







 这篇博客探讨了使用Logistic回归、线性回归、岭回归、Lasso、SVM和CART回归树对医疗保险花费进行预测的问题。通过比较模型的MSE、RMSE和耗时,发现CART回归树在预测效果和效率上表现最优。
这篇博客探讨了使用Logistic回归、线性回归、岭回归、Lasso、SVM和CART回归树对医疗保险花费进行预测的问题。通过比较模型的MSE、RMSE和耗时,发现CART回归树在预测效果和效率上表现最优。
概述
使用多种方法针对医疗保险花费insurance进行回归分析,比较各方法的差异。
.
数据介绍
数据基于医疗保险背景,文件insurance.csv包含了1338名患者(即保险受益人)的个人信息,包括年龄、性别、BMI、家中孩子数量、是否吸烟、居住地,以及医保对其个人的医疗花费。
数据来源为:https://www.kaggle.com/mirichoi0218/insurance
.
热编码
观察源数据,结构比较简单,并且没有缺失值。
但是有三个变量比价特殊:
sex:有male和female两种取值
smoker:yes、no两种
region:northeast、northwest、southeast、southwest四种
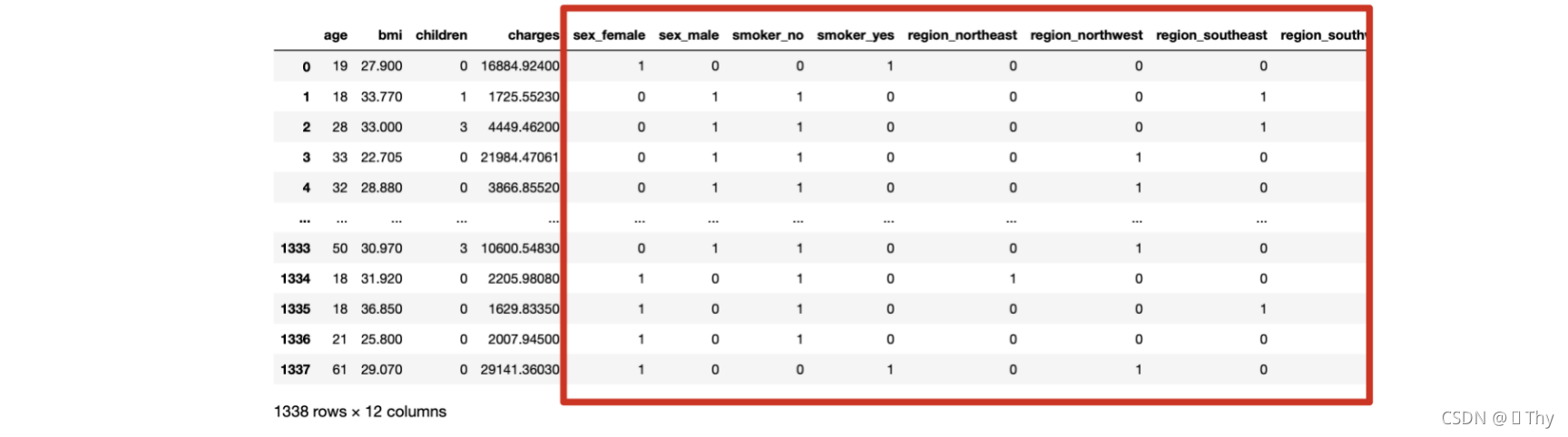
因此需要使用热编码,替换掉源数据这三个变量,得到8个0-1型的新列
yb = pd.read_csv('insurance.csv')
yb =pd.get_dummies(yb, columns=["sex","smoker","region"])
yb
分割
分割训练集、测试集,比例为8:2,种子为202106;其中X包含患者的各类个人信息,Y是医保个人医疗花费。
#分割,比例是8:2,种子为202106
train, test = train_test_split(yb,test_size=0.2, random_state=202106)
X_train, Y_train = train.drop("charges",axis=1),train["charges"]
X_test, Y_test = test.drop("charges",axis=1),test["charges"]
.
Logistic回归
model = LogisticRegression()
start = time.time()
model.fit(X_train, Y_train.astype('int'))
Y_pred = model.predict(X_test)
df =pd.DataFrame({
'实际值': Y_test, '预测值': Y_pred}).head(20)
end = time.time()
t = end - start
print('Logistic回归的MSE为:', metrics.mean_squared_error(Y_test, Y_pred))
print('Logistic回归的RMSE为:', np.sqrt(metrics.mean_squared_error(Y_test, Y_pred)))
print('Logistic回归的耗时为:', t, '秒\n')
df.plot(kind='bar',figsize=(5,5))
plt.rcParams['font.sans-serif'] = ['PingFang HK']
plt.grid(which='major' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









