






目录
创建索引及添加文档,不指定索引类型 默认用_doc类型,不建议自己设置类型
一:介绍
ElasticSearch实时分布式全文检索和分析引擎,他让你以前所未有的速度处理大数据成为可能
全文搜索、结构化搜、分析
通过简单的ResultFul API来隐藏Lucene的复杂性,从而让全文搜索变得简单
二:安装及配置
ElasticSearch7.6.1
ELK三剑客,解压即用
解压到E:\Enviroment\ElasticSearch下即可
启动es服务
点击elasticsearch.bat
浏览器上输入http://localhost:9200/ 显示"You Know, for Search"就表示启动成功,其实这步不用做也行只是知道启没启动成功
es目录介绍
bin:启动文件
config:配置文件
log4j2.properties:日志配置文件
jvm.options:java虚拟机的配置
elasticsearch.yml:es的配置文件 ---默认端口9200
data:索引数据目录
lib:相关类库Jar包
logs:日志目录
modules:功能模块
plugins:插件
可视化界面es head插件
安装head
Head是elasticsearch的集群管理工具,可以用于数据的浏览查询--默认端口号9100
注意:安装前需要Node JS的环境
1:先解压:E:\Enviroment\ElasticSearch\elasticsearch-head-master
2:然后在这个目录cmd 输入cnpm install(别用npm容易安装失败),安装成功就会多一个文件夹node_modules
解决跨域问题
head插件端口号是9100,es是9200,这样就出现了跨域问题,使用不了head
ES的配置文件中配置下跨域问题:"E:\Enviroment\ElasticSearch\elasticsearch-7.6.1\config\elasticsearch.yml"文件下配置
最后边加上: # 跨域配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
使用head可视化插件
在E:\Enviroment\ElasticSearch\elasticsearch-head-master进行cmd,输入npm run start
然后浏览器输入http://localhost:9100/
就能进入可视化界面
Kibana
解压即可,Kibana版本要和es版本一致7.6.1---默认端口5601
Kibana汉化
在"E:\Enviroment\ElasticSearch\kibana-7.6.1-windows-x86_64\config\kibana.yml"里最后一行加入
i18n.locale: "zh-CN"
改完重启
启动Kibana服务
点击kibana.bat---先启动es才能启动
浏览器访问5601
开发工具(Post、curl、head、谷歌浏览器)
这里用Kibana里的Dev Tools
head插件建议我们只把他当做数据展示工具,后面的查询用Kibana
IK提词器插件
安装IK提词器插件
下载压缩包,并解压到E:\Enviroment\ElasticSearch\elasticsearch-7.6.1\plugins\ik下即可
为什么使用IK?
分词:即把一段中文或者英文划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把
数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个
词,比如 “我爱狂神” 会被分为"我","爱","狂","神",这显然是不符合要求的,所以我们需要安装中文分词
器ik来解决这个问题。
如果要使用中文,建议使用ik分词器
分词算法
IK提供了两个分词算法:ik_smart 和 ik_max_word,
ik_smart 为最少切分,
ik_max_word为最细粒度划分:穷尽词库,比如中国共产党 会被分成中国、共产、国共等等
先启动es,然后启动ik,分别使用两种算法
使用ik_smart 最少切分

使用 ik_max_word为最细粒度划分
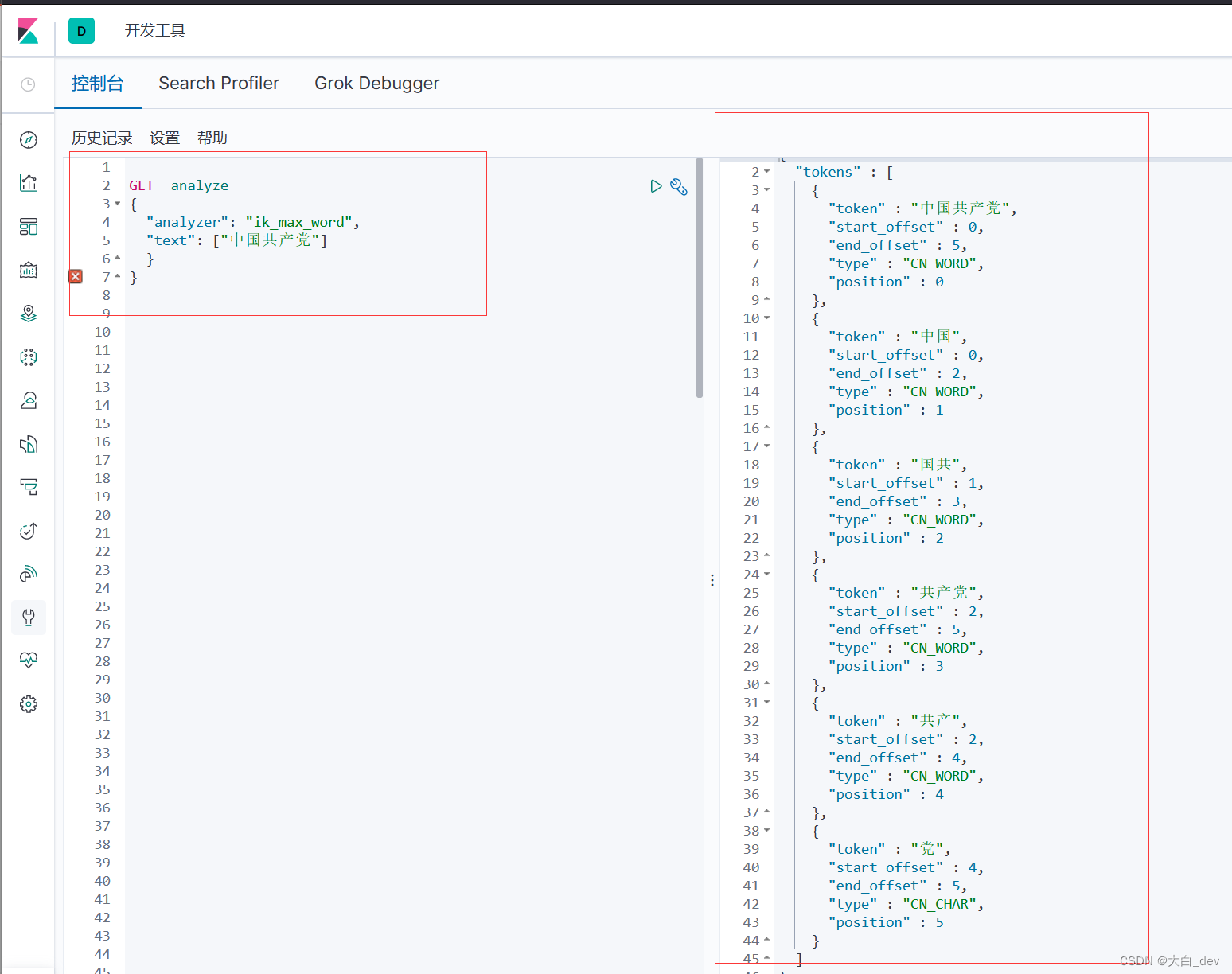
添加分词器字典
如果用最细粒度划分,发现“狂神说”被拆开了,被拆成一个一个单独的字 这种情况,就需要自己把“狂神说”加到分词器字典中 1:在E:\Enviroment\ElasticSearch\elasticsearch-7.6.1\plugins\ik\config下创建文件kuang.dic文件,文件里添加“狂神说”
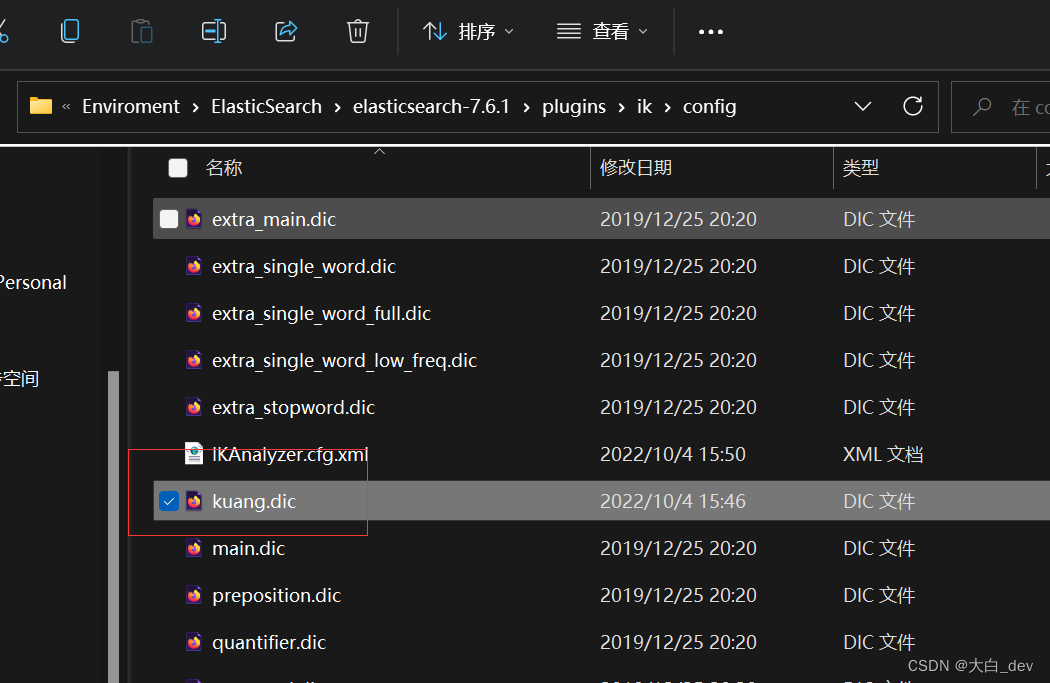
2:然后把该文件,注入到配置文件IKAnalyzer.cfg.xml中
添加<entry key="ext_dict">kuang.dic</entry>
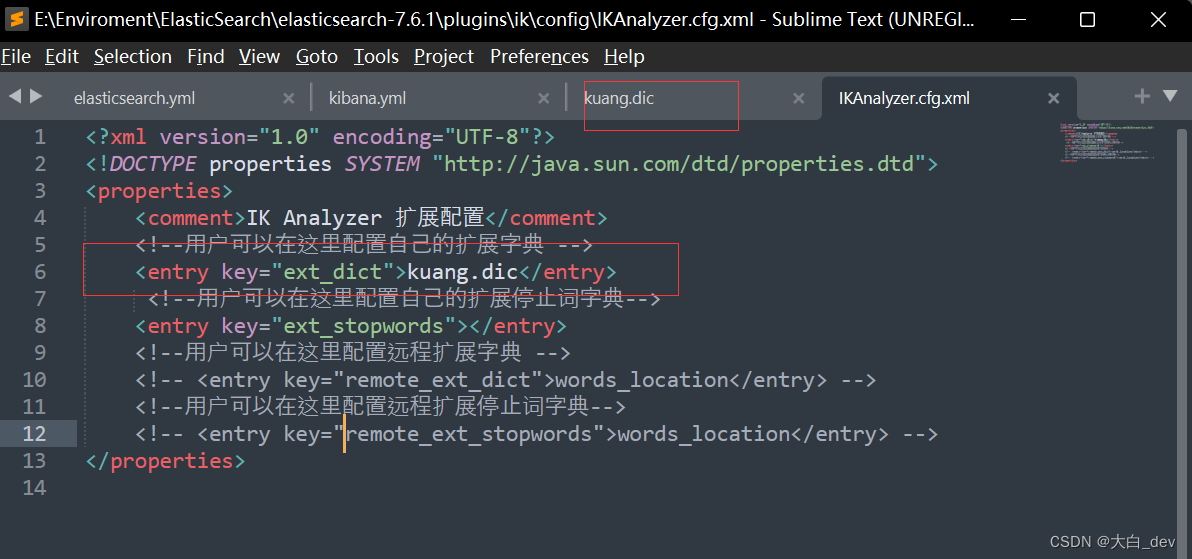
3:重启即生效(重启es时发现加载了kuang.dic字样),发现经过最细粒度算法,狂神说没有被拆分
三:ES核心概念
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
索引
当做库
类型
当做一张张表,比如user表,自己定义的,不过默认都是_doc(推荐默认,不要自己定义)
文档
当做一条条数据
字段类型
字符串类型 text 、 keyword 数值类型 long, integer, short, byte, double, float, half_float, scaled_float 日期类型 date te布尔值类型 boolean 二进制类型 binary 等等......
物理设计
elasticsearch 在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
一个人就是一个集群,默认的集群名称就是elasticsearch
es是面向文档的,文档就是一条条数据
user
zhangsan 18
lisi 20
四:索引及文档的增删改查
Rest风格
method url地址 描述
PUT localhost:9200/索引名称/类型名称/文档id 创建文档(指定文档id)
POST localhost:9200/索引名称/类型名称 创建文档(随机文档id)
POST localhost:9200/索引名称/类型名称/文档id/_update 修改文档
DELETE localhost:9200/索引名称/类型名称/文档id 删除文档
GET localhost:9200/索引名称/类型名称/文档id 查询文档通过文档id
POST localhost:9200/索引名称/类型名称/_search 查询所有数据
文档类型
字符串类型
text 、 keyword
数值类型
long, integer, short, byte, double, float, half_float, scaled_float
日期类型
date
te布尔值类型
boolean
二进制类型
binary
等等.....
增
(不仅可以用kibana创建,其他创建也可以)
在kibana控制台中输入
// PUT /索引/类型/文档id {请求体}(类型是自己设置,比如user、home、aaa自己设置就行,不过建议不设置而用默认的_doc,请求体就是一条条文档)
创建索引及添加文档(这里类型用自己创建的user)

只创建索引,不加文档

创建索引及添加文档,不指定索引类型 默认用_doc类型,不建议自己设置类型
GET test3----发现获取索引信息后,其中的文档name age birth都被指定类型啦,分别为long、date、text
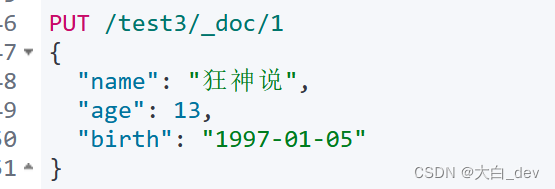
创建索引及添加多条文档

改
第一种方法,再次添加文档就会覆盖之前的
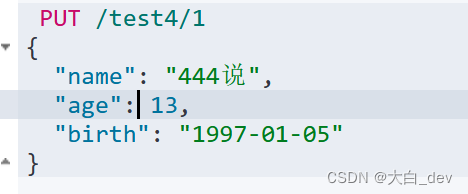
第二种方法(推荐推荐)Post _update

删
删除索引
Delete test1
删除文档
Delete test1/_doc/1
查
查看索引,及其所有数据

结果

简单条件查询
GET kuangshen/user/_search?q=name:张三
(旧版不需要带索引类型user,老版需要带user)

复杂条件查询
---使用参数体,match表示先被分词然后再匹配值 相当于一个模糊查询,_source表示需要输出的文档相当于select name,sout表示排序,分页查询from-size,

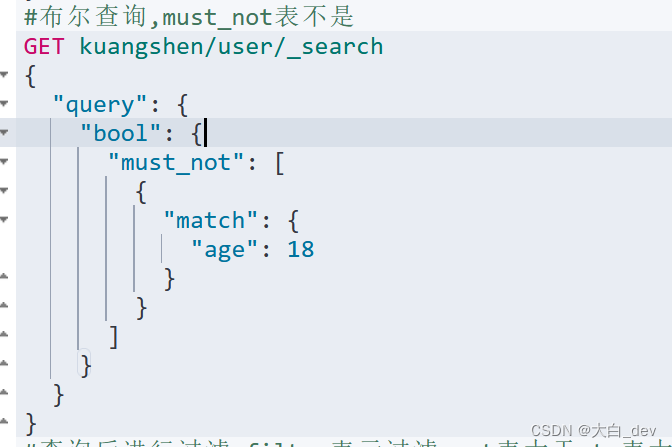
布尔查询
must相当于sql中的and 所有的条件都要符合,
should相当于sql中的or满足其一即可
must_not表不是


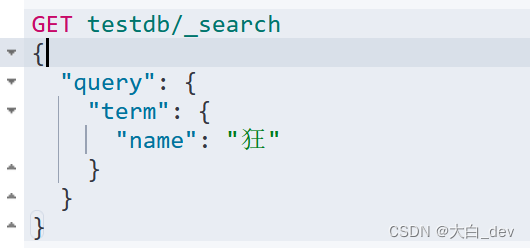
精确查询
--term。term查询精确的 直接去倒排索引查找精确的值
高亮查询
---比如百度搜索,搜索结果关键词都有高亮显示。field设置高亮的字段

五:springboot集成es
导入依赖
<properties>
<java.version>1.8</java.version>
<!-- 这里SpringBoot默认配置的版本不匹配,我们需要自己配置版本! -->
<elasticsearch.version>7.6.1</elasticsearch.version>
<!-- 跳过测试 -->
<skipTests>true</skipTests>
</properties>
<dependencies>
<!--es依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--需要json格式-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>es配置
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
)
);
return client;
}
}
建一个user表
,做中间媒介,不用建数据库
@Component
public class User {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}用代码来对es进行索引和文档的操作
(前提要开启es服务,然后用head查看是否修改成功)
@SpringBootTest
class Springboot20esApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//创建索引
@Test
void createIndex() throws IOException {
//创建索引请求
CreateIndexRequest request = new CreateIndexRequest("fen_index");
//客户端执行创建请求 createIndexResponse是请求后的响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
//获取索引,判断其是否存在
@Test
void getIndex() throws IOException {
//创建索引请求
GetIndexRequest request = new GetIndexRequest("fen_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);//true
}
//删除索引
@Test
void deleteIndex() throws IOException {
//创建索引请求
DeleteIndexRequest request = new DeleteIndexRequest("feng_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());//true
}
//添加文档
@Test
void addDocument() throws IOException {
//创建对象
User user1 = new User("张", 14);
//创建索引请求
IndexRequest request = new IndexRequest("fen_index");
//规则--不加也行
request.id("1");
request.type("_doc");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//将我们的数据放入请求--json
request.source(JSON.toJSONString(user1), XContentType.JSON);
//客户端发送请求,获取响应结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
}
//获取文档--判断是否存在 get /index/doc/1
@Test
void testExistsDocument() throws IOException {
GetRequest getRequest = new GetRequest("fen_index", "_doc", "1");
// 不获取_source上下文 storedFields
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
// 判断此id是否存在!
boolean exists = client.exists(getRequest,
RequestOptions.DEFAULT);
System.out.println(exists);
}
//获取文档信息
@Test
void getDocument() throws IOException {
GetRequest getRequest = new GetRequest("fen_index", "_doc", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());//打印文档的内容
System.out.println(getResponse);//打印文档所有信息
}
//更新文档信息
@Test
void updateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("fen_index", "_doc", "1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
User user = new User("狂神说", 19);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = client.update(
request, RequestOptions.DEFAULT);
System.out.println(updateResponse.status() == RestStatus.OK);
}
// 删除文档测试
@Test
void testDelete() throws IOException {
DeleteRequest request = new DeleteRequest("kuang_index", "_doc", "3");
//timeout
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(
request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status() == RestStatus.OK);
}
// 批量添加文档
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//timeout
bulkRequest.timeout(TimeValue.timeValueMinutes(2));
bulkRequest.timeout("2m");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("kuangshen1", 3));
userList.add(new User("kuangshen2", 3));
userList.add(new User("kuangshen3", 3));
userList.add(new User("qinjiang1", 3));
userList.add(new User("qinjiang2", 3));
userList.add(new User("qinjiang3", 3));
for (int i = 0; i < userList.size(); i++) {
bulkRequest
.add(new IndexRequest("fen_index")
.id("" + (i + 1))
.source(JSON.toJSONString(userList.get(i)), XContentType.JSON));
}
// bulk
BulkResponse bulkResponse =
client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(!bulkResponse.hasFailures());
}
// 查询测试
/**
* 使用QueryBuilder
* termQuery("key", obj) 完全匹配
* termsQuery("key", obj1, obj2..) 一次匹配多个值
* matchQuery("key", Obj) 单个匹配, field不支持通配符, 前缀具高级特性
* multiMatchQuery("text", "field1", "field2"..); 匹配多个字段, field有通
配符忒行
* matchAllQuery(); 匹配所有文件
*/
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("fen_index");
//构造查询条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","qinjiang1");
MatchAllQueryBuilder matchAllQueryBuilder =
QueryBuilders.matchAllQuery();
sourceBuilder.query(matchAllQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse response = client.search(searchRequest,
RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(response.getHits()));
System.out.println("================SearchHit==================");
for (SearchHit documentFields : response.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
}
六:项目
:用jsoup从京东官网获取数据(标题,照片,价格),然后通过代码把一条条数据放在es索引中,然后再通过代码把数据展示给前端
es配置
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
)
);
return client;
}
}导入前端
创建content实体类
public class Content {
private String title;
private String img;
private String price;创建工具类
:解析网页到content中
@Component
public class HtmlParaseUtil {
//进行测试
public static void main(String[] args) throws Exception {
List<Object> list = new HtmlParaseUtil().parseJD("hello");
//list.forEach(System.out::println);
}
public List<Object> parseJD(String keywords) throws Exception{
//获得请求:https://search.jd.com/Search?keyword=java
//记住要联网
String url="https://search.jd.com/Search?keyword="+keywords;
//解析网页(Jsoup返回Document就是浏览器Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
//所有你在js中可以使用的方法,这里都能使用
Element element = document.getElementById("J_goodsList");
System.out.println(element.html());
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList<Object> goodList = new ArrayList<>();
//获取元素中的内容,这里el就是每一个li标签
for (Element el : elements) {
//关于这种图片特别多的网站,所有图片都是延迟加载的
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
//System.out.println("==================");
//System.out.println(img);
//System.out.println(price);
//System.out.println(title);
Content content = new Content();
content.setPrice(price);
content.setImg(img);
content.setTitle(title);
goodList.add(content);
//System.out.println(goodList);
}
return goodList;
}
}
业务层
1:调用HtmlParaseUtil工具类把京东官网数据封装到content中,然后再将content放在es
2:把es数据展示给前端(通过title条件匹配)
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
//1.解析京东网页的数据,然后放入es索引中
public Boolean parseContent(String keywords) throws Exception {
List<Object> contentList = new HtmlParaseUtil().parseJD(keywords);
//把查询到的数据放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contentList.size(); i++) {
bulkRequest.add(new IndexRequest("jd_goods").source(JSON.toJSONString(contentList.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return bulk.hasFailures();
}
//2.获取这些数据实现搜索功能
public List<Map<String,Object>> searchPage(String keyword,int PageNo,int pageSize) throws IOException {
if (PageNo<=1){
PageNo=1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(PageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
//2.获取这些数据实现搜索功能
public List<Map<String,Object>> searchPage2(String keyword,int PageNo,int pageSize) throws IOException {
if (PageNo<=1){
PageNo=1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(PageNo);
sourceBuilder.size(pageSize);
//精准匹配
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);//多个高亮显示
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果
//解析高亮的字段,将原来的字段替换为我们高亮的字段
if (title!=null){
Text[] fragments = title.fragments();
String n_title="";
for (Text text : fragments) {
n_title+=text;
}
sourceAsMap.put("title",n_title);//高亮字段替换掉原来的内容即可
}
list.add(sourceAsMap);
}
return list;
}
}
控制层
这是我们自己的网站,写入文字点击搜索,就会跳转到
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
@Controller//默认界面--到达我们自己定义的界面
public class indexController {
@GetMapping({"/","/index"})
public String index(){
return "index";
}
}
ContentController里分别调用两个业务,分别是把京东官网数据存es中,获取es数据展示给前端
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keywords) throws Exception {
return contentService.parseContent(keywords);
}
@GetMapping("/search1/{keyword}/{pageNo}/{pageSize}")//没有高亮显示,其他一样
public List<Map<String, Object>> search1(@PathVariable("keyword") String
keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws Exception {
return contentService.searchPage(keyword,pageNo,pageSize);
}
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")//有高亮显示,其他部分一样
public List<Map<String, Object>> search(@PathVariable("keyword") String
keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws Exception {
return contentService.searchPage2(keyword,pageNo,pageSize);
}
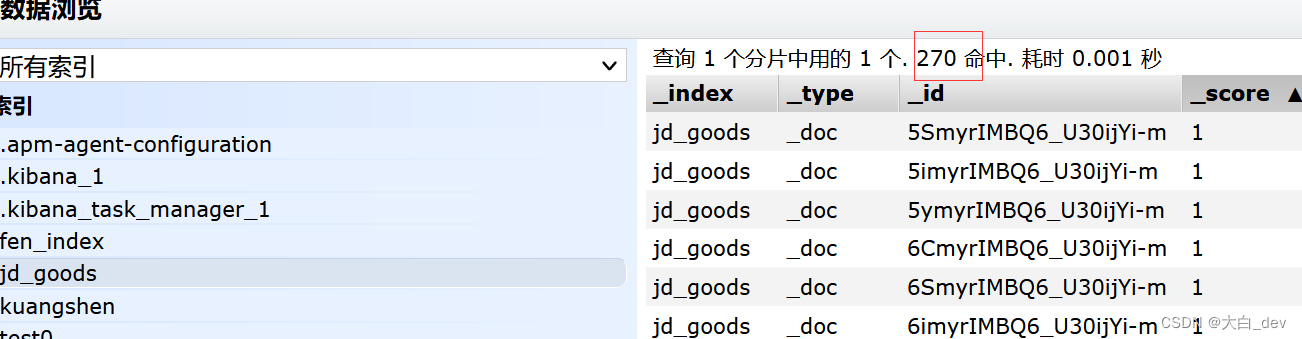
}访问parse后,就是把京东数据放在es了(通过head可以查看到)

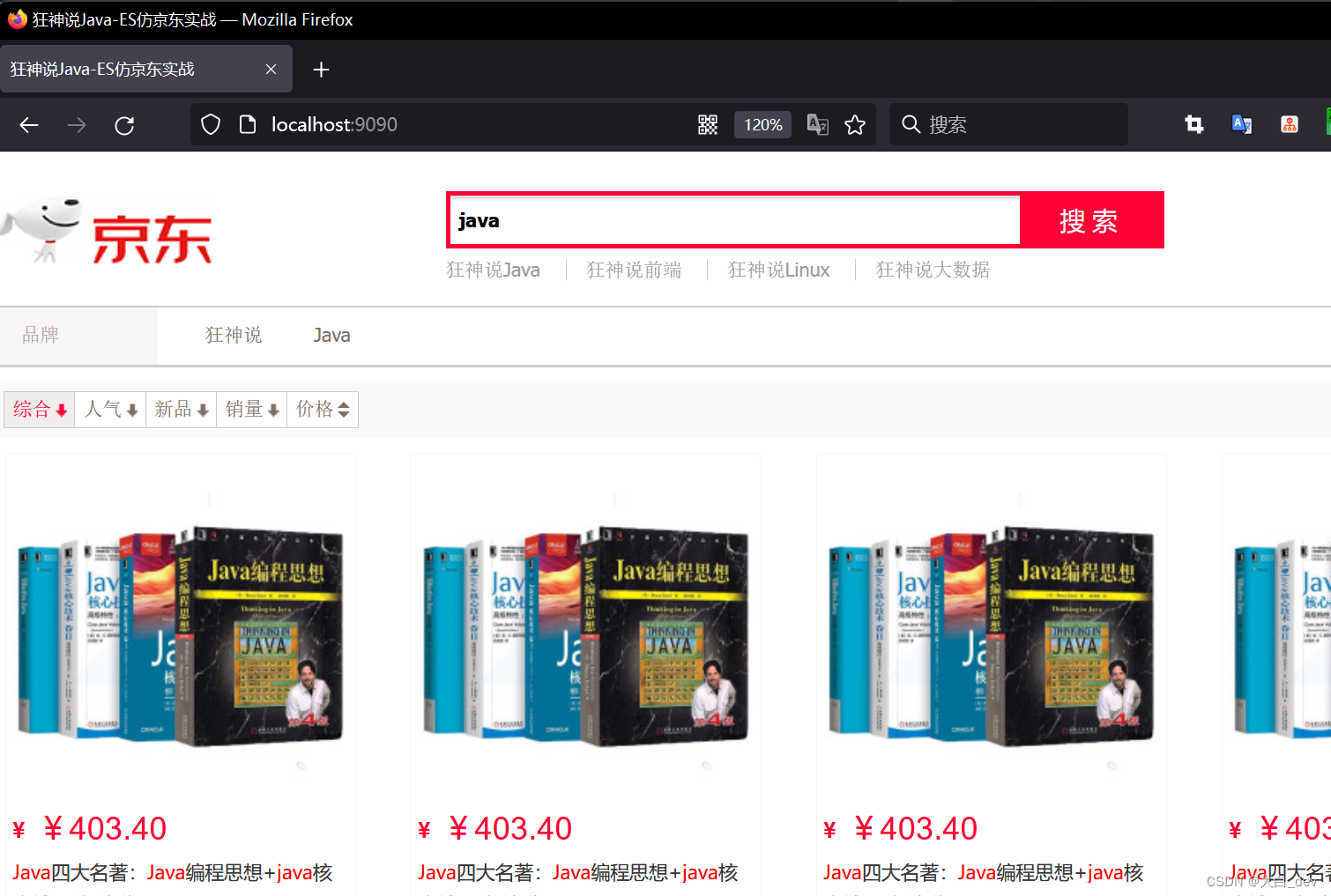
在我们的网站,点击“java”搜索,就会跳转到
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
然后就会从es中取出数据展示给前端啦

















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









