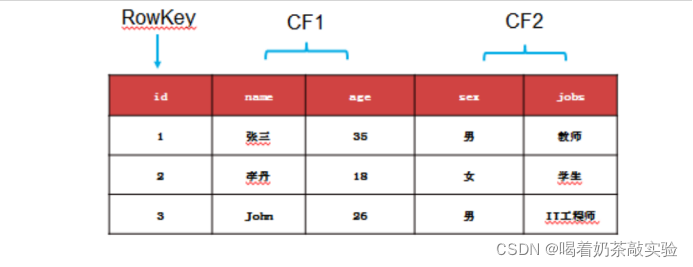
逻辑模型
| RowKey | 列族 CF1 | 列族 CF2 |
| id=1 | CF1:name="张三" | CF2:sex="男" |
| CF1:age="35" | CF2:jobs="教师" | |
| id=2 | CF1:name="李丹" | CF2:sex="女" |
| CF1:age="18" | CF2:jobs="学生" | |
| id=3 | CF1:name="John" | CF2:sex="男" |
| CF1:age="26" | CF2:jobs="IT工程师" |
物理模型
| RowKey | 列 | 单元格 |
|---|---|---|
| id=1 | CF1:name | 张三 |
| id=1 | CF1:age | 35 |
| id=1 | CF2:sex | 男 |
| id=1 | CF2:jobs | 教师 |
| id=2 | CF1:name | 李丹 |
| id=2 | CF1:age | 18 |
| id=2 | CF2:sex | 女 |
| id=2 | CF2:jobs | 学生 |
| id=3 | CF1:name | John |
| id=3 | CF1:age | 26 |
| id=3 | CF2:sex | 男 |
| id=3 | CF2:jobs | IT工程师 |
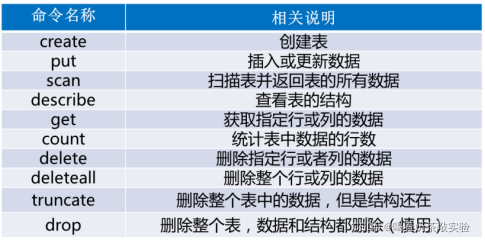
2、在HBase Shell交互界面中,可通过一系列Shell命令操作HBase,下面通过一张表列举操作HBase表常见的Shell命令。
3、写出下面HBase操作的shell命令
(1)创建表,表名为’hbasetest’,列族名为’cf1’、’cf2’;
create 'hbasetest',{NAME => 'cf1'},{NAME => 'cf2'}
(2)创建表,表名为’hbasetest’,列族名为’cf1’、版本数为2
create 'hbasetest', {NAME =>'cf1', VERSIONS=>2}
(3)修改表,表名为’hbasetest’,添加一个列族‘CF3’;
alter 'hbasetest',{NAME => 'CF3'}
(4)向hbasetest表插入一条数据,rowkey 为0001,列族名为’cf1’,列名为’name’,值为’Tom’;
put 'hbasetest','0001','cf1:name','Tom'
(5)对hbasetest表进行全表扫描;
scan 'hbasetest'
(6)删除hbasetest表中rowkey为0001的这行数据;
deleteall 'hbasetest','0001'
(7)删除hbasetest表;
disable 'hbasetest'
drop 'hbasetest'
(8)统计hbasetest表的行数。
count ‘hbasetest’
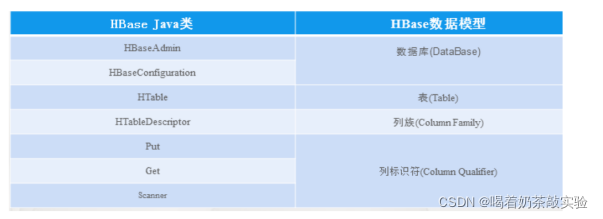
4、HBase 是由Java语言开发的,它对外提供了Java API的接口。
四、编写程序代码:
1、通过HBase Java API接口创建表程序
package com.simple.create;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class CreateTable {
public static void main(String[] args) throws IOException {
//一、配置文件设置
//创建用于客户端的配置类实例
Configuration config = HBaseConfiguration.create();
//设置连接zookeeper的地址
//hbase客户端连接的是zookeeper
config.set("hbase.zookeeper.quorum", "192.168.1.2:2181");
//二、表描述相关信息
//创建表描述器并命名表名为account1
HTableDescriptor< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1855
1855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











