







测试使用的Flink1.11.0版本,本文分为SQL和Streaming
一、配置及参数
1、配置jar包:
iceberg0.11.0版本,官网下载jar包,放到spark的lib目录下。
注意:
因为Flink链接Hive是通过Catalog进行操作的。所以需要提前进行Catalog链接创建。
不支持:delete/merge/insert overwrite。仅支持追加。
不支持:altert table 操作表。新增/删除/更改列。(如果需要改需使用spark引擎)
2022-01-07更新
官网更新了,流支持append 和 overwrite。
2、参数:
#切换执行类型=流
SET execution.type = streaming;
#切换执行类型=批次
SET execution.type = batch;
#启用此开关,因为流式读取SQL将在flink SQL提示选项中提供很少的作业选项
SET table.dynamic-table-options.enabled=true;
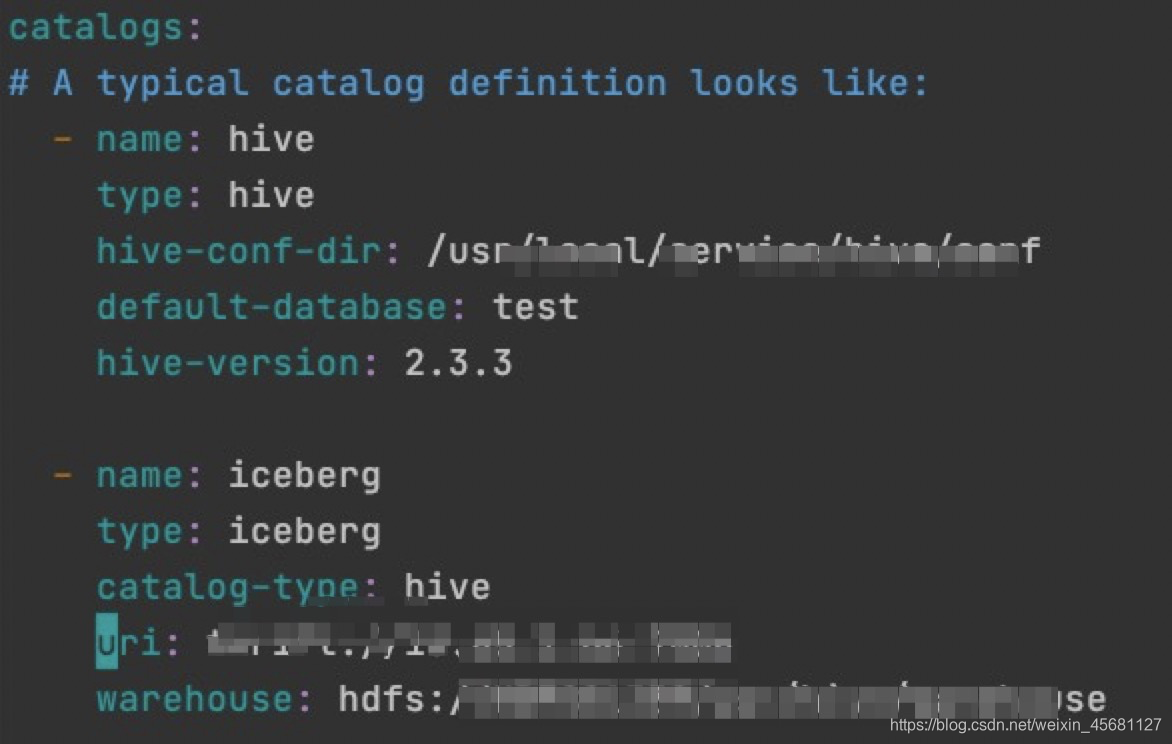
3、创建catalog(建议方法1)
方法1:
修改配置文件sql-client-defaults.yaml
新增catalog
- name: iceberg
type: iceberg
catalog-type: hive
uri: thrift://IP:port
warehouse: hdfs://xxxx/xxxx/xx
方法2:
进入Flink-sql后手动创建连接(临时)
CREATE CATALOG zdmf WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://10.45.1.66:7004',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://HDFS81339/usr/hive/warehouse'
);
4、启动
./bin/sql-client.sh embedded \
-j /data/software/flink/flink-1.11.0/lib/iceberg-flink-runtime-0.11.0.jar \
shell
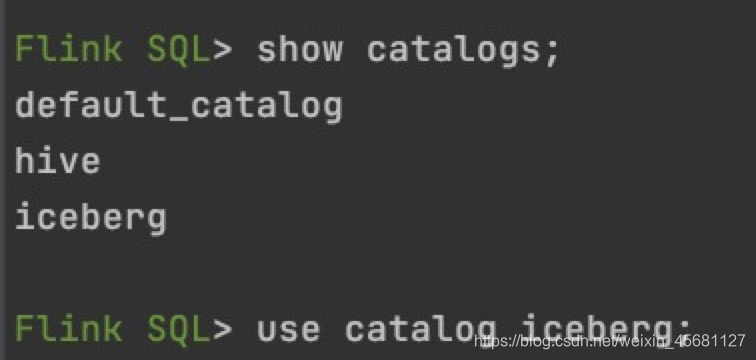
进入catalog:
use catalog iceberg;
二、Flink-SQL
不支持: 创建带水位线的表
不支持:创建带有隐藏分区的 iceberg 表
不支持:在 flink 流模式下读iceberg表
建表:
CREATE TABLE iceberg.test.iceberg_flink (id int ,name string);
更改写入格式:
ALTER TABLE iceberg.test.iceberg_flink SET ('write.format.default'='avro')
改名:
ALTER TABLE iceberg.test.iceberg_flink RENAME TO iceberg.test.iceberg_flink1;
删除表:
DROP TABLE iceberg.test.iceberg_flink1;
插入(仅支持into,不支持overwrite):
insert into iceberg.test.iceberg_flink values(1,'a');
不支持新增列:
alter table iceberg_flink1 add columns flag int;

重写:不支持insert overwrite ,流模式下提示不支持,批模式下直接程序异常。
insert overwrite iceberg_flink1 values(6,'f');

删除:
delete from iceberg_flink1 where id=2;

更新:
update iceberg_flink1 set name='xx' where id=2;

三、Flink-Streaming:
我主要是写Spark比较多,Flink太少,所以测试有点困难。后期如果有时间,我会补充的。
| 组件 | 版本 |
|---|---|
| sbt | 1.4.2 |
| scala | 2.12.10 |
| Spark | 1.11.0 |
| iceberg | 0.11.0 |
build.sbt文件
name := "Iceberg_smzdm"
version := "0.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.flink" %% "flink-streaming-scala" % "1.11.0"
libraryDependencies += "org.apache.flink" %% "flink-scala" % "1.11.0"
libraryDependencies += "org.apache.flink" %% "flink-clients" % "1.11.0"
libraryDependencies += "org.apache.flink" %% "flink-connector-hive" % "1.11.0"
libraryDependencies += "org.apache.flink" %% "flink-table-planner" % "1.11.0"
查询
val senv = StreamExecutionEnvironment.getExecutionEnvironment
val sss = StreamTableEnvironment.create(senv)
val env = ExecutionEnvironment.getExecutionEnvironment
val tenv = BatchTableEnvironment.create(env)
val createCatalog = "CREATE CATALOG zdmflink WITH ('type'='iceberg', 'catalog-type'='hive', 'uri'='thrift://10.45.1.66:7004','clients'='5','property-version'='1','warehouse'='hdfs://HDFS81339/usr/hive/warehouse')"
sss.executeSql(createCatalog)
//API创建
tenv.registerCatalog("iceberg", HiveCatalog)
sss.useCatalog("zdmflink")
sss.useDatabase("test")
sss.executeSql("select * from zdmflink.test.iceberg_flink").print()

















 4305
4305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









