







设备:RTX4080
运行环境:Python=3.8(要求>=3.8),torch1.12.0+cu113(要求>=1.8)
问题:ultralytics代码绘制中文标签乱码,以及其他网上中文绘制推理脚本进行中文可视化时,绘制时间较长(甚至远大于推理时间),尤其目标数量100+时,可视化时间可能上百毫秒,对要求实时推理需求很不友好。
本文方法:CPU/GPU上中文绘制耗时几乎忽略不计,接口代码可以集成到其他推理脚本中!
注意1:下面代码可视化有些框没有标签是因为代码进行超出边界过滤,需自行去优化修改!
注意2:自行去测试时,注意参数修改!
1 绘制较慢的原因分析
常用的方法和很多博主都是对框一个个遍历,并从opencv转Image格式进行中文绘制,这种绘制速度极慢!!!
例子如下:
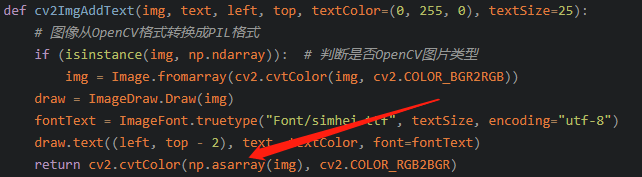
其中,图像格式转换开销占主要:
PIL 与 OpenCV 格式转换:代码中使用了 PIL 库来创建字符图像,然后再将其转换为 OpenCV 能处理的 numpy 数组格式。这个转换过程涉及到颜色通道顺序的调整(从 RGBA 到 BGR)以及数据类型的转换,会消耗一定的时间。特别是在处理大量字符图像时,这种转换的累积开销会变得明显。
char_img_cv = cv2.cvtColor(np.array(char_img), cv2.COLOR_RGBA2BGR)
2 本文中文标签绘制思路
本文中文绘制方法简言之就是 贴图,先利用PIL库创建好所有中文标签并转换Opencv格式生成缓存,然后绘制时只需要拿出来贴在原图上,测试结果绘制100个中文标签耗时几乎忽略不计,具体如下:
2.1 主要实现流程
该代码绘制中文标签的流程主要分为初始化、缓存创建、绘制三个主要阶段,以下是详细步骤:
2.1.1 初始化阶段
类实例化:在主程序中创建 Draw_Chinese_text 类的实例,在实例化时会传入字体大小、字体文件路径等参数。
字体与颜色设置:在 Draw_Chinese_text 类的 init 方法中,根据传入的字体文件路径使用 ImageFont.truetype 加载字体,同时设置文本颜色。
2.1.2 缓存创建阶段
初始化缓存:实例化 Draw_Chinese_text 类时会调用 draw_cached_text_init 方法,该方法会遍历传入的 cached_char_images_dict 字典。
创建字符图像:对于字典中的每个文本标签,创建一个透明的 PIL 图像,使用 ImageDraw 在图像上绘制文本,然后将其转换为 OpenCV 格式的 numpy 数组,并保存到缓存字典中。
2.1.3 绘制阶段
检查缓存:在 draw_txt 方法中,当需要绘制文本时,首先检查该文本是否已经存在于缓存字典中。
处理新文本:如果文本不在缓存中,创建新的字符图像,将其转换为 OpenCV 格式,并保存到缓存字典中。
绘制文本:从缓存中获取对应的字符图像,检查其在目标图像上的绘制位置是否越界,如果不越界,则将字符图像覆盖到目标图像的对应位置。
2.1.4 流程总结
整个绘制中文标签的流程通过初始化字体和颜色、创建并管理字符图像缓存,最终将缓存的字符图像高效地绘制到目标图像上,利用缓存机制减少了重复绘制和字体渲染的开销,提高了绘制效率。
3 实战测试
本文将利用Visdrone2019数据集和模型进行测试。
中文字体为:HarmonyOS_Sans_SC_Regular.ttf【华为定制鸿蒙字体,网上免费下载】
3.1 创建脚本Draw_Chinese_text.py,内容如下:
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
class Draw_Chinese_text():
def __init__(self, textSize, thickness, font_path, cached_char_images_dict={'行人':{'text_lenght': 2, 'cache_img': None}}):
# 指定字体文件路径(注意,这里后续使用cv2时需要确保能正确加载字体,可能和PIL加载方式有区别)
self.font_path = font_path
self.font = ImageFont.truetype(self.font_path, textSize)
# 指定文本颜色(白色示例,可按需修改,opencv中颜色顺序为BGR)
self.fill = (255, 255, 255)
self.thickness = thickness
self.textSize = textSize + self.thickness
self.cached_char_images_dict = cached_char_images_dict
self.draw_cached_text_init()
def draw_cached_text_init(self):
"""
使用缓存机制初始化绘制文本相关内容-使用PIL来创建字符图像缓存-并转成cv2格式
"""
for txt_key in self.cached_char_images_dict:
txt_len = self.cached_char_images_dict[txt_key]['text_lenght']
# 创建一个临时的透明图像用于绘制单个字符
char_img = Image.new("RGBA", (self.textSize * int(txt_len), self.textSize), (255, 0, 0, 0))
char_draw = ImageDraw.Draw(char_img)
char_draw.text((self.thickness // 2, self.thickness // 2), txt_key, font=self.font, fill=self.fill)
# 将PIL图像转换为OpenCV能处理的numpy数组格式(注意颜色通道顺序转换等)
char_img_cv = cv2.cvtColor(np.array(char_img), cv2.COLOR_RGBA2BGR)
self.cached_char_images_dict[txt_key]['cache_img'] = char_img_cv
def draw_txt(self, img_cv, point, label):
"""
在目标图像上绘制文本-将缓存的字符图像绘制到传入的opencv图像上
:param img_cv: 目标图像, opencv的numpy数组格式表示
:param point: 绘制文本的起始坐标,格式为 (x, y)
:param label: 要绘制的文本标签
"""
# 显示的标签不在默认字典,则创建新键值
if label not in self.cached_char_images_dict:
self.cached_char_images_dict[label] = {}
txt_len = len(label)
# 创建一个临时的透明图像用于绘制单个字符
char_img = Image.new("RGBA", (self.textSize * int(txt_len), self.textSize), (255, 0, 0, 0))
char_draw = ImageDraw.Draw(char_img)
char_draw.text((self.thickness // 2, self.thickness // 2), label, font=self.font, fill=self.fill)
# 将PIL图像转换为OpenCV能处理的numpy数组格式(注意颜色通道顺序转换等)
char_img_cv = cv2.cvtColor(np.array(char_img), cv2.COLOR_RGBA2BGR)
# 将新显示的值保存起来
self.cached_char_images_dict[label]['cache_img'] = char_img_cv
self.cached_char_images_dict[label]['text_lenght'] = txt_len
char_np_img = self.cached_char_images_dict[label]['cache_img']
h, w, _ = char_np_img.shape
x, y = point
# 判断标签是否越界,如果越界进行相应处理(这里简单示例,可以根据实际情况完善逻辑)
if x < 0 or y < 0 or x + w > img_cv.shape[1] or y + h > img_cv.shape[0]:
return img_cv
# 将缓存的字符图像覆盖到目标图像对应位置上(这里简单的覆盖,可根据需求考虑更复杂的融合等操作)
img_cv[y:y + h, x:x + w] = char_np_img
return img_cv
3.2 创建测试脚本
from ultralytics import YOLO
import os
import cv2
import argparse
import time
from Draw_Chinese_text import Draw_Chinese_text
class YOLOv8(object):
def __init__(self, args):
self.args = args
# 加载模型
self.model = YOLO(model=self.args.model_path)
# 初始化绘制中文文本的类
self.draw_txt = Draw_Chinese_text(args.textSize, args.thickness, args.font_path, args.cached_char_images_dict)
def __call__(self, img_path):
# 读取图片
frame = cv2.imread(img_path)
self.results = self.model(source=frame, imgsz=self.args.imgz, save=False, conf=self.args.conf_thres, iou=self.args.iou_thres)
# 绘制结果
self.visualize(self.args, frame)
cv2.imwrite(os.path.join(args.out_path, os.path.basename(img_path)), frame)
def visualize(self, args, frame):
# 绘制结果
# Visualize the results on the frame
tmp_data = self.results[0].boxes.data.cpu().numpy()
start_time = time.time()
t2 = 0
for obj in tmp_data:
x1, y1, x2, y2, conf0, cls = obj
x1, y1, x2, y2, cls = int(x1), int(y1), int(x2), int(y2), int(cls)
text = args.classes[cls]
if text not in args.vis_classes:
continue
position = x1, y1 - args.textSize - args.thickness
t3 = time.time()
self.draw_txt.draw_txt(frame, position, text)
t2 += (time.time() - t3)
# print('绘制中文时间:{}s'.format(time.time() - t3))
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 0, 255), args.thickness)
print('总绘制中文时间:{}s'.format(t2))
print('总绘制时间:{}s'.format(time.time() - start_time))
if __name__ == '__main__':
# 命令行参数
parser = argparse.ArgumentParser(description="gdu ai test")
parser.add_argument("--model_path", type=str, default=r"E:\Code\YOLO-Chinese\visdrone_8\weights/best.pt", help="模型路径")
parser.add_argument("--img_dir", type=str, default=r"E:\datasets\visdrone_mini\VisDrone2019-DET-train\images", help="输入路径")
parser.add_argument("--out_path", type=str, default=r"E:\Code\YOLO-Chinese\res", help="保存路径")
# 类别与模型参数设置,下面采用visdrone数据集类别名称为:['pedestrian', 'people', 'bicycle', 'car', 'van', 'truck', 'tricycle', 'awning-tricycle', 'bus', 'motor']
parser.add_argument("--classes", default=['行人', '人', '自行车', '汽车', '面包车', '卡车', '三轮车', '遮阳三轮车', '巴士', '摩托车'], type=list, help="模型中文类别名称")
parser.add_argument("--vis_classes", default=['行人', '人', '自行车', '汽车', '面包车', '卡车', '三轮车', '遮阳三轮车', '巴士', '摩托车'], type=list, help="需要显示的类别名称")
parser.add_argument("--imgz", default=[640, 640], type=list, help="模型推理输入尺寸")
parser.add_argument("--conf_thres", default=0.25, type=float, help="目标置信度阈值")
parser.add_argument("--iou_thres", default=0.6, type=float, help="目标之间iou阈值")
# 画框设置
parser.add_argument("--cached_char_images_dict",
default={ '行人':{'text_lenght': 2, 'cache_img': None},
'人':{'text_lenght': 1, 'cache_img': None},
'自行车':{'text_lenght': 3, 'cache_img': None},
'汽车':{'text_lenght': 2, 'cache_img': None},
'面包车':{'text_lenght': 3, 'cache_img': None},
'卡车':{'text_lenght': 2, 'cache_img': None},
'三轮车':{'text_lenght': 3, 'cache_img': None},
'遮阳三轮车':{'text_lenght': 5, 'cache_img': None},
'巴士':{'text_lenght': 2, 'cache_img': None},
'摩托车':{'text_lenght': 3, 'cache_img': None}
},
type=dict, help="中文标签显示设置, 长度与字数对应")
parser.add_argument("--font_path", default=r"E:\Code\YOLO-Chinese\HarmonyOS_Sans_SC_Regular.ttf", type=str, help="字体路径, 默认鸿蒙字体")
parser.add_argument("--text_fill", default=True, type=bool, help="字体是否填充底纹,默认填充为红色")
parser.add_argument("--textSize", default=20, type=int, help="字体大小")
parser.add_argument("--textColor", default=(255, 255, 255), help="字体颜色RGB")
parser.add_argument("--thickness", default=2, type=int, help="框的线厚度")
parser.add_argument("--device", default='0', type=str, help="在哪张卡上推理")
args = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = args.device
# run
demo_yolo = YOLOv8(args)
for img_path in os.listdir(args.img_dir):
demo_yolo(os.path.join(args.img_dir, img_path))
3.3 耗时分析
耗时:几乎忽略不计,效果优于其他方法。
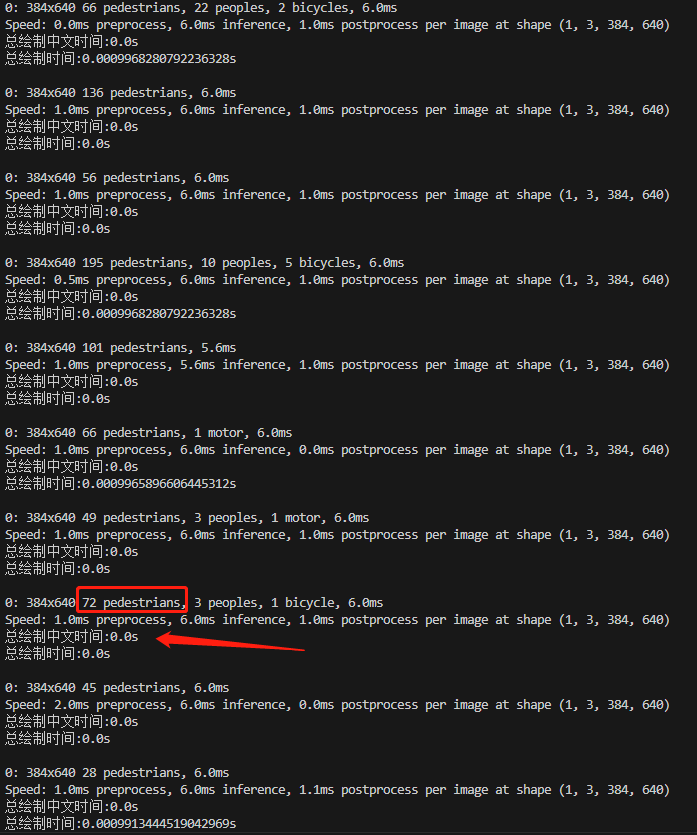
3.4 结果可视化




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









