







1、执行过程
1、读入外部的数据源(或者内存中的集合)进行 RDD 创建;
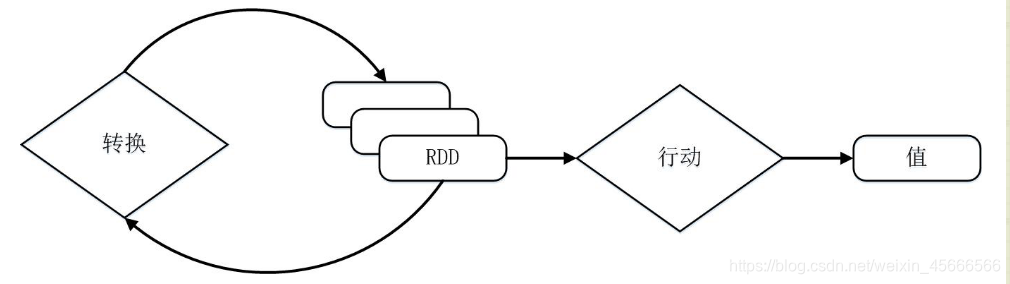
2、RDD 经过一系列的 “转换” 操作,每一次都会产生不同的 RDD,供给下一个转换使用;
3、最后一个 RDD 经过 “行动” 操作进行处理,并输出指定的数据类型和值。
优点: 惰性调用、管道化、不需要保存中间结果。
- RDD 采用了惰性调用,即在 RDD 的执行过程中,所有的转换操作都不会执行真正的操作,只会记录依赖关系,而只有遇到了行动操作,才会触发真正的计算,并根据之前的依赖关系得到最终的结果。
RDD执行过程中的一个示例如下:
\quad \quad 如下图所示,在输入中逻辑上生成A和C两个RDD, 经过一系列"转换操作", 逻辑上生成"F"这个RDD, 之所以说是逻辑上, 是因为这个时候计算并没有发生. Spark只是记录了RDD之间的依赖关系. 当F要进行输出时, 就会执行"行动操作". Spark才会根据RDD的依赖关系生成DAG, 并从起点开始真正的计算.
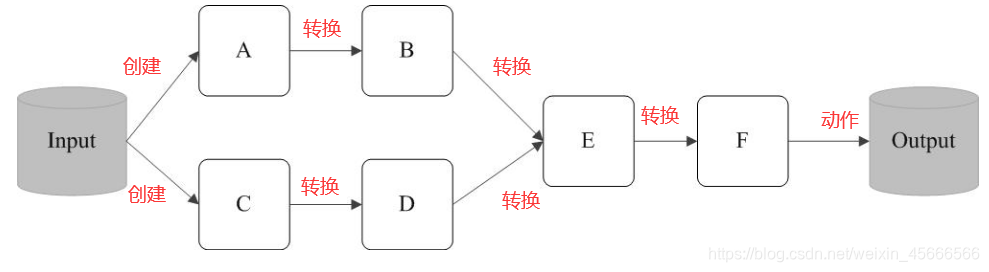
- 转换操作,并不会发生真正的计算,只是记录转换的轨迹
- 动作操作,才会触发从头到尾的真正的计算,并得到结果
2、编程模型
\quad \quad 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。 在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
\quad \quad
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









