






正则表达式
基本定义
在代码中常简写为 regex、regexp 或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。正则表达式一般用于脚本编程与文本编辑器中。
根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用的正则表达式的最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式 。
基础示例
元字符
能够匹配一个位置或者字符集合中的一个字符。
匹配位置的元字符 ^| $| \b
总共有^ $ \b三个
- ^匹配行开始的位置
"^z"匹配的是以z作为行开头的字符串
对于zzwhct,hdzzwf,dfjzzw进行匹配
zzw #匹配zzwhct,hdzzwf,dfjzzw
^zzw #匹配zzwhct
-
$匹配行的结尾位置
"z$"匹配的是以z作为行结尾的字符串
对于zzwhct,hdzzwf,dfjzzw进行匹配
zzw #匹配zzwhct,hdzzwf,dfjzzw
zzw$ #匹配dfjzzw
结合一起就可以知道:"^zKaTeX parse error: Expected group after '^' at position 16: "匹配的是只有z这个字符串;"^̲"匹配的就是一个空行,其中不包含任何字符串
-
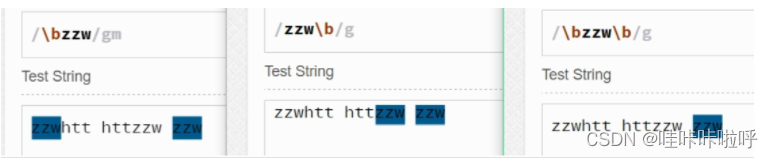
\b匹配单词的开始或者结束
"\bz"匹配的是z之前是空格符号、标点符号或者换行符号的z;
"z\b"匹配的是z之后是空格符号、标点符号或者换行符号的z;
"\bz\b"匹配的是z前后必须是空格符号、标点符号或换行符号的z
(\b匹配的仅是一个零宽度的位置)
匹配字符的元字符 \w \s \d \W \S \D .
\w \s \d \W \S \D .一共有7个
\w :匹配单词字符(字母、下划线、数字和汉字),等价于[a-zA-Z0-9_]
\s:匹配的是任意空白字符(空格、制表符、换行符、中文全角空格等)
\d:匹配任意数字
点号. :匹配除换行符之外的任意字符
大写则表示相反意义:
\W:匹配任意非单词的字符
\S:匹配任意非空白字符
\D:匹配任意非数字字符
^.$匹配任意一个非换行符的字符\ba\w\w\b匹配以a开头的后面有2个单词的字符^\w$匹配一个任意单词字符
文字匹配
字符类
[]取其中之一,^取反,-表示至区间
-
[]表示其中一个单词
[aie]表示这三个字母其中的任意一个、<H[123]>表示匹配其中的任意一个
-
-在字符中间表示“到”的意思,单独使用时可表示负号
<H[1-3]>是以上正则表达式的简写[0-9] 与\d表示意义一致,[a-z]表示所有小写字
[A-Z]表示所有大写字母,
[a-zA-Z]表示所有大小写字母[-b]5 匹配的是-5或者b5
-
^表示否定该字符
[^123]表示不是1,2,3的其他任意字符
[^-] 表示匹配不是-的任意字符
[0-9a-zA-Z]匹配任意数字、字母、下划线,等价于\w[^0-9a-zA-Z]等价于\W
字符转义
使的有特殊含义的字符能够看作一般字符进行匹配,采用\进行转义
\.表示匹配.这个符号,\\可以用来匹配\这个符号
反义
^表示取反
[^>]表示后面不是>的其他任意字符
限定符
{n} 表示重复n次,如\w{5}表示匹配5个单词字符
{n,} 表示至少重复n次,\w{5,}表示至少5个,可以有6个、7个……
{n,m}表示重复至少n次,至多m次,\w{5,7}表示匹配至少5个,至多7个单词字符
*表示重复至少0次,等价于{0,},hu*t匹配ht、hut、huut……
+表示重复至少1次,等价于{1,}
?表示重复0次或1次,等价于{0,1}
懒惰限定符
在以上限定符后面加上?符号,表示尽可能少的使用重复
对于aabab这个字符串,使用a.*b会匹配aabab,使用a.*?b会匹配aab和ab,而不是匹配所有
字符运算
替换、分组、反向引用
替换(或运算符|)
[Jj]ack匹配的就是Jack或者jack,此时可以用jack|Jack匹配效果一致
匹配001a,零零壹a时可以输入(001|零零壹)a
分组
使用"(“和”)",即左圆括号和右圆括号将某些字符括起来看成一个整体来处理。
abc{3}此时匹配的是abccc
(abc){3} 此时就可以匹配abcabcabc
(\d{1,3}\.){3}\d{1,3}就可以匹配到192.168.35.239
通过()可以进行分组,而分组的同时,每一个组被自动赋予了一个组号,该组号可以代表该组的表达式。
编组的规则是:从左到右、以分组的左括号"("为标志,第一个分组的组号为1,第二个分组的组号为2,以此类推。
常用分组:
-
正向先行断言:(?=expression)匹配字符串expression前面的位置,指再某个位置向右看,所在位置右侧必须能匹配表达式
匹配:至少一个大写字母,一个小写字母,一个数字,8个字符 输入:(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9]).{8,} -
反向先行断言:(?!expression),匹配后面不是字符串expression的位置,保证右边不能出现某字符
匹配:不是qq邮箱的数据 输入:@(?!qq.com) -
正向后行断言:(?<=expression)匹配字符串expression后面的位置,某个位置向左看,表示所在位置左侧必须能匹配表达式
匹配:王姓同学的名字 输入:(?<=王).+ -
反向后行断言:`(?<!expression)匹配前面不是字符串expression的位置
-
(?>expression)只匹配字符串expression一次
反向引用
可以用来反向引用使用()括起来的字符组了。
- \数字,使用数字命名的反向引用。
- \k,使用指定命名的反向引用。注:这个是
.NET Frameword支持的一种方式。
\b\w\w\b #匹配aa、ab、ac、bb
\b(\w)\1\b #匹配aa、bb
(\w{3}(\d{2}))) #匹配 www55www5555
\w\w 可以匹配aa、ab、ac等,但是(\w)\1则匹配两个重复的单词字符
对于(\w{3}(\d{2}))字符串,其中\w{3}\d{2}是第一个分组,\d{2}是第二个分组因此此时匹配的就是该字符串后面跟第一个分组字符串再接第二个分组内字符串
零宽度断言
把满足的一个条件成为断言或零宽度断言
常用的有:
- ^ 匹配行的开始位置
- $ 匹配行的结束位置
- \A 匹配必须出现在字符串的开头
- \Z 匹配必须出现在字符串的结尾或字符串结尾处的\换行符\n之前
- \z 匹配必须出现在字符串的结尾
- \G 匹配必须出现在上一个匹配结束的地方
- \b 匹配字符的开始或结束位置
- \B 匹配不是在字符的开始或结束位置
优先级顺序
优先级顺序表(优先级由高到低)如下:
- 转义符:\
- 圆括号和方括号:()、(?😃、(?=)、[]
- 限定符: *、+、?、{n}、{n,}、{n,m}
- 位置和顺序:^、$、(元字符)
- 或运算:|
正则表达式常用函数
使用正则表达式需要导入re库
re.match函数
re.match(pattern,string,flags=0)
从字符串string的起始位置开始匹配
pattern:代表对应的正确表达式,string:代表对应的源字符,flag:改参数是可选参数,代表对应的标志位置,可以放模式修正符等信息。
re.match(pattern,string,flags=0).span()
返回字符串匹配的所在序号范围
re.match(pattern,string,flags=0).group()
返回匹配正则表达式的字符串
re.search函数
re.match(pattern,string,flags=0)
扫描整个字符串string进行对应的匹配
re.match()函数从源字符串的开头进行匹配,如果源字符起始位置的不符合正则表达式,则匹配失败,而re.search()函数会在全文中进行检索并匹配,只要全文中有符合正则表达式的,就可以匹配成功,这就是这两个函数的最大区别。
在这两个匹配函数中,即使源字符串中有多个结果符合正则表达式,也只会匹配一个结果
全局匹配函数 re.compile函数
re.compile(pattern)
根据正则表达式编译出所有的匹配结果
re.compile(pattern).findall(string)
对所有结果进行匹配输出
import re
string = "hellomypythonispythonourpythonend"
pattern = re.compile(".python.") #预编译
result = pattern.findall(string)#找出符合的所有结果
print(result)
#["ypythoni","spythono","rpythone"]
re.sub函数
re.sub(pattern,rep,string,max)
根据正则表达式来实现替换某些字符串的功能
pattern:代表对应的正则表达式;rep:替换成的字符串;string:为源字符串;max:为可选项,表示最多替换次数。

















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









