







 本文介绍了自适应学习率优化算法,包括AdaGrad如何自适应调整每个参数的学习率,RMSprop通过指数衰减移动平均避免学习率过早衰减,以及AdaDelta算法在RMSprop基础上进一步平抑学习率波动。
本文介绍了自适应学习率优化算法,包括AdaGrad如何自适应调整每个参数的学习率,RMSprop通过指数衰减移动平均避免学习率过早衰减,以及AdaDelta算法在RMSprop基础上进一步平抑学习率波动。
目录
在上一遍文章中详细介绍了学习率衰减、学习率预热、周期性学习率调整几种方法,本文将主要介绍一些自适应调整学习率的方法,例如AdaGrad、RMSprop、 AdaDelta 等。想要了解学习率衰减、学习率预热、周期性学习率调整方法的朋友可以在文末找到链接入口。
一、AdaGrad算法
在标准的梯度下降法中
,
每个参数在每次迭代时都使用相同的学习率。
由于每个参数的维度上收敛速度都不相同,
因此需要根据不同参数的收敛情况分别设置学习率。
AdaGrad算法
(
Adaptive Gradient Algorithm
)是借鉴 ℓ2
正则化的思想
,
每次迭代时自适应地调整每个参数的学习率。
在第
𝑡
次迭代时
, 先计算每个参数梯度平方的累计值:
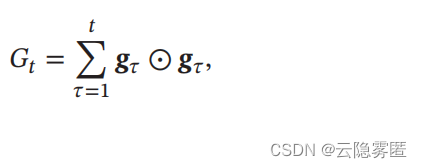
其中
⊙
为按元素乘积
,𝒈𝜏
∈ ℝ
|𝜃|
是第
𝜏
次迭代时的梯度。
AdaGrad
算法的参数更新差值为:
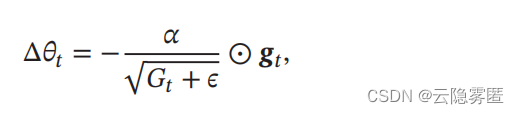
其中
𝛼
是初始的学习率
,𝜖 是为了保持数值稳定性而设置的非常小的常数
,
一般取值e
−7
到
e
−10。
此外
,
这里的开平方
、
除
、
加运算都是按元素进行的操作。
在 AdaGrad
算法中
,
如果某个参数的偏导数累积比较大
,
其学习率相对较小;
相反
,
如果其偏导数累积较小
,
其学习率相对较大。
但整体是随着迭代次数的增加,
学习率逐渐缩小。
AdaGrad
算法的缺点是在经过一定次数的迭代依然没有找到最优点时
,
由于这时的学习率已经非常小,
很难再继续找到最优点。
二、RMSprop算法
RMSprop算法
是
Geoff Hinton
提出的一种自适应学习率的方法
,
可以在有些情况下避免
AdaGrad
算法中学习率不断单调下降以至于过早衰减的缺点。
RMSprop
算法首先计算每次迭代梯度
𝒈
𝑡
平方的指数衰减移动平均:
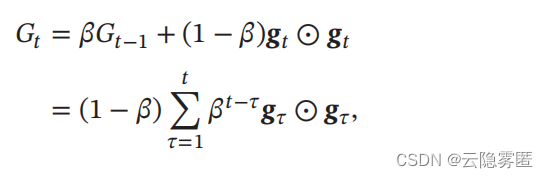
其中
𝛽
为衰减率
,
一般取值为
0.9。
RMSprop
算法的参数更新差值为:
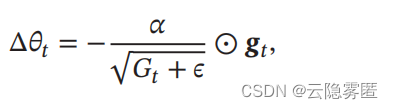
从上式可以看出
,
RMSProp
算法和
AdaGrad
算法的区别在于
𝐺
𝑡
的计算由累积方式变成了指数衰减移动平均。
在迭代过程中
,
每个参数的学习率并不是呈衰减趋势,而是
既可以变小也可以变大。
三、AdaDelta算法
AdaDelta 算法
也是
AdaGrad
算法的一个改进。
和
RMSprop算法类似,
AdaDelta
算法通过梯度平方的指数衰减移动平均来调整学习率。
此外,
AdaDelta
算法还引入了每次参数更新差值
Δ𝜃
的平方的指数衰减权移动平均。
第
𝑡
次迭代时
,
参数更新差值
Δ𝜃
的平方的指数衰减权移动平均为:
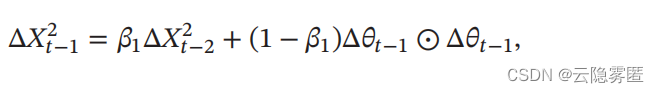
其中 𝛽1 为衰减率。此时 Δ𝜃𝑡 还未知,因此只能计算到Δ𝑋𝑡−1。
AdaDelta算法的参数更新差值为:
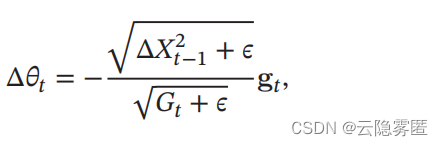
其中
𝐺𝑡 的计算方式和
RMSprop算法一样
,
Δ𝑋 ^2 (𝑡−1) 为参数更新差值 Δ𝜃 的指数衰减权移动平均。
从上式可以看出
,
AdaDelta
算法将
RMSprop
算法中的初始学习率
𝛼
改为动态计算的√Δ𝑋^2 (𝑡−1),在一定程度上平抑了学习率的波动。
四、学习率调整方法总结

相关文章链接:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









