







进程和线程
进程和线程的关系
应用程序>程序=进程>线程
一个应用程序(APP)可以有多个进程,彼此相互独立。一个进程可以开启多个线程,相当于是分工完成进程任务。
比如一个辅瞄程序是一个进程,完成辅瞄过程中的所有任务;(辅瞄代码中的)相机任务是一个线程,只负责从相机(或本地视频)读取视频流,供其他线程使用。
进程和线程的区别
各个进程拥有独立的虚拟地址空间,也就是说进程间的数据相互隔离,不能直接访问。
同一进程的各个线程共享同一个虚拟地址空间,也就是一个线程可以直接访问另一个线程中的变量(如果知道地址)。
物理内存地址:实际硬件中的空间地址。
虚拟内存地址:程序中使用的内存地址。
操作系统为每个进程分配一块独立的虚拟内存,通过分段技术,由段选择子和段内偏移地址共同决定实际的物理地址。
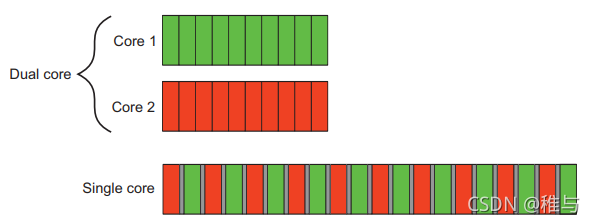
单核并发和多核并发
单核并发
伪并发。
以前的计算机系统中只有一颗CPU,且只有一个核心。在单核CPU上执行并发程序时,通过“任务切换”来模拟并发执行。
大部分情况下单核并发不会提速,反而会降速,因为CPU在切换上下文的过程中也会占用资源。
但是在某些特定情境下是非常有用的,比如在执行IO的时候,IO的线程被挂起,CPU去执行其他线程的操作,而不用一直阻塞等待IO结束。
多核并发
真并发。
每个线程执行在单独的核心上(所以核心数也会对线程数有限制),各个线程之间就不需要上下文切换了。
并发的分类
任务并发:也是通常理解的并发。一个任务划分为多个子任务。
数据并发:将数据分组,在不同组的数据上执行相同的操作。比如将图像分块,在不同块上同时跑检测线程。
C++并发库
- pthread:C语言风格
感觉细粒度小,可操作空间大。
- thread:C++ STL
基于pthread开发,用起来很方便,也很规范。实现还是偏底层的,速度也比较快。
内存模型
线程中变量存储模型
每个线程有独立的线程上下文,包括线程的栈空间和栈相关的一些通用寄存器(比如ebp,eip,cs等),用于存储局部变量、函数参数等。这些数据在每个线程中会有单独的副本,也是其他线程不能直接访问的。
当然,上面提到了,各个线程间也会共享进程的虚拟地址空间,所以包括全局变量和静态局部变量等,在线程中都只有唯一副本。也就是说,多个线程都需要用到的数据可以考虑初始化为全局变量。
但是由于各线程在同一虚拟地址空间中,所以不同线程内存空间是不设防的,可以通过参数传递等方式共享线程上下文中的数据。
创建线程和线程属性
- thread
- thread t1(func, params):创建线程,执行func函数,传入params
- thread t2(&A::func, &a, params):创建线程,执行a.func,传入params
- join
- t.join():阻塞当前线程,等待t线程执行完成之后继续。
- detach
- t.detach():分离t线程,二者不再相关。如果此时t线程中使用了共享数据,可能出现未定义的错误。
共享数据和互斥锁
共享数据
共享数据指可能被多个线程同时访问的数据。可以说数据共享是多线程存在的意义,但是数据共享的便捷性也会带来诸如数据竞争等一系列的问题。
数据竞争是指线程在读取某一共享变量的过程中,有一个或多个其他线程对该共享变量进行修改。这就使得读取到的是变量的中间状态,可能会引起未定义的错误。
互斥锁
-
mutex
通过互斥锁可以维护各个线程访问共享数据的顺序,一个互斥锁同一时间只能被一个线程获取,其他线程如果尝试获取锁,则会被阻塞,直到锁被释放之后才会获取锁。
互斥锁实际上并非是对数据上锁,只是对“锁”上锁。也就是说,如果一个线程使用锁,另一个线程不使用锁,或者使用另一个锁,那么此时互斥锁就失效了,没有起到防止数据竞争的效果。
同时,使用互斥锁也会带来死锁等问题。
mtx.lock()
mtx.unlock()
-
lock_guard
lock_guard会在变量初始化的时候自动上锁,析构的时候自动释放。
lock_guard<mutex> lock(mtx)
-
unique_lock
unique_lock是plus版的lock_guard,提供了暂时解锁的操作。
unique_lock<mutex> lock(mtx)
原子类型
C++11专门提供了一个新的泛型atomic,该类型变量默认只能被一个线程访问。
如果只是单个变量需要上锁,可以考虑这种方法
atmoic<T> value;
线程协同和条件变量
线程同步
在辅瞄多线程的任务中,不同线程之间不是完全独立的。理想情况下,相机线程刚读取完一张图像之后,检测线程就立即检测装甲,同时在相机读取图像的过程中不会一直阻塞等待,而是将CPU资源让给其他的任务。这就需要用到所谓的线程同步技术。
线程同步有很多种操作,使用比较广泛的是条件变量。当某个线程已经确定条件得到满足后,会通知一个或多个其他线程去执行在条件变量上等待的线程。
-
condition_variable
condition_variable有wait和notify_one / / /all()操作。
wait操作用于待同步线程,一般结合lambda表达式一起用(也可以直接用个while):
cv.wait(lock, [&]()->bool {return flag;}),表示flag为false时阻塞
notify_one / / /all操作用于唤醒在等待的线程
cv.notify_one(),唤醒+flag为true时,继续执行
demo:
// producer
unique_lock<mutex> lock(mtx);
...
flag = true;
cv.notify_all();
lock.unlock();
// consumer
unique_lock<mutex> lock(mtx);
cv.wait(lock, []()->bool{return flag;});
flag = false;
...
lock.unlock();
辅瞄中多线程的优化和helgrind
helgrind
helgrind是一个valgrind工具,用于检测基于PISIX(pthread)多线程的同步错误
helgrind可以检测出三种错误:
- api误用
- 死锁
- 数据竞争
在分析helgrind检测报告的过程中,发现了一个数据竞争的问题:
之前因为相机线程和检测线程间数据传输图像速度慢(1e6次计算量,差不多10ms,都跟跑一次检测差不多了),所以改成传递图像指针。即为图像分配一块内存,每次直接对内存数据做修改,然后传递指向内存的指针即可,使用图像的时候用常引用取出即可。实测是可以省10ms的。
但是这又引发了一个问题:在修改之后,原来对图像拷贝的操作变成了对指针拷贝的操作,所以此时互斥锁并没有起到保护图像数据的功能,只是保护了指针。图像内存中数据的修改并没有被保护,引发了大量的数据竞争。
现在大概的思路是使用一个滚动数组创建一个图像池,保存相机读取到的图像,每次取出正在修改的图像的前一帧将其指针送给检测线程,传递的时候使用一个二级指针即可。
constexpr int size = 2;
Mat frame[size];
// camera
static int id = 0;
video >> frame[id];
frame_p = &frame[(id-1)&1];
frame_pp = &frame_p;
//detector
const Mat& frame = **frame_pp;
优化率50%+


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









