






摘要:
尽管许多研究都表明了保护隐私、提高训练成绩或引入拜占庭式复原力的可行性,但没有一项研究同时考虑所有这些因素。
面临问题:如何在保证整个系统的学习安全性和数据隐私性的同时,有效地协调分散式学习过程
方法:提出了一种基于区块链安全和隐私保护的去中心化学习系统--SPDL。SPDL将区块链、拜占庭容错(BFT)共识、BFT梯度聚合规则(GAR)和差分隐私(DP)无缝集成到一个系统中,确保了高效的机器学习,同时维护了数据隐私、拜占庭容错、透明性和可追溯性。
1.引言:
本文贡献:
1)据我们所知,这是第一个安全和隐私保护的机器学习系统,用于分散式网络,其中学习过程不受可信参数服务器的影响。
2)SPDL利用DP进行数据隐私保护,并将BFT共识和BFT GAR无缝嵌入到区块链系统中,以利于模型训练,具有拜占庭容错性,透明度和可追溯性,同时保持高效率。
3)我们进行严格的收敛性和遗憾性分析SPDL在拜占庭节点的存在下,建立了一个原型,并进行了广泛的实验,以证明SPDL的可行性和有效性。
4.System design
4.3 SPDL Workflow
4.3.1 初始化
每个节点创建一对私钥sk和公钥pk,并根据pk生成其唯一的256位身份id
创建一个创世块B0
所有节点都具有相同的信誉值
我们假设所有节点都以相同的初始参数值 开始学习过程
4.3.2 领导者选举
基于VRF算法进行选举(追求的就是随机性)
其中每个客户端还有一个信誉值r 如果r=0那么该节点无法被选为领导者
拜占庭节点无法冒充为伪装者 因为VRF 确保证明 h 不可伪造 在验证时使用拜占庭节点的公钥和领导者节点的h和pai无法成功验证

4.3.3 梯度计算
很简单的三步骤:
生成本地梯度--》给梯度添加噪声--》广播自己的梯度,接受其他节点的梯度

4.4.4区块链共识
采用的聚合算法 准确的说Krum 的输出是其输入梯度之一(选择一个最恰当的梯度进行模型参数更新)


6.实验
五组实验 其余两种对比方法 PURE(去中心化学习)DP(在PURE的基础上增加差分隐私)
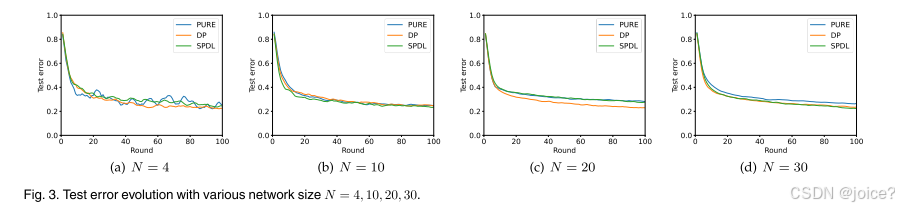
第一组实验关于网络大小对收敛性的影响 (我认为是客户端数量对收敛性的影响)
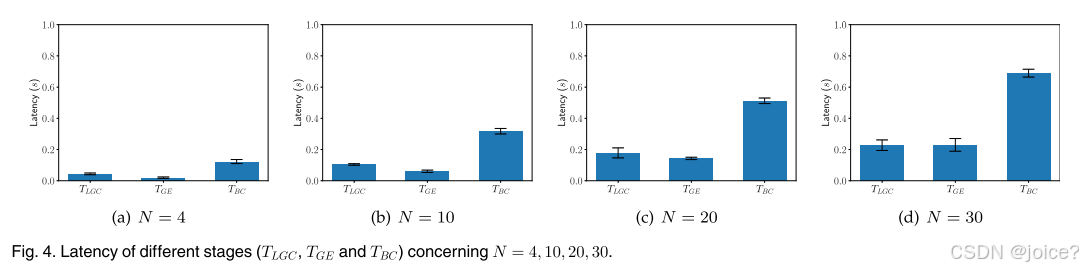
第二组 每个阶段的时间消耗
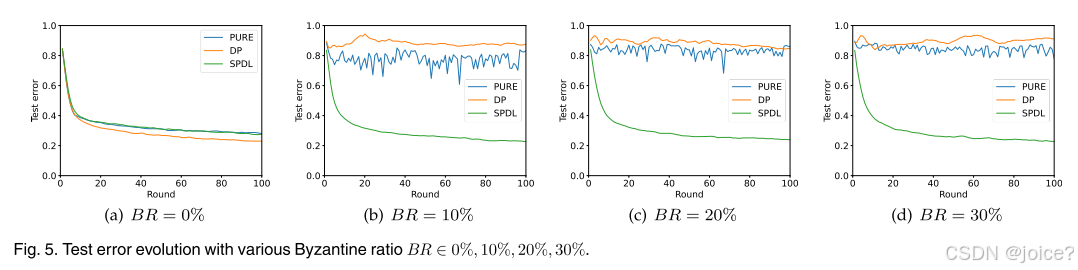
第三组 拜占庭节点数量对收敛性的影响
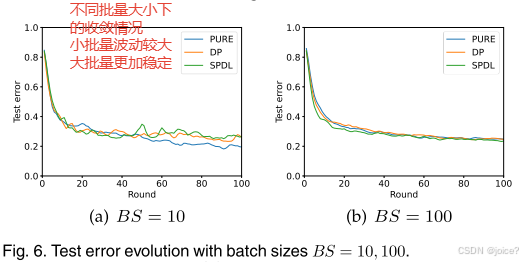
第四组 不同批量大小下收敛情况
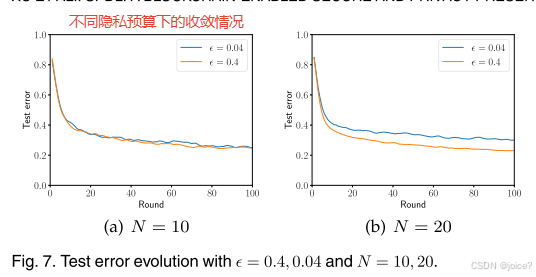
第五组 不同隐私计算下的收敛情况


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









