






向量运算
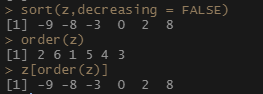
order函数取向量从小到大排序的索引值 z[order(z)]~sort(z)
z <- c(-3,-9,8,2,0,-8)
#decreasing默认为Flase 升序
sort(z,decreasing = FALSE)
order(z)
z[order(z)]
产生有规律的向量
seq(from,by,to,along)
''
#seq函数
seq(-2,3)#默认步长为1
seq(from = 0 ,by = 0.2 ,to = 1)
#length参数 得到序列的长度
seq(from = 1,to = 10,length = 10)
''

rep(w,n) 指重复w n次
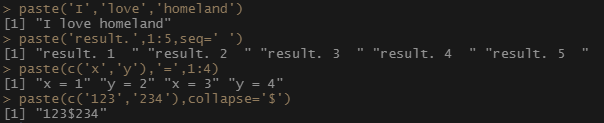
paste函数把自变量连成字符串,默认用空格隔开
rep(z,2)
paste('I','love','homeland')
paste('result.',1:5,seq=' ')
paste(c('x','y'),'=',1:4)
paste(c('123','234'),collapse='$')
逻辑向量
逻辑向量的简单实用,不仅在R语言中很重要。在pandas对于数据操作中也显得非常重要。
首先看这样一个例子
x <- c(TRUE,TRUE,FALSE,FALSE,TRUE)
y <- c(1,2,3,4,5)
x是一个True or False的向量。y是一个数值向量

可以看出通过x的向量,挑选出了y对应位置是True的向量

那么我通过y>3产生的True or Flase向量就可以轻易地筛选出y中大于三的数值。
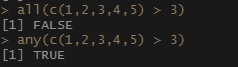
函数all(),any()的介绍
首先all和any分别判断是否都为真或者是否含有真,所以返回的只会是True or Flase
缺失数据
一般数据中含有不确定的数据项,可以通过**is.nan()**函数检查数据是否缺失

类似的函数比如 is.na() 检验数据是否缺失:

数据结构-列表
R语言中的列表大致指的是一个集合,集合中可以囊括不同的小集合,并且小集合的数据类型可以不同。比如说列表A囊括b,c,d那么A看作是一个容器,b可以是字符类型’This is a list’,c可以是向量c(1,2,3),d还可以是列表,也就是列表里还可以是列表。
然后把向量和矩阵和列表都装进一个列表再输出:
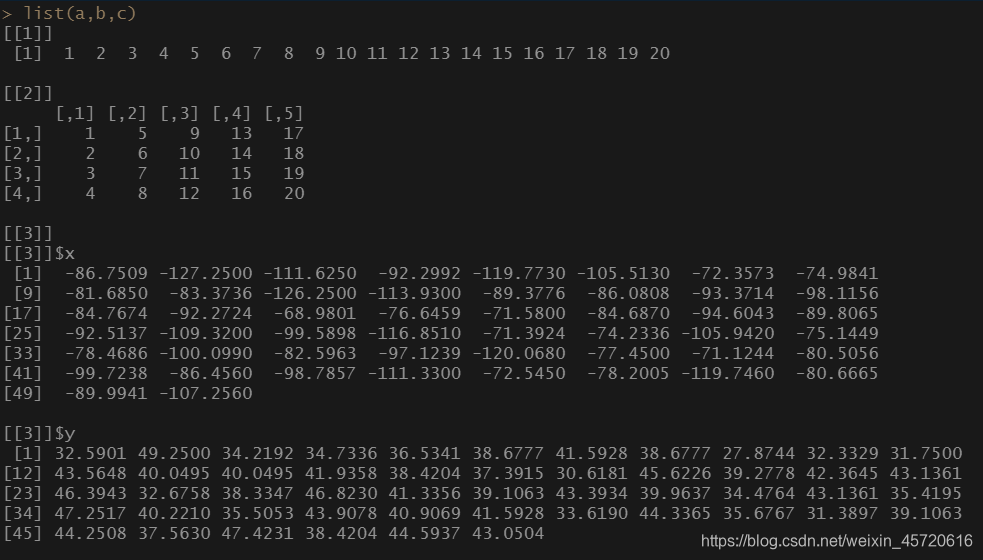
创建列表时还可以赋予每个小集合名称:
list(First = a,Second = b , Third = c)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









