







目录
inet_aton, inet_addr 和 inet_ntoa 函数
字节排序函数
内存中存储着两个字节有两种方法:一种将低序字节存储在起始地址,称为小端字节序,另一种方法是将高序字节存储在起始地址,这称为大端字节序。
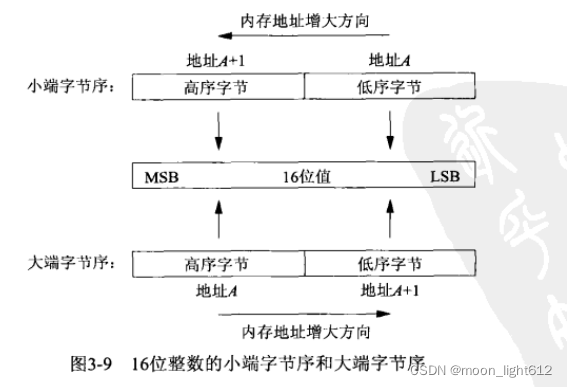
MSB :最高有效位 LSB:最低有效位
我们在一个短整数变量中存放2字节的值0x0102 ,然后查看它的两个连续字节 c[0] 和 c[1] 以此确定字节序。
#include "unp.h"
int main(int argc,char **argv)
{
union {
short s;
char c[sizeof(short)];
} un;
un.s = 0x0102;
printf("%s: ",CPU_VENDOR_OS);
if (sizeof(short)==2){
if(un.c[0] == 1 && un.c[1] == 2)
printf("big-endian\n");
else if(un.c[0] == 2 && un.c[1] == 1)
printf("little-endian\n");
else
printf("unknown\n");
}else{
printf("sizeof(short) = %d\n",sizeof(short));
}
exit(0);
}
//确定主机字节序的程序运行结果:

字节操纵函数
1. 源于4.2BSD以b开头的一组函数
#include <string.h>
void bzero(void *dest,size_t nbytes);
void bcopy(const void *src,void *dest,size_t nbytes);
int bcmp(const void *ptrl,const void *ptr2,size_t nbytes); 返回:若相等则为0,否则为非0bzero: 把目标字符串中指定的数目的字节置为0
bcopy:将指定数目的字节从源字符串移动到目标字符串中
参数:1.源字符串 2.目标字符串 3.移动的字节
bcmp:比较两个字符串的大小,相等返回0。ptr1>ptr2返回大于0。ptr1<ptr2返回小于0
2. 源自ANSI C标准以mem开头的第二组函数
#include <string.h>
void *memset(void *dest,int c,size_t len);
void *memcpy(void *dest,,const void *src,size_t nbytes);
int memcmp(const void *ptrl,const void *ptr2,size_t nbytes);1
memset :把目标字符串指定数目的字节置为值c
memcpy:将指定数目的字节从源字符串移动到目标字符串中
memcmp:比较两个字符串的大小(是在两个不等的字节均为无符号字符的前提下完成的)
memset把目标字符串指定数目的字节置为值c。 memcpy类似bcopy,但是,当源字节串与目标字节串重叠时,bcopy可以正确处理,但是memcpy的操作结果是未知的,需要作failsafe处理。在这种情况下就需要改用成ANSI C的memmove函数。
地址转换函数
inet_aton, inet_addr 和 inet_ntoa 函数
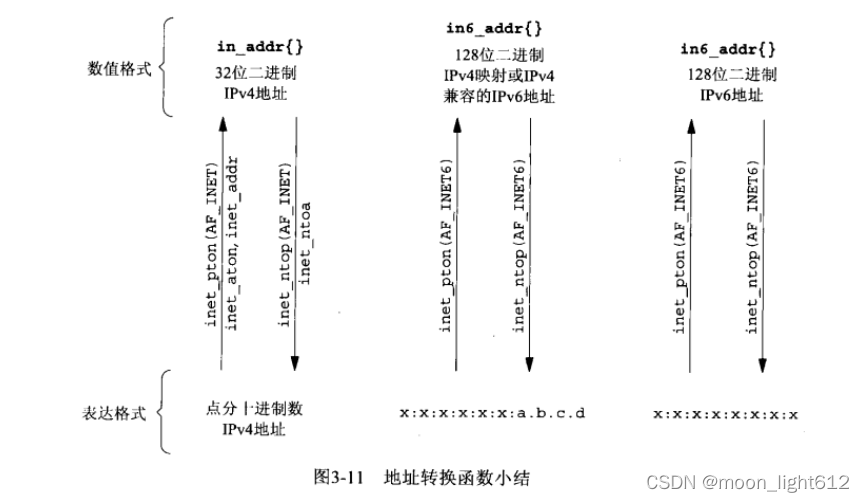
1. inet_aton,inet_addr和inet_ntoa 在点十进制数串与它长度为32为位的网络字节二进制值间转换IPV4地址
2. inet_aton和inet_ntop对于IPV4地址和IPV6地址都适用

inet_aton
原型:int inet_aton(const char *strptr,struct in_addr *addrptr);
功能:将strptr所指的字符串转换成一个32位的网络字节序的二进制值,并通过指针addrptr来存储(该函数对输入的字符串执行有效性检查)
返回值:若字符串有效返回1,否则返回0
inet_addr
原型:in_addr_t inet_addr(const char *strptr);
功能:将strptr所指的字符串转换成一个32位的网络字节序的二进制值(该函数对输入的字符串不进行有效性检查,现已被废弃)
返回值:若字符串有效则为32位二进制网络字节序的IPv4地址,否则为INADDR_NONE
inet_ntoa
原型:char *inet_ntoa(struct in_addr inadrr);
功能:将一个32位的网络字节序的二进制IPv4地址转换成相应的点分十进制数串。由该函数的返回值所指向的字符串驻留在静态内存中(原因参考函数返回局部变量地址的问题),这意味着该函数是不可重入的
返回值:返回指向一个点分十进制数串的指针
inet_pton 和 inet_ntop 函数

inet_pton
原型:int inet_pton(int family, const char *strptr, void *addrptr);
功能:将strptr所指的字符串转换成网络字节序的二进制值,并通过指针addrptr来存储。
返回值:若成功则为1,若输入不是有效的表达格式则为0,若出错则为-1
inet_ntop
原型:const char *inet_ntop(int family, const void *addrptr, char *strptr, size_t len);
功能:将strptr所指的字符串转换成网络字节序的二进制值。(len参数是目标存储单元的大小,以免该函数溢出其调用者的缓冲区)如果len太小,不足以容纳表达格式结果(包含结尾的空字符),那么返回一个空指针,并将errno置为ENOSPC
返回值:若成功则为指向结果的指针,若出错则为NULL
这两个函数的family参数既可以是AF_INET也可以是AF_INET6.如果以不被支持的地址族作为family参数,这两个函数就都返回 一个错误,并将erron置为EAFNOSUPPORT。
程序示例如下:
#include <stdio.h>
#include <arpa/inet.h>
int main ()
{
char IPdotdec[20]; //存放点分十进制IP地址
struct in_addr s; // IP地址结构体
// 输入IP地址
printf("Please input IP address: ");
scanf("%s", IPdotdec);
// 转换
inet_pton(AF_INET, IPdotdec, (void *)&s);
printf("inet_pton: 0x%x\n", s.s_addr);
// 反转换
inet_ntop(AF_INET, (void *)&s, IPdotdec, 16);
printf("inet_ntop: %s\n", IPdotdec);
return 0;
}结果显示:

sock_ntop 和相关函数
inet_ntop存在一个问题:它要求调用者传递一个指向某个二进制地址的指针,而该地址通常包含在一个套接字地址结构中,这就要求调用者必须知道这个结构的格式和地址族。
为了使用这个函数,必须为IPv4编写如下代码:
struct sockaddr_in addr;
inet_ntop(AF_INET, &addr.sin_addr, str, sizeof(str));或为IPv6编写如下代码:
struct sockaddr_in6 addr6;
inet_ntop(AF_INET6, &addr6.sin6_addr, str, sizeof(str)); 这就使得代码与协议相关。为了解决这个问题,我们将自行编写一个名为sock_ntop的函数
它以指向某个套接字地址结构的指针为参数,查看该结构的内部,然后调用适当的函数返回该地址的表达格式。
#include "unp.h"
char *sock_ntop(const struct sockaddr *sockaddr, socklen_t addrlen); 返回:若成功则为非空指针,若出错则为NULL
sockaddr指向一个长度为addrlen的套接字地址结构。本函数用它自己的静态缓冲区来保存结果,指向该缓冲区的一个指针就是它的返回值。
注意:对结果进行静态存储导致该函数不可重入且非线程安全
表达格式就是在一个IPv4地址的点分十进制数串格式之后,或者在一个括以方括号的IPv6地址的十六进制数串格式之后,跟一个终止符(我们使用一个分号,类似于URL语法),再跟一个十进制的端口号,最后跟一个空字符。
缓冲区大小对于IPv4至少为INET_ADDRSTRLEN加上6个字节(16+6=22),对于IPv6至少为INET6_ADDRSTRLEN加上8个字节(46+8=54)。
还为操作套接字地址结构定义了其他几个函数,它们将简化我们的代码在IPv4与IPv6之间的移植
- sock_bind_wild 将通配地址和一个临时端口捆绑到一个套接字
int sock_bind_wild(int sockfd, int family) 返回:若成功则为0,若出错则为-1
- sock_cmp_addr 比较两个套接字地址结构的地址部分
int sock_cmp_addr(const struct sockaddr *sockaddr1,const struct sockaddr *sockaddr2, socklen_t addrlen); 返回:若地址为同一协议族且相同则为0,否则为非0
- sock_cmp_port 比较两个套接字地址结构的端口号部分
int sock_cmp_port(const struct sockaddr *sockaddr1,const struct sockaddr *sockaddr2, socklen_t addrlen); 返回:若地址为同一协议族且端口相同则为0,否则为非0
- sock_get_port 只返回端口号
int sock_get_port(const struct sockaddr *sockaddr, socklen_t addrlen);
返回:若为IPv4或IPv6地址则为非负端口号,否则为-1
- sock_ntop_host 把一个套接字地址结构中的主机部分转换成表达格式(不包括端口号)
char *sock_ntop_host(const struct sockaddr *sockaddr, socklen_t addrlen);
返回:若成功则为非空指针,若出错则为NULL
- sock_set_addr 把一个套接字地址结构中的地址部分置为ptr指针所指的值
void sock_set_addr(const struct sockaddr *sockaddr, socklen_t addrlen, void* ptr);
- sock_set_port 只设置一个套接字地址结构的端口号部分
void sock_set_port(const struct sockaddr *sockaddr, socklen_t addrlen, int port);
- sock_set_wild 把一个套接字地址结构中的地址部分置为通配地址。
void sock_set_wild(struct sockaddr *sockaddr, socklen_t addrlen);
为那些返回值不是void的上述函数提供了包裹函数,它们的名字以S开头,程序通常调用这些包裹函数。
readn , writen , readline 函数
字节流套接字上调用read或write输入或输出的字节数可能比请求少,原因在于内核中用户套接字的缓冲区可能以达到极限。此时所需的是调用者再次调用read函数或write函数,以输入或输出剩余的字节。
因为内核中用于套接字的缓冲区是有限制的,需要调用者多次调用read或write函数。
readn(int fd,void *vptr, size_t n)
从描述符fd中读取n个字节,存入vptr指针的位置。思路如下:
当剩余长度大于0的时候就一直读啊读
当read的返回值小于0的时候,做异常检测
当read的返回值等于0的时候,退出循环
当read的返回值大于0的时候,拿剩余长度减read的返回值,拿到新的剩余长度,读的入口指针加上read的返回值,进入步骤1
返回参数n减去剩余长度,即实际读取的总长度
/* include readn */
#include "unp.h"
ssize_t /* Read "n" bytes from a descriptor. */
readn(int fd, void *vptr, size_t n)
{
size_t nleft;
ssize_t nread;
char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nread = read(fd, ptr, nleft)) < 0) {
if (errno == EINTR)
nread = 0; /* and call read() again */
else
return(-1);
} else if (nread == 0)
break; /* EOF */
nleft -= nread;
ptr += nread;
}
return(n - nleft); /* return >= 0 */
}
/* end readn */
ssize_t
Readn(int fd, void *ptr, size_t nbytes)
{
ssize_t n;
if ( (n = readn(fd, ptr, nbytes)) < 0)
err_sys("readn error");
return(n);
}writen(int fd,const void* vptr, size_t n)
像描述符fd中写入n个字节,从vptr位置开始写。思路如下:
当要写入的剩余长度大于0的时候就一直写啊写
当write的返回值小于0的时候,做异常检测
当write的返回值等于0的时候,出错退出程序
当write的返回值大于0的时候,拿剩余长度减去write的返回值,拿到新的剩余长度,写的入口指针加上write的返回值,进入步骤1
返回参数n的值,即期望写入的总长度
/* include writen */
#include "unp.h"
ssize_t /* Write "n" bytes to a descriptor. */
writen(int fd, const void *vptr, size_t n)
{
size_t nleft;
ssize_t nwritten;
const char *ptr;
ptr = vptr;
nleft = n;
while (nleft > 0) {
if ( (nwritten = write(fd, ptr, nleft)) <= 0) {
if (nwritten < 0 && errno == EINTR)
nwritten = 0; /* and call write() again */
else
return(-1); /* error */
}
nleft -= nwritten;
ptr += nwritten;
}
return(n);
}
/* end writen */
void
Writen(int fd, void *ptr, size_t nbytes)
{
if (writen(fd, ptr, nbytes) != nbytes)
err_sys("writen error");
}readline(int fd,void *vptr, size_t maxlen)
my_read(int fd,char *ptr) 替换 read(fd,&c,1),实现一个较快速版本。思路如下:
当读取的次数小于maxlen的时候就一直读啊读
进入my_read函数,这个函数每次最多读MAXLINE个字符,然后每次返回一个字符
将读到的值赋值给ptr++,判断是不是\n
当read的返回值等于0的时候,读完了
当read的返回值小于0的时候,做异常检测
进入步骤1
返回实际读取的长度
/* include readline */
#include "unp.h"
static int read_cnt;
static char *read_ptr;
static char read_buf[MAXLINE];
static ssize_t
my_read(int fd, char *ptr)
{
if (read_cnt <= 0) {
again:
if ( (read_cnt = read(fd, read_buf, sizeof(read_buf))) < 0) {
if (errno == EINTR)
goto again;
return(-1);
} else if (read_cnt == 0)
return(0);
read_ptr = read_buf;
}
read_cnt--;
*ptr = *read_ptr++;
return(1);
}
ssize_t
readline(int fd, void *vptr, size_t maxlen)
{
ssize_t n, rc;
char c, *ptr;
ptr = vptr;
for (n = 1; n < maxlen; n++) {
if ( (rc = my_read(fd, &c)) == 1) {
*ptr++ = c;
if (c == '\n')
break; /* newline is stored, like fgets() */
} else if (rc == 0) {
*ptr = 0;
return(n - 1); /* EOF, n - 1 bytes were read */
} else
return(-1); /* error, errno set by read() */
}
*ptr = 0; /* null terminate like fgets() */
return(n);
}
ssize_t
readlinebuf(void **vptrptr)
{
if (read_cnt)
*vptrptr = read_ptr;
return(read_cnt);
}
/* end readline */
ssize_t
Readline(int fd, void *ptr, size_t maxlen)
{
ssize_t n;
if ( (n = readline(fd, ptr, maxlen)) < 0)
err_sys("readline error");
return(n);
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









