






 本文通过使用sklearn库中的三种朴素贝叶斯模型(高斯、伯努利和多项式)对digits数据集进行分类预测,详细介绍了如何调整平滑参数以优化模型性能。通过绘制不同平滑参数下模型在训练集和测试集上的得分曲线,确定了最佳参数值。
本文通过使用sklearn库中的三种朴素贝叶斯模型(高斯、伯努利和多项式)对digits数据集进行分类预测,详细介绍了如何调整平滑参数以优化模型性能。通过绘制不同平滑参数下模型在训练集和测试集上的得分曲线,确定了最佳参数值。
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
载入数据集并观察数据
digits = load_digits()
digits.keys()
#打印数据描述信息
print(digits.DESCR)
#查看数据形状,每个数据有64个维度
digits.data.shape
#第一张图像的数据
digits.data[0]
建立朴素贝叶斯模型
# 导入三个贝叶斯模型
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import BernoulliNB
from sklearn.naive_bayes import MultinomialNB
#实例化三个模型
bnb = BernoulliNB(alpha=1.0)
mnb = MultinomialNB(alpha=1.0)
gnb = GaussianNB()
#分别采用三个模型对数据进行学习
bnb.fit(X_train,y_train)
mnb.fit(X_train,y_train)
gnb.fit(X_train,y_train)
#查询结果
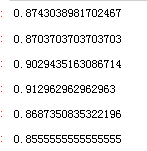
bnb.score(X_train,y_train)
bnb.score(X_test,y_test)
mnb.score(X_train,y_train)
mnb.score(X_test,y_test)
gnb.score(X_train,y_train)
gnb.score(X_test,y_test)
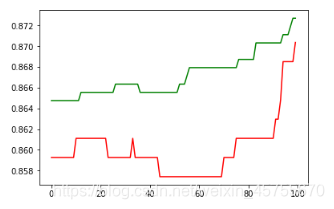
train_score = []
test_score = []
#参数变化从1.0每次减小0.01,减小到0.01
for i in np.arange(1,0,-0.01):
#采用当前遍历的i值作为平滑系数
bnb = BernoulliNB(alpha=i)
#训练模型
bnb.fit(X_train,y_train)
#保存分数
train_score.append(bnb.score(X_train,y_train))
test_score.append(bnb.score(X_test,y_test))
# 训练集上的分数
plt.plot(range(len(train_score)) , train_score , color='green')
# 测试集上的分数
plt.plot(range(len(train_score)) , test_score , color='red');
# 建立一个列表保存结果
train_scores = []
test_scores = []
# 平滑系数的初始值为1
alpha = 1
for i in range(10):
print(alpha)
# 采用当前遍历的i值作为平滑系数
bnb = BernoulliNB(alpha=alpha)
# 模型训练
bnb.fit(X_train , y_train)
# 保存分数
train_scores.append( bnb.score(X_train , y_train) )
test_scores.append(bnb.score(X_test , y_test) )
# 每次对上一次的平滑系数除以10
alpha /= 10
# 训练集上的分数
plt.plot(range(len(train_scores)) , train_scores, color='green')
# 测试集上的分数
plt.plot(range(len(train_scores)) , test_scores , color='red');
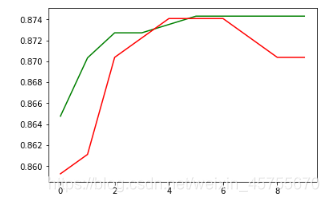
根据图形我们可以得出最优参数的值,进而优化我们的算法.
多项式贝叶斯和高斯贝叶斯的调参方法基本相同,高斯贝叶斯的平滑参数为:var_smoothing.
第一次写没有什么经验,各位大佬有什么指点的可以留言,谢谢!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









