






通过xxl-job剖析时间轮
前言
xxl-job 应该大多数小伙伴都接触过,xxl-job 是一个分布式任务调度平台。其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。其中的调度任务也用到了时间轮的概念。
1.什么是时间轮
简单来说,时间轮是一个高效利用线程资源进行批量化调度的调度器。首先把大批量的调度任务全部绑定到同一个调度器上,然后使用这个调度器对所有任务进行管理、触发、以及运行,所以时间轮能高效管理各种延时任务、周期任务、通知任务。
时间轮是以时间作为刻度组成的一个环形队列,所以叫做时间轮。这个环形队列通过一个HashedWheelBucket[]数组来实现,数组的每个元素称为槽,每个槽可以存放一个定时任务列表,叫HashedWheelBucket。HashedWheelBucket是一个双向链表,链表的每个节点表示一个定时任务项HashedWheelTimeout。在HashedWheelTimeout中封装了真正的定时任务TimerTask。
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度ticketDuration,其中时间轮的时间格的个数是固定的。
2.工作原理
时间轮算法(Time Wheel Algorithm)是一种用于处理定时任务和调度的常见算法。
时间轮算法主要需要定义一个时间轮盘,在一个时间轮盘中划分出多个槽位,每个槽位表示一个时间段,这个段可以是秒级、分钟级、小时级等等。如以下就是把一个时间轮分为了60个时间槽,每一个槽代表一秒钟。
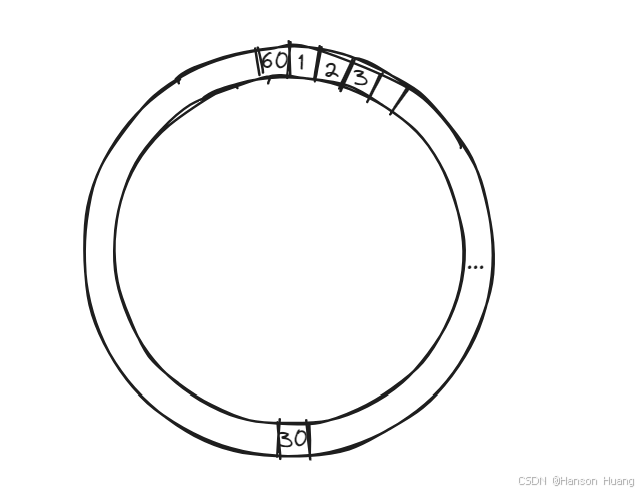
然后当我们有定时任务需要执行的时候,就把他们挂在到这些槽位中,这个任务将要在哪个槽位中执行,就把他挂在到哪个槽位的链表上。
比如当前如果是0秒,那么要3秒后执行,那就挂在槽位为3的那个位置上。
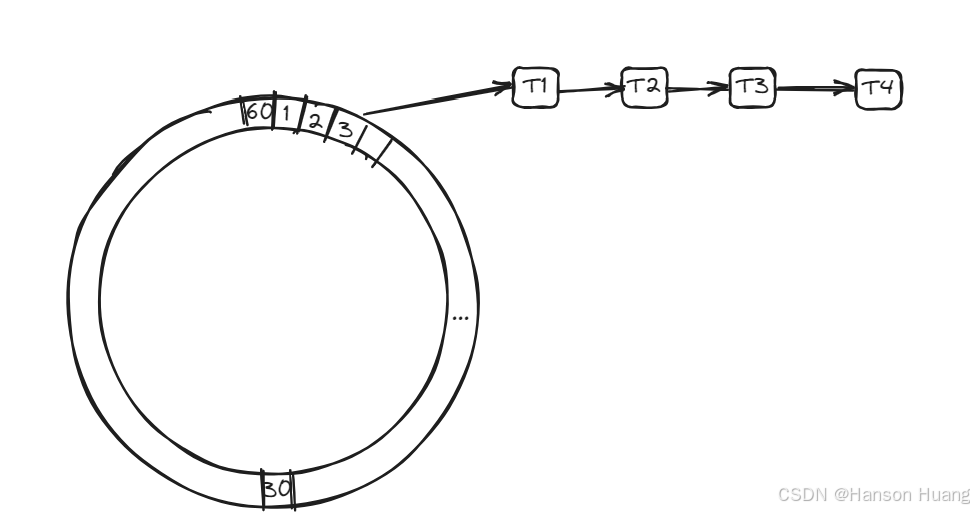
而随着时间的推移,轮盘不断旋转,任务会被定期触发。
因为这个时间轮是60个槽位,那么他就会在一分钟完整的转完一圈,那么就有一个指针,每一秒钟在槽位中进行一次移动。这个操作是有一个单独的线程来做的,他的工作就是每一秒钟改变一次current指针。
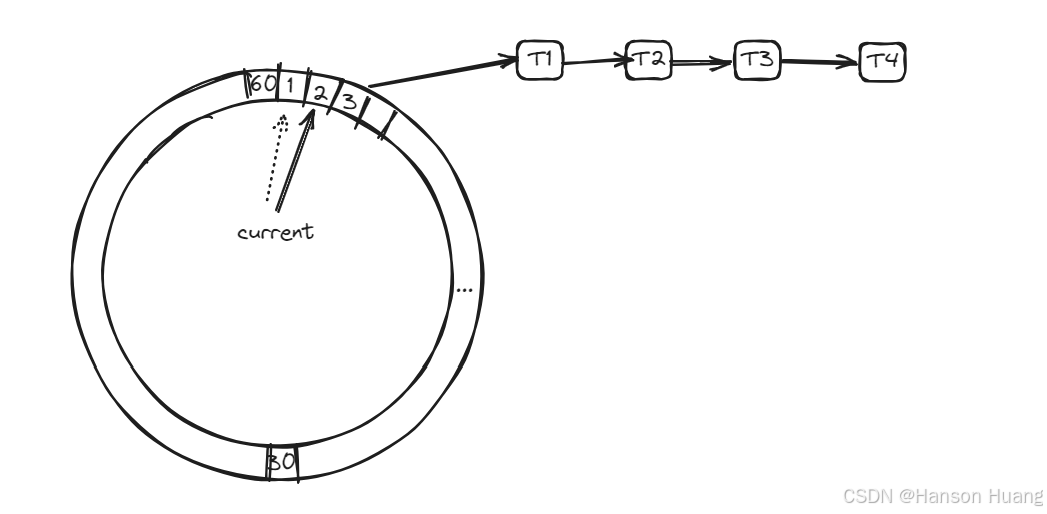
然后还有一个线程池,在指针轮转到某个槽位上的时候,在线程池中执行链表中需要执行的任务。
以上就是一个简单的时间轮算法,但是这个时间轮存在一个问题,那就是我们把它分了60个槽,那么就意味着我们的定时任务最多只支持60s以内的。
那么,怎么解决这个问题呢?
首先能想到的最简单的方式就是加槽位,比如我要支持5分钟的延迟任务,那么就可以把槽位设置为300个。
还有就是也可以调整时间轮槽位移动的延迟,比如把1秒钟移动一次,改为1分钟移动一次,那么就可以支撑60分钟的延迟任务了。
但是这两个办法都不够灵活,而且是有瓶颈的。于是有一种新的办法。
round
在时间轮中增加一个round的标识,标识运行的圈数,比如说上面的60s的时间轮,如果我要200s之后运行,那么我在设置这个任务的时候,就把他的round设置为 200/60 = 3 ,然后再把它放到 200%60 = 20的这个槽位上。
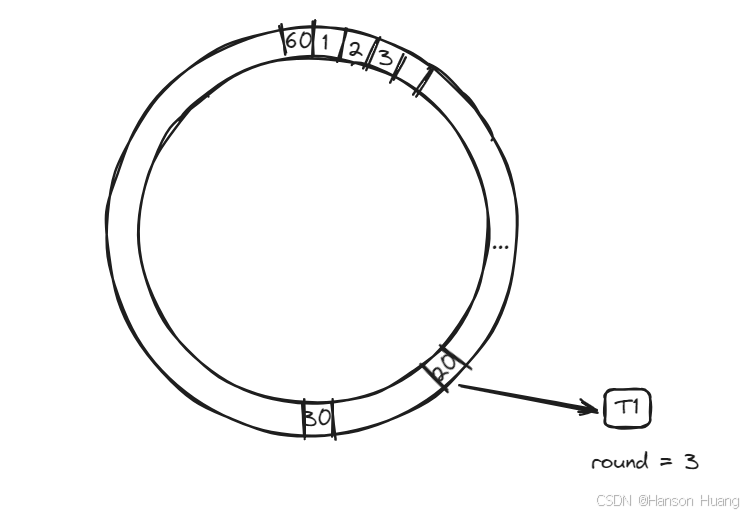
有了这个round之后,每一次current移动到某个槽位时,检查任务的round是不是为0,如果不为0,则减一。
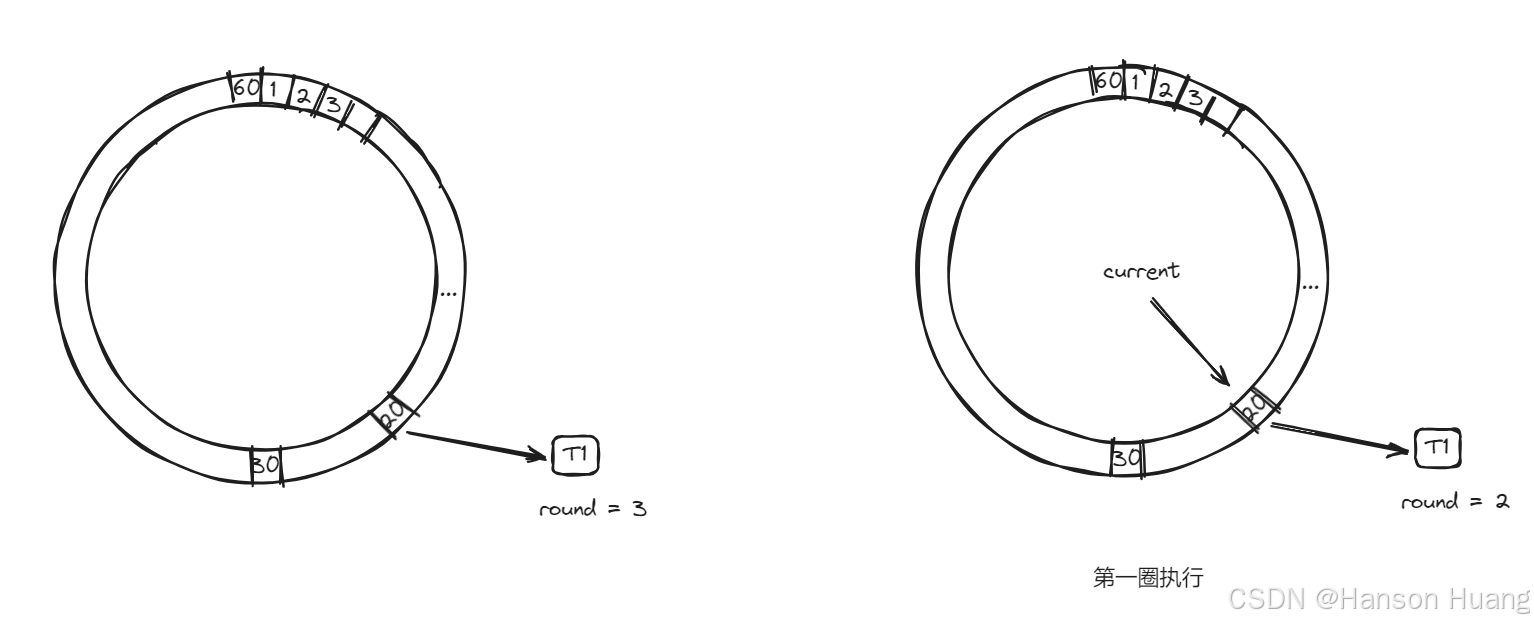
这样时间轮转到第三圈时,round的值会变成0,再第四圈运行到current=20的时候,发现round=0了,那么就可以执行这个任务了。
这样就解决了我们前面说的问题了。
但是这个方案还存在一个问题,那就是这个round的检查过程,需要把所有任务都遍历一遍,效率还是没那么高。
分层时间轮
为了解决遍历所有任务的问题,我们可以引入分层时间轮。我们在刚刚的秒级时间轮的基础上,在定义一个分钟级时间轮
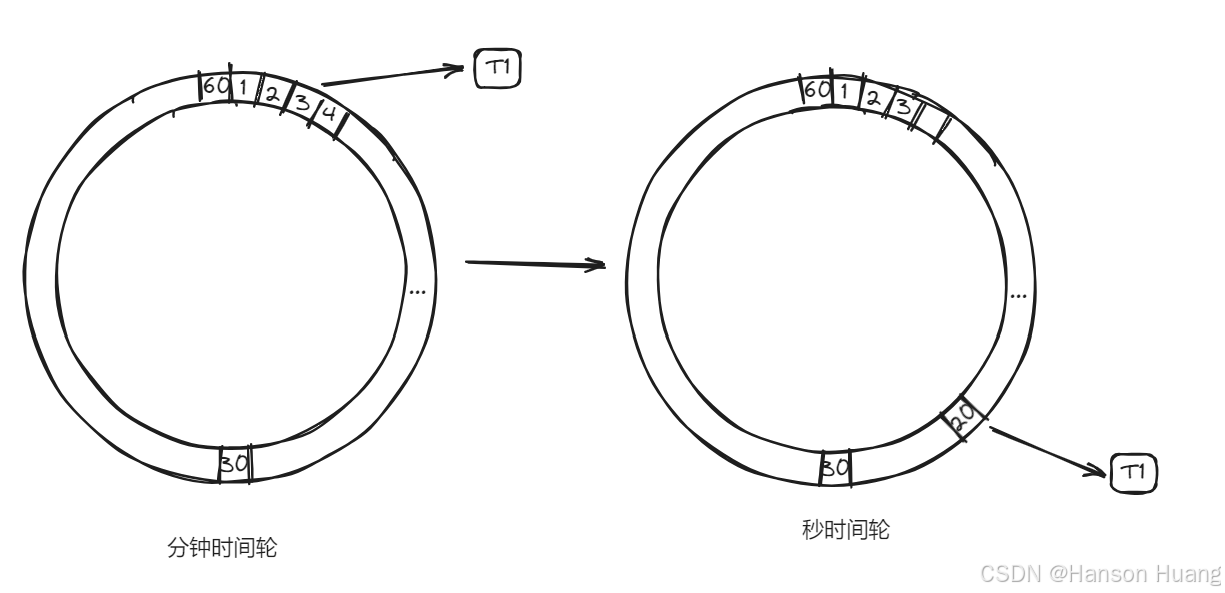
也就是说我们对于200s以后执行这个任务,我们先把他放到分钟级时间轮上,这个时间轮的槽位每一分钟移动一次,当移动时候,发现某个槽位上有这一分钟内需要执行的任务时。
把这个任务取出来,放到秒级时间轮中。这样在第3分20秒的时候,就可以运行这个任务了。
这就是分层时间轮。在分层时间轮包括多个级别的时间轮,每个级别的时间轮都有不同的粒度和周期。
通常,粒度较细的时间轮拥有更短的周期,而粒度较粗的时间轮拥有更长的周期。例如,分层时间轮可以包括毫秒级、秒级、分钟级等不同粒度的时间轮。
当一个任务需要被调度时,它被分配到适当级别的时间轮中,每个级别的时间轮都独立地旋转。当一个时间轮的指针到达某个位置时,它将触发执行该级别时间轮中的任务。如果某个任务在较粗的时间轮中已经到期,它将被升级到下一级时间轮。
当任务升级到下一级时间轮时,任务的调度粒度变得更细。这意味着任务将在更短的时间内被触发,从而更精确地满足其调度要求。
3.xxl-job中的时间轮
xxl-job源码:GitHub
xxl-job在做调度时,使用到了时间轮的概念,我先附上一段源码:
private volatile static Map<Integer, List<Integer>> ringData = new ConcurrentHashMap<>();
没错这行代码就是 xxl-job 中的时间轮,本质就是一个 ConcurrentHashMap,key 为执行的秒数,value 为要执行的 job 的 id列表。
那么ConcurrentHashMap中的数据是如何维护,如何管理的呢?
我们来看一下 xxl-job 中是如何做的, JobScheduleHelper 类。
xxl-job 源码
private Thread scheduleThread;
private Thread ringThread;
xxl-job 中用了两个线程:
-
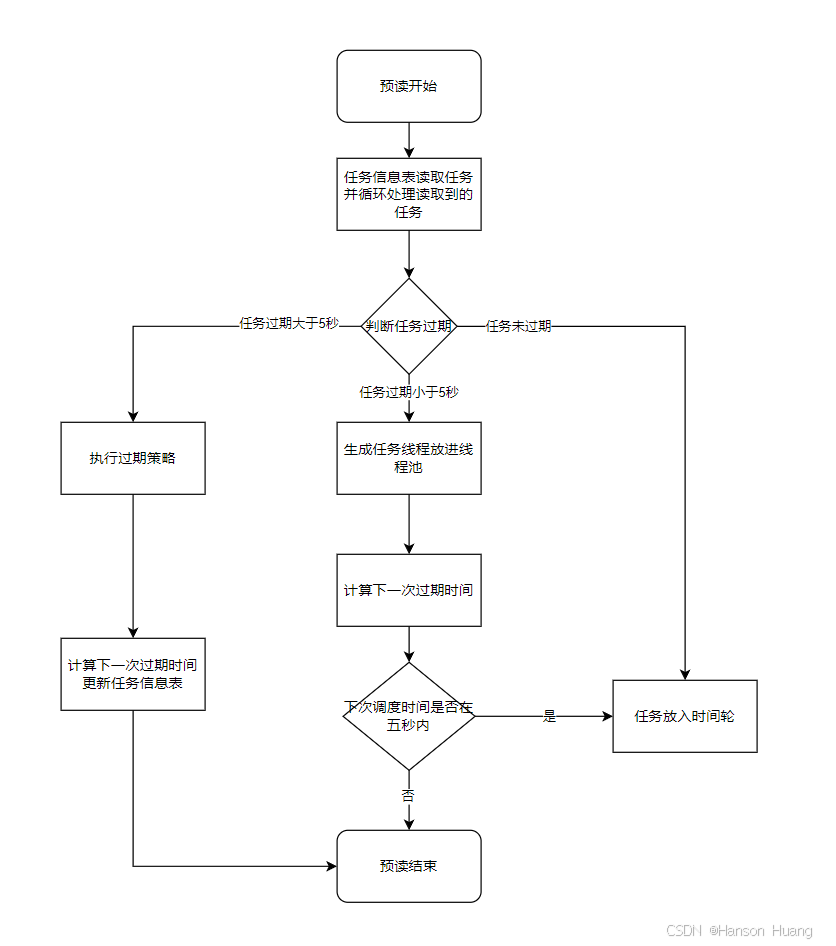
scheduleThread 线程:预读,计算下一次调度时间,过期任务根据配置策略处理,过期5秒内任务放入线程池,未过期任务放入时间轮。
-
ringThread 线程:时间轮调度,时间轮转动触发任务调度
scheduleThread线程
源码有些多,只保留了一些主要的代码。
scheduleThread = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>> init xxl-job admin scheduler success.");
// pre-read count: treadpool-size * trigger-qps (each trigger cost 50ms, qps = 1000/50 = 20)
int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20;
while (!scheduleThreadToStop) {
// Scan Job
long start = System.currentTimeMillis();
Connection conn = null;
Boolean connAutoCommit = null;
PreparedStatement preparedStatement = null;
boolean preReadSuc = true;
try {
conn = XxlJobAdminConfig.getAdminConfig().getDataSource().getConnection();
connAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
preparedStatement.execute();
// tx start
// 1、pre read
long nowTime = System.currentTimeMillis();
List<XxlJobInfo> scheduleList = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
if (scheduleList!=null && scheduleList.size()>0) {
// 2、push time-ring
for (XxlJobInfo jobInfo: scheduleList) {
// time-ring jump
if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) {
// 2.1、trigger-expire > 5s:pass && make next-trigger-time
logger.warn(">>>>>>>>>>> xxl-job, schedule misfire, jobId = " + jobInfo.getId());
// 1、misfire match
MisfireStrategyEnum misfireStrategyEnum = MisfireStrategyEnum.match(jobInfo.getMisfireStrategy(), MisfireStrategyEnum.DO_NOTHING);
if (MisfireStrategyEnum.FIRE_ONCE_NOW == misfireStrategyEnum) {
// FIRE_ONCE_NOW 》 trigger
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.MISFIRE, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId() );
}
// 2、fresh next
refreshNextValidTime(jobInfo, new Date());
} else if (nowTime > jobInfo.getTriggerNextTime()) {
// 2.2、trigger-expire < 5s:direct-trigger && make next-trigger-time
// 1、trigger
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId() );
// 2、fresh next
refreshNextValidTime(jobInfo, new Date());
// next-trigger-time in 5s, pre-read again
if (jobInfo.getTriggerStatus()==1 && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) {
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
} else {
// 2.3、trigger-pre-read:time-ring trigger && make next-trigger-time
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
// 3、update trigger info
for (XxlJobInfo jobInfo: scheduleList) {
XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleUpdate(jobInfo);
}
} else {
preReadSuc = false;
}
// tx stop
} catch (Exception e) {
if (!scheduleThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread error:{}", e);
}
} finally {
// commit
if (conn != null) {
try {
conn.commit();
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
try {
conn.setAutoCommit(connAutoCommit);
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
try {
conn.close();
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
// close PreparedStatement
if (null != preparedStatement) {
try {
preparedStatement.close();
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
}
long cost = System.currentTimeMillis()-start;
// Wait seconds, align second
if (cost < 1000) { // scan-overtime, not wait
try {
// pre-read period: success > scan each second; fail > skip this period;
TimeUnit.MILLISECONDS.sleep((preReadSuc?1000:PRE_READ_MS) - System.currentTimeMillis()%1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread stop");
}
});
scheduleThread.setDaemon(true);
scheduleThread.setName("xxl-job, admin JobScheduleHelper#scheduleThread");
scheduleThread.start();
源码中,最重要的部分是
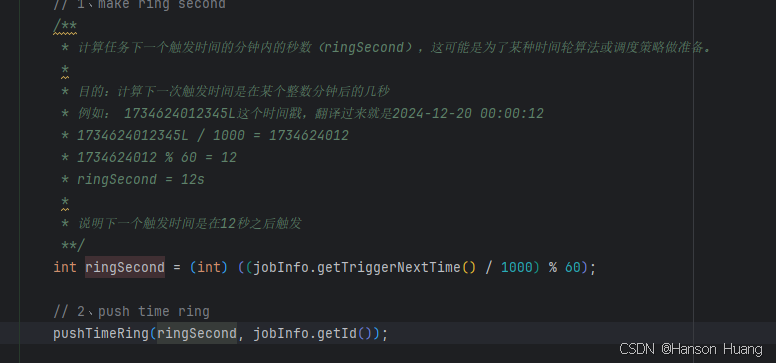
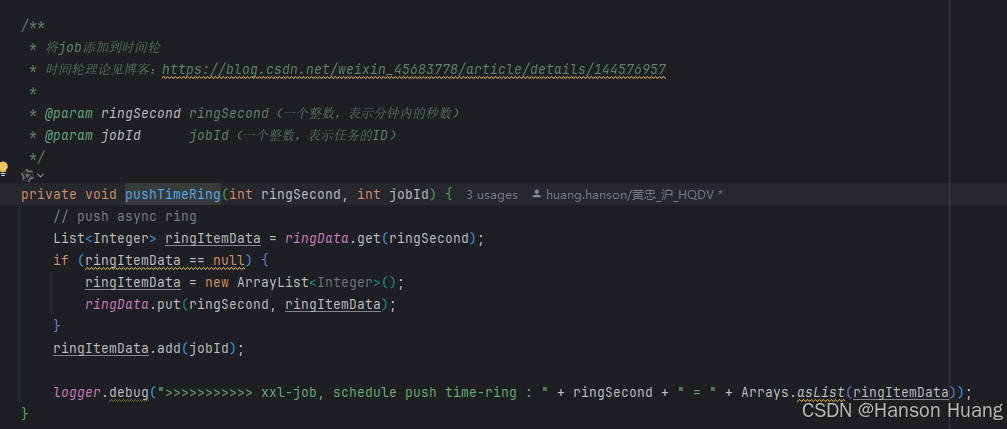
他将下一次触发的时间jobInfo.getTriggerNextTime() 除毫秒位1000,再去余60,这样就落在了60个槽的时间轮上,然后通过pushTimeRing,以取余后的秒数作为key,jobid作为value存在ringData中
-
定时任务调度:时间轮非常适合用于定时任务的调度。通过将任务按照触发时间划分到不同的槽中,可以实现对任务的精确触发和执行。例如,在分布式系统中,可以使用时间轮来实现定时任务的触发和调度。
-
超时管理:在网络通信或分布式系统中,经常需要管理请求的超时情况。时间轮可以用于管理和处理超时任务。每个槽可以存放一个超时请求,并在达到超时时间时触发相应的操作,例如重新发送请求或进行异常处理。
-
定时器:时间轮可以用于实现定时器功能。通过将计时任务加入时间轮的相应槽中,可以在预定的时间点触发执行定时任务。定时器广泛应用于各种需求,如批量处理、定时提醒、定时数据刷新等。
-
调度器:时间轮可用于实现任务调度器。通过将任务根据其优先级划分到不同的槽中,可以实现按优先级顺序触发执行任务。这在一些需要优先处理紧急任务的场景中非常有用。
-
缓存失效管理:在缓存系统中,需要管理缓存的失效时间。时间轮可以用于管理和处理缓存失效任务。每个槽可以存放一个缓存失效项,并在失效时间到达时触发相应的操作,例如更新缓存或重新加载数据。
通过合理使用时间轮,可以提高系统的任务调度效率和执行精度。
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









