







 本文介绍了如何在Spark环境中创建DataFrame,包括从HDFS文件加载数据,以及DataFrame的常用操作如选择、过滤、分组和排序。同时,展示了使用DSL和SQL语法进行数据查询的方法。
本文介绍了如何在Spark环境中创建DataFrame,包括从HDFS文件加载数据,以及DataFrame的常用操作如选择、过滤、分组和排序。同时,展示了使用DSL和SQL语法进行数据查询的方法。
环境准备:
打开Hadoop01,Hadoop02,Hadoop03
开启Hadoop环境
start-dfs.sh
start-yarn.sh
注意:
要查看一下spark/conf下的那个spark-env.sh文件有没有整合hdfs,一定要整合,不然待会下面运行时会报找不到路径的错误
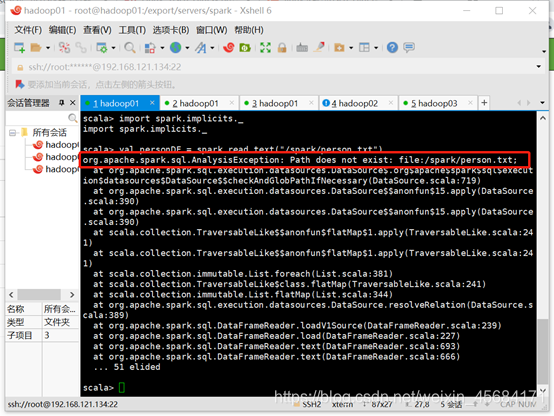
解决方法:
到spark/conf目录下修改spark-env.sh文件,整合hdfs
cd spark/conf/
vi spark-env.sh
添加:
export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.4/etc/Hadoop
分发
scp spark-env.sh hadoop02:/export/servers/spark/conf
scp spark-env.sh hadoop03:/export/servers/spark/conf
重启hadoop服务
stop-all.sh
start-all.sh
重启spark服务,spark/sbin下
stop-all.sh
start-all.sh
启动spark-shell
bin/spark-shell --master local[2]
然后重新运行
val personDF = spark.read.text( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









