



问题描述:
使用的是8张910的服务器,在NPU之间使用hccl通信,在过程中需要1个npu向别的Npu发送一些tensor(暂时先不管模型训练那些),这样的过程如何用python程序表示,并行启动方式应该选择msrun还是ranktable启动呢?
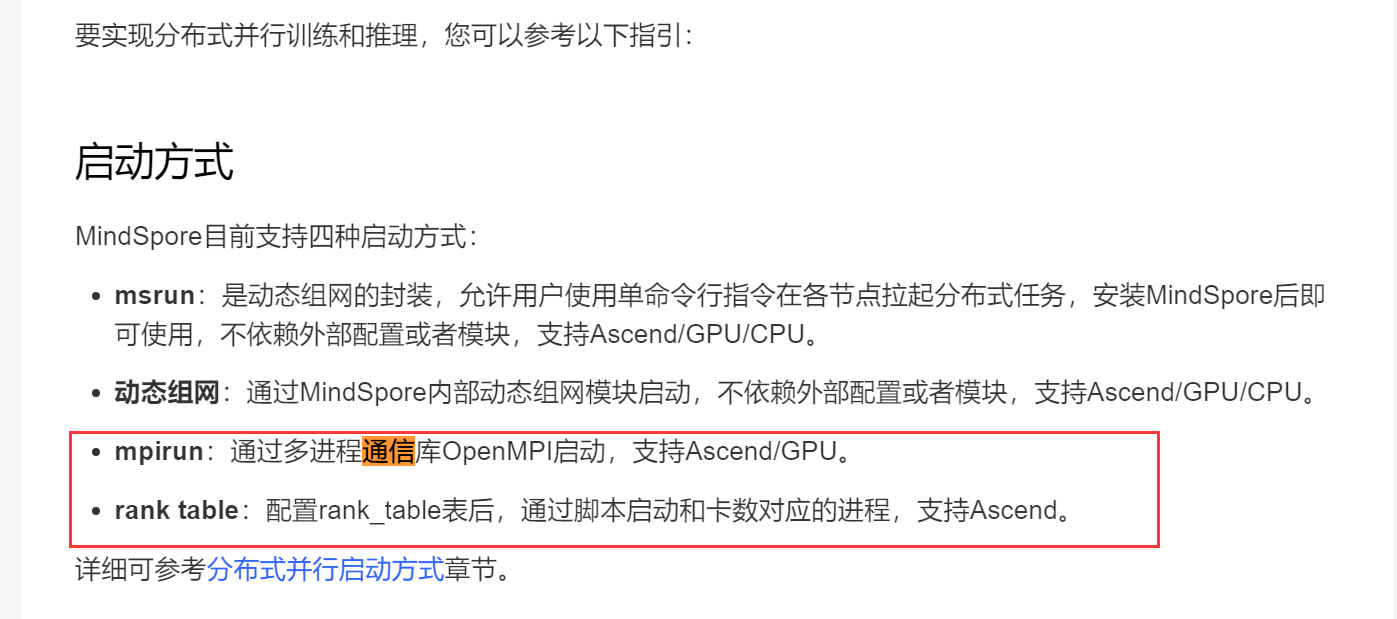
解决方法:
hccl的通信都是封装在框架里调用了,实际并行训练的过程中,python层面是感知不到的,代码中配置对应的并行模式后,自动使用hccl传输,可以参考下mindformer等大模型套件下的并行训练配置;msrun和ranktable启动都可以的,以前的版本在昇腾环境基本都用ranktable,现在官方是推荐使用msrun启动,昇腾和GPU都支持,工具内部会根据硬件环境自动调用昇腾的hccl或者GPU的nccl,可以参考官网并行文档:
https://www.mindspore.cn/tutorials/experts/zh-CN/r2.3.1/parallel/overview.html
如果你偏向于使用手动实现并行逻辑,也可以参考手动并行文档:
https://www.mindspore.cn/tutorials/experts/zh-CN/r2.3.1/parallel/manual_parallel.html


















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









