







 本文详细介绍了Elasticsearch中的分词器类型,包括预处理、分词和过滤过程,以及标准分词器、简单分词器、空白分词器和特定语言分词器的示例。此外,还探讨了text和querystring字段的全 文检索区别,以及如何管理mapping。文章还涵盖了数据类型、日期格式、自定义分词器和动态映射的配置,并展示了如何使用Java API进行索引操作,包括创建、删除和更新。最后,提到了ES中的索引管理和安全措施,如防止恶意删除索引。
本文详细介绍了Elasticsearch中的分词器类型,包括预处理、分词和过滤过程,以及标准分词器、简单分词器、空白分词器和特定语言分词器的示例。此外,还探讨了text和querystring字段的全 文检索区别,以及如何管理mapping。文章还涵盖了数据类型、日期格式、自定义分词器和动态映射的配置,并展示了如何使用Java API进行索引操作,包括创建、删除和更新。最后,提到了ES中的索引管理和安全措施,如防止恶意删除索引。
分词器分类
1、character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
2、tokenizer:分词,hello you and me --> hello, you, and, me
3、token filter:lowercase,stop word,synonymom,dogs --> dog,liked --> like,Tom --> tom,a/the/an --> 干掉,mother --> mom,small --> little
stop word 停用词: 了 的 呢。
例句:Set the shape to semi-transparent by calling set_trans(5)
standard analyzer标准分词器:set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)
simple analyzer简单分词器:set, the, shape, to, semi, transparent, by, calling, set, trans
whitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
language analyzer(特定的语言的分词器,比如说,english,英语分词器):set, shape, semi, transpar, call, set_tran, 5
当然还有IK分词器,…也可以自定义分词规则
text:属性才会全文检索
query string必须以和index建立时相同的analyzer进行分词
query string对exact value和full text的区别对待
如: date:exact value 精确匹配
text: full text 全文检索
测试分词器
mapping总结
(1)往es里面直接插入数据,es会自动建立索引,同时建立对应的mapping。(dynamic mapping)
(2)mapping中就自动定义了每个field的数据类型
(3)不同的数据类型(比如说text和date),可能有的是exact value,有的是full text
(4)exact value,在建立倒排索引的时候,分词的时候,是将整个值一起作为一个关键词建立到倒排索引中的;full text,会经历各种各样的处理,分词,normaliztion(时态转换,同义词转换,大小写转换),才会建立到倒排索引中。
(5)同时呢,exact value和full text类型的field就决定了,在一个搜索过来的时候,对exact value field或者是full text field进行搜索的行为也是不一样的,会跟建立倒排索引的行为保持一致;比如说exact value搜索的时候,就是直接按照整个值进行匹配,full text query string,也会进行分词和normalization再去倒排索引中去搜索
(6)可以用es的dynamic mapping,让其自动建立mapping,包括自动设置数据类型;也可以提前手动创建index和tmapping,自己对各个field进行设置,包括数据类型,包括索引行为,包括分词器,等。
核心数据leix
string :text and keyword
byte,short,integer,long,float,double
boolean
date
手动管理mapping
查看映射 GET book/_mapping
创建索引
PUT book/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"analyzer":"english",
"search_analyzer":"english"
},
"pic":{
# keyword == "type":"text", "index":false , 按照整体进行索引,不可以进行分词,例如身份证号码,图片路径地址等,图书分类等...
"type" :"keyword"
/* "type":"text",
"index":false */
},
"studymodel":{
"type":"text"
}
}
}
## 自定义时间格式
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
}
存储小数
"price": {
"type": "scaled_float",
"scaling_factor": 100 },
由于比例因子为100,如果我们输入的价格是23.45则ES中会将23.45乘以100存储在ES中。
如果输入的价格是23.456,ES会将23.456乘以100再取一个接近原始值的数,得出2346。
使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间
新增字段
PUT /book/_mapping/
{
"properties" : {
"new_field" : {
"type" : "text",
"index": "false"
}
}
}
复杂数据类型
1 myltivalue field
{ “tags”: [ “tag1”, “tag2” ]}
2. empty field
null,
[] : 存空数组,
[null] : 存空数组
3.对象类型的存储!!
1.添加一条数据
PUT /company/_doc/1
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2019-01-01"
}
2. 查看他的mapping
GET /company/_mapping
{
"company" : {
"mappings" : {
# 复杂对象类型 会再加一个 properties
"properties" : {
"address" : {
"properties" : {
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"country" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"province" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"age" : {
"type" : "long"
},
"join_date" : {
"type" : "date"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
} } } }}
对象的底层存储结构
{
"name": [jack],
"age": [27],
"join_date": [2017-01-01],
"address.country": [china],
"address.province": [guangdong],
"address.city": [guangzhou]
}
4.对象数组的存储
{
"authors": [
{ "age": 26, "name": "Jack White"},
{ "age": 55, "name": "Tom Jones"},
{ "age": 39, "name": "Kitty Smith"}
]
}
他的存储格式
{
"authors.age": [26, 55, 39],
"authors.name": [jack, white, tom, jones, kitty, smith]
}
索引index入门
创建索引
PUT my_index
{
# 关于索引的设置
"settings": {
#创建完毕后 主分片是不能修改的 ,副本分片是可以修改的
"number_of_shards": 1
, "number_of_replicas": 1
}
#设置索引的映射
, "mappings": {
"properties": {
"f1":{
"type": "text"
},
"f2":{
"type": "text"
}
}
},
#给他起别名 使用别名相当于使用该索引
"aliases": {
"default_indexck": {}
}
}
修改索引
PUT /my_index/_settings
{
"index" : {
"number_of_replicas" : 2
}
}
删除索引
DELETE /my_index
DELETE /index_one,index_two
#删除以index_ 开头的索引
DELETE /index_*
#删除所有索引 ,删库跑路
DELETE /_all
为了安全起见,防止恶意删除索引,删除时必须指定索引名:
elasticsearch.yml
action.destructive_requires_name: true
定制分词器
standard
分词三个组件,character filter,tokenizer,token filter
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
修改分词器的设置
- 启用english停用词token filter
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
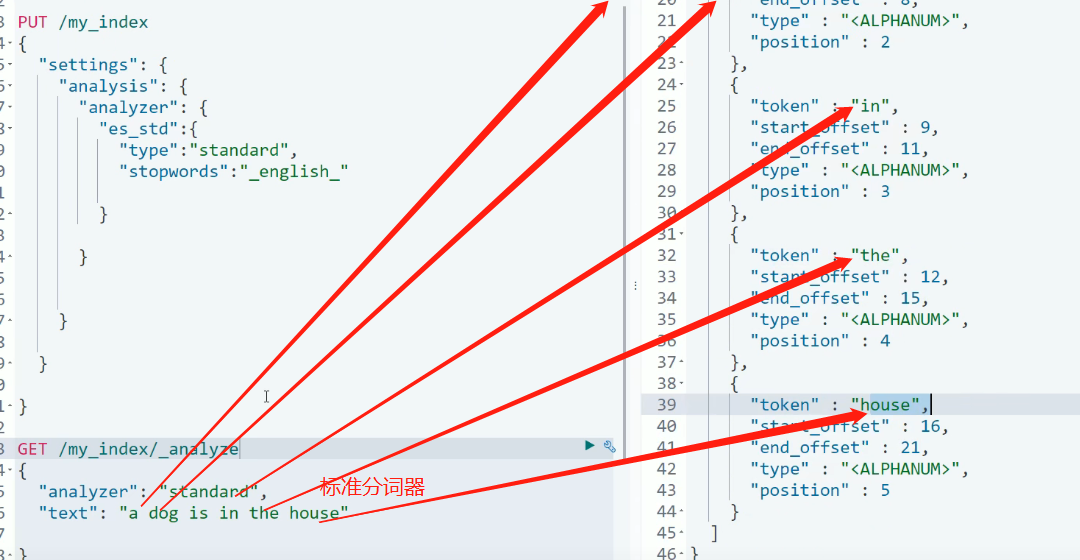
标志分词器
GET /my_index/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}
es_stop 分词器
GET /my_index/_analyze
{
"analyzer": "es_std",
"text":"a dog is in the house"
}

定制化自己的分词器
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
}
},
#定制停用词
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
## 真正定义自己的分词器
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "&_to_and"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
为什么type被弃用
所有type类型共用一个mapping
同一索引下,不同type的数据存储其他type的field 大量空值,造成资源浪费。
所以,不同类型数据,要放到不同的索引中。
es9中,将会彻底删除type。
定制dynamic mapping
-
true:遇到陌生字段,就进行dynamic mapping
-
false:新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍将出现在返回点击的源字段中。这些字段不会添加到映射中,必须显式添加新字段。
-
strict:遇到陌生字段,就报错
DELETE my_index
PUT /my_index
{
"mappings": {
##
"dynamic": false,
##
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
PUT /my_index/_doc/1
{
"title": "my article",
"content": "this is my article",
"address": {
"province": "guangdong",
"city": "guangzhou"
}
}
GET /my_index/_doc/1
#查不到数据 ,因为 设置的映射里面没有他 content
GET my_index/_search?q=content:article
#可以查出数据来
GET my_index/_search?q=title:article
日期探测
关掉日期探测 不会自动映射 成日期类型
默认会按照一定格式识别date,比如yyyy-MM-dd。但是如果某个field先过来一个2017-01-01的值,就会被自动dynamic mapping成date,后面如果再来一个"hello world"之类的值,就会报错。可以手动关闭某个type的date_detection,如果有需要,自己手动指定某个field为date类型。
PUT /my_index
{
"mappings": {
# ***
"date_detection": false,
# ***
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
自定义日期格式
PUT my_index
{
"mappings": {
"dynamic_date_formats": ["MM/dd/yyyy"]
}
}
# 插入数据
PUT my_index/_doc/1
{
"create_date": "09/25/2019"
}
numeric_detection 数字探测
虽然json支持本机浮点和整数数据类型,但某些应用程序或语言有时可能将数字呈现为字符串。通常正确的解决方案是显式地映射这些字段,但是可以启用数字检测(默认情况下禁用)来自动完成这些操作。
PUT my_index
{
"mappings": {
"numeric_detection": true
}
}
PUT my_index/_doc/1
{
"my_float": "1.0",
"my_integer": "1"
}
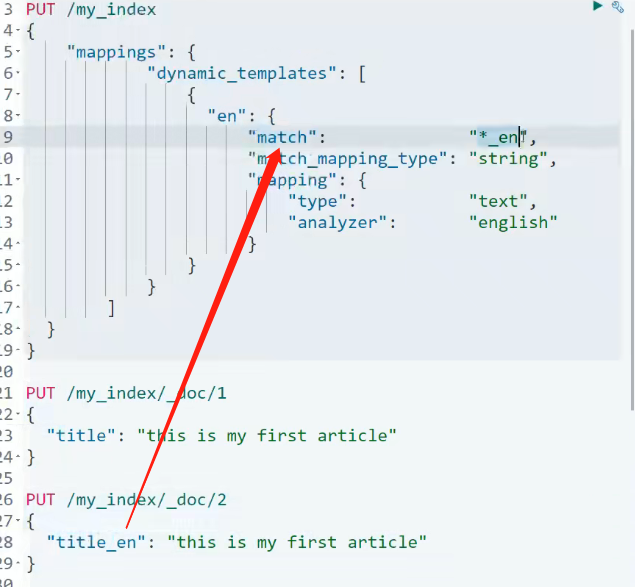
自定义动态映射
PUT /my_index
{
"mappings": {
"dynamic_templates": [
{
# 自定义的 动态映射 en
"en": {
"match": "*_en",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "english"
}
}
}
]
}
}
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
]
}
}
零停机重建索引
场景:
一个field的设置是不能被修改的,如果要修改一个Field,那么应该重新按照新的mapping,建立一个index,然后将数据批量查询出来,重新用bulk api写入index中。
批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来reindex数据,每次scoll就查询指定日期的一段数据,交给一个线程即可。
(1)一开始,依靠dynamic mapping,插入数据,但是不小心有些数据是2019-09-10这种日期格式的,所以title这种field被自动映射为了date类型,实际上它应该是string类型的
ik分词器能干吗
中文分词,还可以连接数据库进行 热更新词库
java api 操作索引
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.admin.indices.alias.Alias;
import org.elasticsearch.action.admin.indices.close.CloseIndexRequest;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.open.OpenIndexRequest;
import org.elasticsearch.action.admin.indices.open.OpenIndexResponse;
import org.elasticsearch.action.support.ActiveShardCount;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
/**
- @author Administrator
- @version 1.0
**/
@SpringBootTest
@RunWith(SpringRunner.class)
public class TestIndex {
@Autowired
RestHighLevelClient client;
// @Autowired
// RestClient restClient;
```
//创建索引
@Test
public void testCreateIndex() throws IOException {
//创建索引对象
CreateIndexRequest createIndexRequest = new CreateIndexRequest("itheima_book");
//设置参数
createIndexRequest.settings(Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0"));
//指定映射1
createIndexRequest.mapping(" {\n" +
" \t\"properties\": {\n" +
" \"name\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\":\"long\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\":\"text\",\n" +
" \"index\":false\n" +
" }\n" +
" \t}\n" +
"}", XContentType.JSON);
//指定映射2
```
// Map<String, Object> message = new HashMap<>();
// message.put("type", "text");
// Map<String, Object> properties = new HashMap<>();
// properties.put("message", message);
// Map<String, Object> mapping = new HashMap<>();
// mapping.put("properties", properties);
// createIndexRequest.mapping(mapping);
```
//指定映射3
```
// XContentBuilder builder = XContentFactory.jsonBuilder();
// builder.startObject();
// {
// builder.startObject("properties");
// {
// builder.startObject("message");
// {
// builder.field("type", "text");
// }
// builder.endObject();
// }
// builder.endObject();
// }
// builder.endObject();
// createIndexRequest.mapping(builder);
```
//设置别名
createIndexRequest.alias(new Alias("itheima_index_new"));
// 额外参数
//设置超时时间
createIndexRequest.setTimeout(TimeValue.timeValueMinutes(2));
//设置主节点超时时间
createIndexRequest.setMasterTimeout(TimeValue.timeValueMinutes(1));
//在创建索引API返回响应之前等待的活动分片副本的数量,以int形式表示
createIndexRequest.waitForActiveShards(ActiveShardCount.from(2));
createIndexRequest.waitForActiveShards(ActiveShardCount.DEFAULT);
//操作索引的客户端
IndicesClient indices = client.indices();
//执行创建索引库
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT);
//得到响应(全部)
boolean acknowledged = createIndexResponse.isAcknowledged();
//得到响应 指示是否在超时前为索引中的每个分片启动了所需数量的碎片副本
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged();
System.out.println("!!!!!!!!!!!!!!!!!!!!!!!!!!!" + acknowledged);
System.out.println(shardsAcknowledged);
}
//异步新增索引
@Test
public void testCreateIndexAsync() throws IOException {
//创建索引对象
CreateIndexRequest createIndexRequest = new CreateIndexRequest("itheima_book2");
//设置参数
createIndexRequest.settings(Settings.builder().put("number_of_shards", "1").put("number_of_replicas", "0"));
//指定映射1
createIndexRequest.mapping(" {\n" +
" \t\"properties\": {\n" +
" \"name\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\":\"long\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\":\"text\",\n" +
" \"index\":false\n" +
" }\n" +
" \t}\n" +
"}", XContentType.JSON);
//监听方法
ActionListener<CreateIndexResponse> listener =
new ActionListener<CreateIndexResponse>() {
@Override
public void onResponse(CreateIndexResponse createIndexResponse) {
System.out.println("!!!!!!!!创建索引成功");
System.out.println(createIndexResponse.toString());
}
@Override
public void onFailure(Exception e) {
System.out.println("!!!!!!!!创建索引失败");
e.printStackTrace();
}
};
//操作索引的客户端
IndicesClient indices = client.indices();
//执行创建索引库
indices.createAsync(createIndexRequest, RequestOptions.DEFAULT, listener);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
```
```
}
```
```
//删除索引库
@Test
public void testDeleteIndex() throws IOException {
//删除索引对象
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("itheima_book2");
//操作索引的客户端
IndicesClient indices = client.indices();
//执行删除索引
AcknowledgedResponse delete = indices.delete(deleteIndexRequest, RequestOptions.DEFAULT);
//得到响应
boolean acknowledged = delete.isAcknowledged();
System.out.println(acknowledged);
}
//异步删除索引库
@Test
public void testDeleteIndexAsync() throws IOException {
//删除索引对象
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("itheima_book2");
//操作索引的客户端
IndicesClient indices = client.indices();
//监听方法
ActionListener<AcknowledgedResponse> listener =
new ActionListener<AcknowledgedResponse>() {
@Override
public void onResponse(AcknowledgedResponse deleteIndexResponse) {
System.out.println("!!!!!!!!删除索引成功");
System.out.println(deleteIndexResponse.toString());
}
@Override
public void onFailure(Exception e) {
System.out.println("!!!!!!!!删除索引失败");
e.printStackTrace();
}
};
//执行删除索引
indices.deleteAsync(deleteIndexRequest, RequestOptions.DEFAULT, listener);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// Indices Exists API
@Test
public void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("itheima_book");
request.local(false);//从主节点返回本地信息或检索状态
request.humanReadable(true);//以适合人类的格式返回结果
request.includeDefaults(false);//是否返回每个索引的所有默认设置
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
```
```
// Indices Open API
@Test
public void testOpenIndex() throws IOException {
OpenIndexRequest request = new OpenIndexRequest("itheima_book");
OpenIndexResponse openIndexResponse = client.indices().open(request, RequestOptions.DEFAULT);
boolean acknowledged = openIndexResponse.isAcknowledged();
System.out.println("!!!!!!!!!"+acknowledged);
}
// Indices Close API
@Test
public void testCloseIndex() throws IOException {
CloseIndexRequest request = new CloseIndexRequest("index");
AcknowledgedResponse closeIndexResponse = client.indices().close(request, RequestOptions.DEFAULT);
boolean acknowledged = closeIndexResponse.isAcknowledged();
System.out.println("!!!!!!!!!"+acknowledged);
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









