






 该研究提出了一种结合流形学习和对抗网络的新型中文字体生成技术。首先,利用CNN提取字体特征并构建低维流形,然后在流形上进行插值和外推生成新特征,最后通过对抗性训练的生成网络创建新字体库。实验显示,这种方法能有效生成多样且高质量的新字体。
该研究提出了一种结合流形学习和对抗网络的新型中文字体生成技术。首先,利用CNN提取字体特征并构建低维流形,然后在流形上进行插值和外推生成新特征,最后通过对抗性训练的生成网络创建新字体库。实验显示,这种方法能有效生成多样且高质量的新字体。
本文提出了一种基于流形学习和对抗网络的新样式中文字体库生成方法。从大量覆盖各种风格的现有字体出发,首先利用卷积神经网络获取这些字体的表示特征,然后通过非线性映射构建字体流形。使用字体流形,可以在现有字体之间进行插值和移动,以获得新的字体特征,然后将这些特征输入到通过对抗性训练学习的生成网络中,以生成整个新的字体库。实验结果表明,该方法可以有效地生成各种新样式的高质量中文字体。
具体方法:
给定一组训练字体,对于每种字体样式的每个字符,提取特征向量来分别表示其骨架和轮廓形状。然后,作者使用降维技术将这些向量映射到低维流形中。通过在流形中平滑插值或外推,可以得到一些新的具有合理性质的特征向量。向训练好的深度神经网络中输入一个新的特征向量,就可以得到一个新字体的字符。具体步骤:1、需要提取所有训练数据的字体特征向量 2、使用向量学习字体流形 3、通过对抗性训练训练一个生成网络来合成人物形象
骨架特征提取:
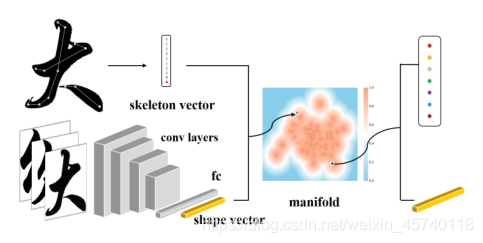
轮廓向量提取:为了构建一个字体流形,必须将字体库中所有字符的样式描述为一个相同的形状向量。因此,利用这些字符的平均形状向量作为它们的形状向量。

高斯过程潜在变量模型(GP-LVM) [Law04]是一种非线性概率降维技术,它将高维数据集Y映射到低维“潜在”数据集x。通过使用GP-LVM,可以为不同字体的每个字符构建一个流形。
网络结构:
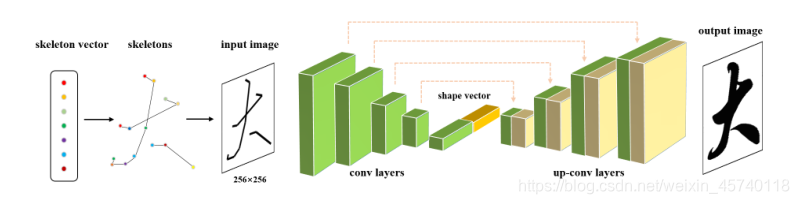
由于网络的输入是图像,需要在骨架向量中绘制点,并在每个笔划中顺序链接点。使用骨架向量提取中保存的额外文件来链接属于同一笔画的点。
网络由两部分组成。第一部分包含几个卷积层,并输出一个编码矢量。将编码向量和形状向量连接起来,作为网络第二部分的输入,第二部分有几个上卷积层,并输出渲染图像。网络将第一部分的层连接到第二部分的相应层。
损失函数:GAN损失函数+像素损失函数
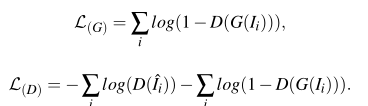
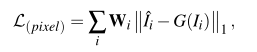
总的损失函数表示: ![]()
实验过程:
训练数据集中,收集了72个字体库用于培训。对于每种字体,作者手动为2000个字符标记骨架。对于字符渲染网络,输入图像的分辨率为256×256,有7个卷积层和7个上卷积层。它们都有256个4×4内核和2×2步长,以ReLU [NH10]为激活函数。作者为40个时期训练网络,批量为32,学习率为0.001。在这里,最多40个时代。在训练过程中,计算每次迭代的平均误差。如果误差在前1k次迭代中没有减少,则认为网络训练良好,停止训练。
流形合成的结果的多样性:

演示汉字“白”的示例字体流形以及从该流形获得的合成结果:
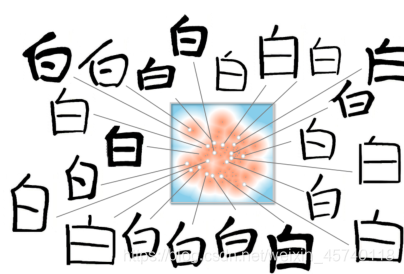
方法优点:该方法不需要用户输入,对字符集大小没有限制。
方法局限性:由于从低维空间到高维空间的不可避免的重建损失,联合改变过程有时会失败。

















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









