







 本文是Python爬虫入门系列,讲解如何使用BeautifulSoup库从HTML中提取数据。介绍了BeautifulSoup对象的类型,包括Tag, NavigableString, BeautifulSoup, Comment,以及遍历和搜索文档树的方法。通过实例演示了从Unsplash网站抓取图片URL,并讨论了动态加载内容的处理策略。"
84395819,1345727,IDEA快速入门:创建第一个Maven工程,"['java', '工具', 'IDEA', 'Maven']
本文是Python爬虫入门系列,讲解如何使用BeautifulSoup库从HTML中提取数据。介绍了BeautifulSoup对象的类型,包括Tag, NavigableString, BeautifulSoup, Comment,以及遍历和搜索文档树的方法。通过实例演示了从Unsplash网站抓取图片URL,并讨论了动态加载内容的处理策略。"
84395819,1345727,IDEA快速入门:创建第一个Maven工程,"['java', '工具', 'IDEA', 'Maven']
一、前言
上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据。这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据。
update on 2016-12-28:之前忘记给BeautifulSoup的官网了,今天补上,顺便再补点BeautifulSoup的用法。
update on 2017-08-16:很多网友留言说Unsplash网站改版了,很多内容是动态加载的。所以建议动态加载的内容使用PhantomJS而不是Request库进行请求,如果使用PhantomJS请看我的下一篇博客,如果是定位html文档使用的class等名字更改的话,建议大家根据更改后的内容进行定位,学爬虫重要的是爬取数据的逻辑,逻辑掌握了网站怎么变都不重要啦。
二、运行环境
我的运行环境如下:
-
系统版本
Windows10。 -
Python版本
Python3.5,推荐使用Anaconda 这个科学计算版本,主要是因为它自带一个包管理工具,可以解决有些包安装错误的问题。去官网,选择Python3.5版本,然后下载安装。 -
IDE
我使用的是PyCharm,是专门为Python开发的IDE。这是JetBrians的产品。
三、模块安装
BeautifulSoup 有多个版本,我们使用BeautifulSoup4。详细使用看官方文档。
使用管理员权限打开cmd命令窗口,在窗口中输入下面的命令即可安装:conda install beautifulsoup4Python入门到精通学习教程请加219再加上539然后519内有大量学习教程,欢迎大家加入
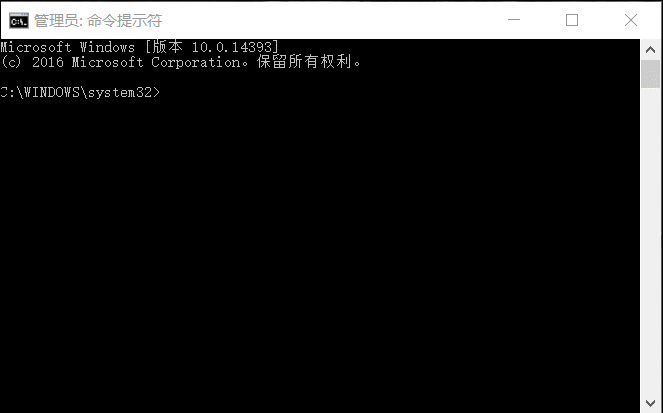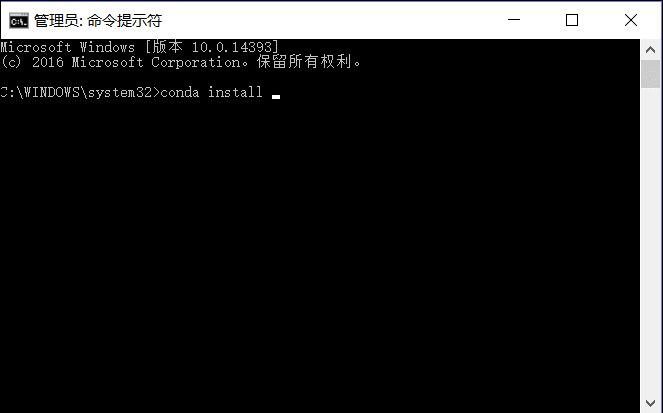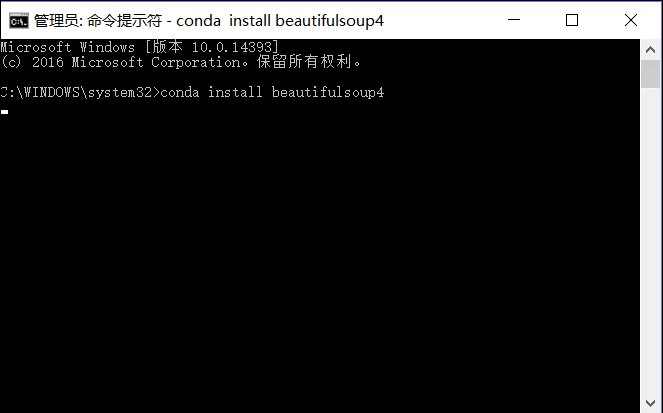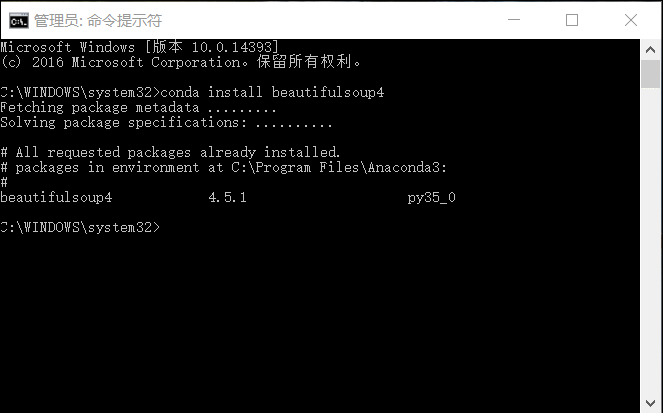
直接使用Python3.5 没有使用Anaconda版本的童鞋使用下面命令安装:pip install beautifulsoup4
然后我们安装lxml,这是一个解析器,BeautifulSoup可以使用它来解析HTML,然后提取内容。
Anaconda 使用下面命令安装lxml:conda install lxml
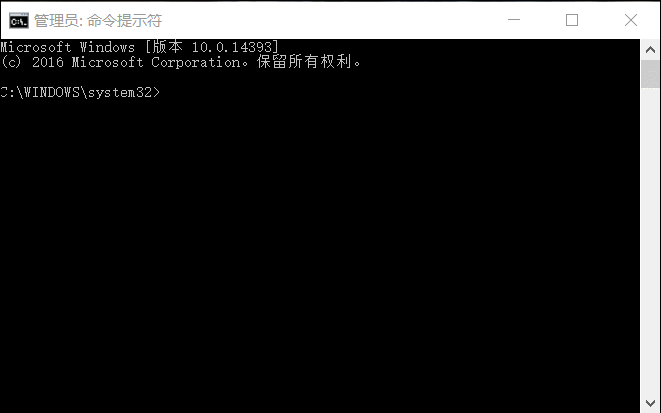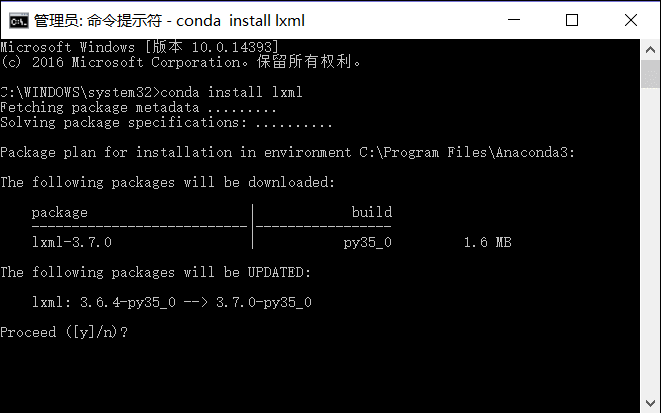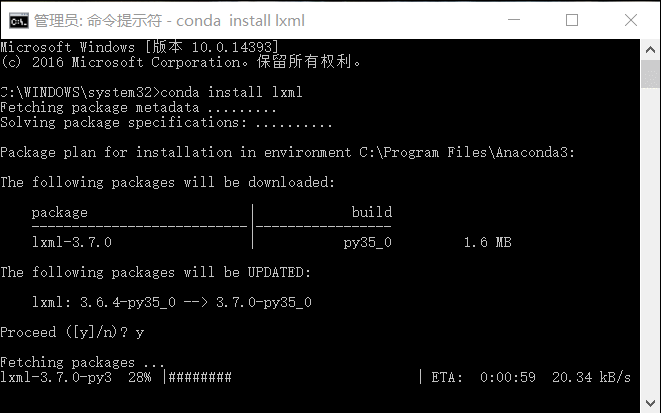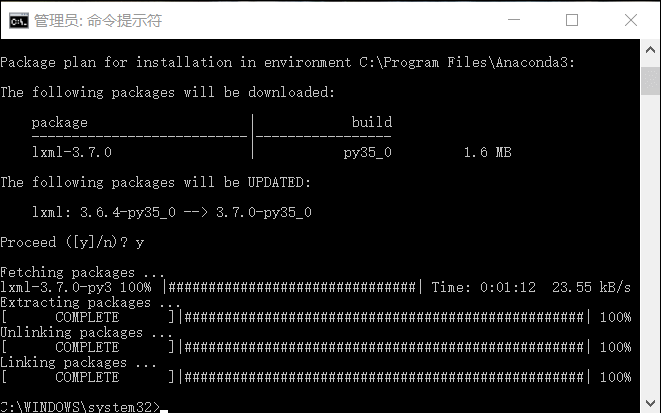
使用Python3.5 的童鞋们直接使用pip安装会报错(所以才推荐使用Anaconda版本),安装教程看这里。
如果不安装lxml,则BeautifulSoup会使用Python内置的解析器对文档进行解析。之所以使用lxml,是因为它速度快。
文档解析器对照表如下:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,"html.parser") | 1. Python的内置标准库 2. 执行速度适 3. 中文档容错能力强 |
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup,"lxml") | 1. 速度快 2. 文档容错能力强 |
需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup,["lxml-xml"]) BeautifulSoup(markup,"xml") |
1. 速度快 2. 唯一支持XML的解析器 |
需要安装C语言库 |
| html5lib | BeautifulSoup(markup,"html5lib") | 1. 最好的容错性 2. 以浏览器的方式解析文档 3. 生成HTML5格式的文档 |
速度慢,不依赖外部扩展 |
四、BeautifulSoup 库的使用
网上找到的几个官方文档,不同版本的用法差不多,几个常用的语法都一样。
首先来看BeautifulSoup的对象种类,在使用的过程中就会了解你获取到的东西接下来应该如何操作。
4.1 BeautifulSoup对象的类型
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象。所有对象可以归纳为4种类型: Tag , NavigableString , BeautifulSoup , Comment 。下面我们分别看看这四种类型都是什么东西。
4.1.1 Tag
这个就跟HTML或者XML(还能解析XML?是的,能!)中的标签是一样一样的。我们使用find()方法返回的类型就是这个(插一句:使用find-all()返回的是多个该对象的集合,是可以用for循环遍历的。)。返回标签之后,还可以对提取标签中的信息。
提取标签的名字:
tag.name
提取标签的属性:
tag['attribute']
我们用一个例子来了解这个类型:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="ht 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









