






 本文详细介绍了NLP项目的主流程,包括分词技术、语言模型的构建与评估,以及文本处理技术如拼写纠错、单词过滤和同义词替换。深入探讨了分词算法的优缺点,并讲解了如何通过语言模型提升分词准确性。
本文详细介绍了NLP项目的主流程,包括分词技术、语言模型的构建与评估,以及文本处理技术如拼写纠错、单词过滤和同义词替换。深入探讨了分词算法的优缺点,并讲解了如何通过语言模型提升分词准确性。
NLP项目主要流程
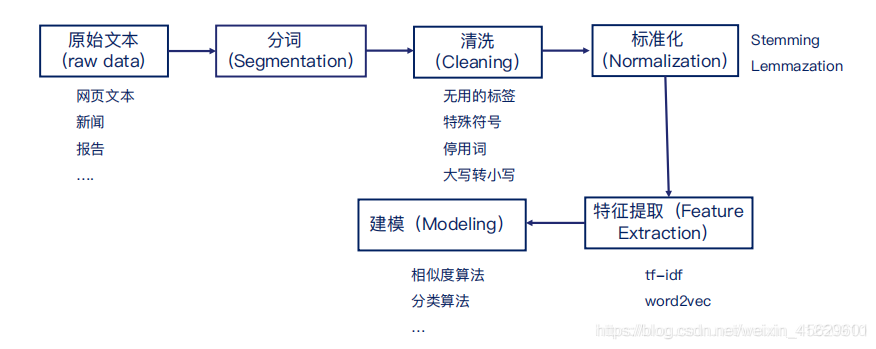
1.分词(Word Segmentation)
1.1 分词依靠词库
常用开源分词工具:jieba, SnowNLP, LTP, HanNLP
jieba分词库学习链接:jieba学习文档
1.2 分词算法:
1.2.1 基于匹配规则的匹配:最大匹配(forward max-matching/background max-matching/双向最大匹配):最大匹配算法
缺点:
1.陷入局部最优 ;
2.未考虑语义,可产生歧义,可在语义层面上优化;
3.效率依赖于window_size。
1.2.2 基于概率统计的方法:考虑语义
假设如下:获取所有的分词结果,利用“黑盒”为我们判断分词结果的语义概率(这句话是人话,是正常语句的可能性),从中选取概率最大的作为分词结果。
步骤:1.找出所有分词的可能结果,2.找到最大语义的分词结果
针对两步效率低的改进算法,利用维特比算法,依托于动态规划进行合二为一,
可看这篇博客:分词算法及优化方法
上面所用的“黑盒”就是语言模型(Language Model)。
语言模型(Language Model):
语言模型就是用来判断一句话是正常语句的概率。
Nosiy Channel Model: P(text|source) ∝ P(source|text)×P(text)
常见语言模型有: Unigram,Bigram,Trigram,N-gram, 利用马尔科夫模型来进行chain rule法则计算句子的概率。
语言模型的评估方式:
【任务内评估】评估语言模型:理想情况下:可以把特定的任务应用到两个语言模型中,看效果哪个好。
【任务外评估】不依赖任何任务进行评估:预测下一个词是什么,类似于做填空题,可以选择出后面最好的预测
Perplexity = 2^(-x) x:average log likelihood
好的语言模型,放到语料库里后,log likelihood越大越好,Preplexity越小越好

对于text【语料库】没有出现的单词,不代表以后不会出现,用N-gram的方式算出的概率均为0,需要添加平滑项[这个方法在朴素贝叶斯算法中也会用到]
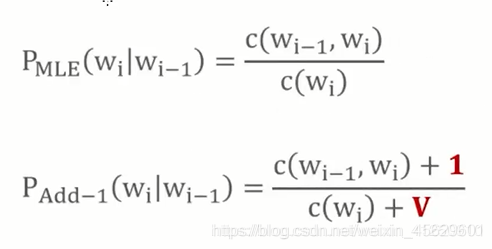
Add-K Smothing
Interpolation
Good-turing Smothing
Good-turning Smothing 的缺点及改进: 计算出现c次的概率时需要c+1次出现的概率,如果c+1次不存在,会导致概率为0,因此,可以采用数值分析中的插值方法来补齐缺失值。
语言模型也是一个生成模型
生成模型:简单的可以理解为可以生成新的数据的模型,数据可能是:图片,音乐,文本等,
Unigram:生成单词,生成概率就是每个单词出现在语料库中的概率,生成的语句很大概率上没有考虑上下文而不符合语义。
Bigram:生成单词,会产生一个二维矩阵,表示出现某个词后,后面单词出现的概率。
文本处理技术
- 拼写纠错
- 单词过滤
- 同义词替换(标准化)
拼写纠错
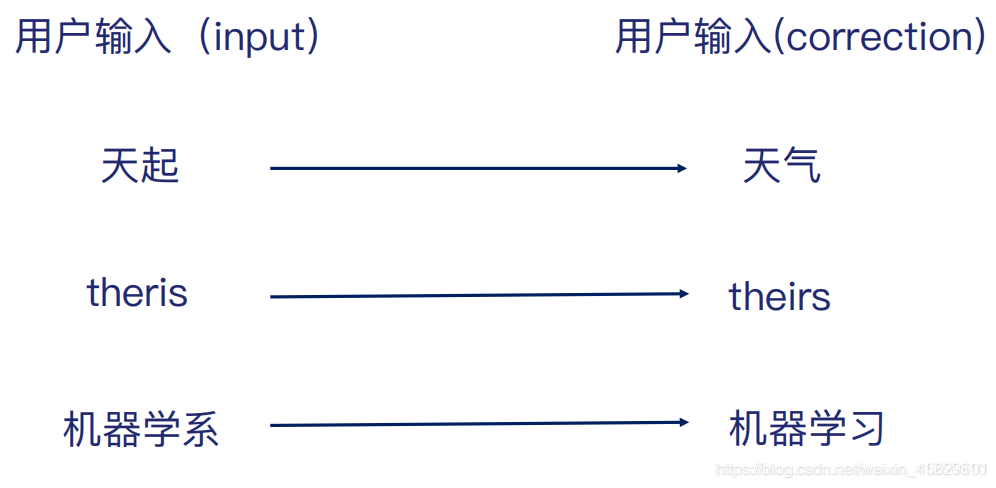
定义编辑距离为:<w1,w2>之间的最少单字符操作次数:
1.插入(insertion) 2.删除(deletion) 3.替换(replace)
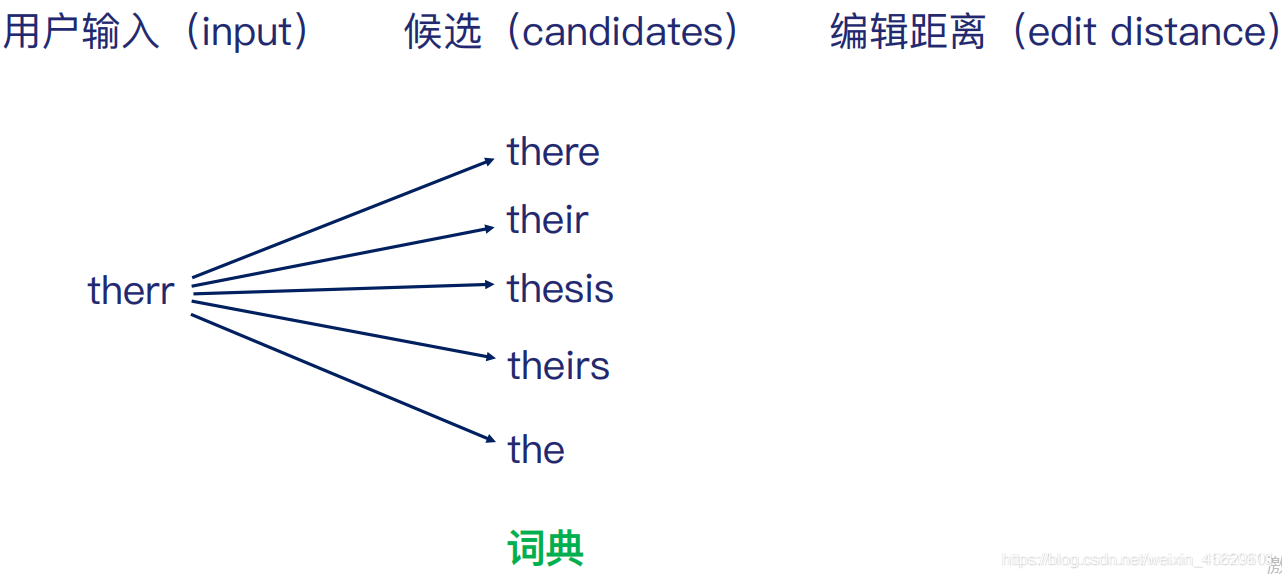
therr的编辑距离为:1,1,3,2,2
基于动态规划的编辑距离算法
def edit_dist(str1,str2):
#m,n分别为字符串str1,str2的长度
m,n = len(str1), len(str2)
#构建二维数组来储存子问题(sub-problem)的答案
dp = [[0 for i in range(n+1)] for j in range(m+1)]
#利用动态规划来求解
for i in range(m+1):
for j in range(n+1):
#设定边界值,
if i == 0:
dp[i][j] = j #第一行为0,1,2,...,n【采用insert编辑选项】
elif j==0:
dp[i][j] = i #第一列为0,1,2,...,m【采用insert编辑选项】
#状态转移方程
#当前子串租后一个字符相同
elif str1[i-1] = str2[j-1]:
dp[i][j] = dp[i-1][j-1]
#当前子串最后一个字符不相同
else:
dp[i][j] = 1 + min(dp[i][j-1],dp[i-1][j],dp[i-1][j-1]) # insert/remove/replace
return dp[m][n]
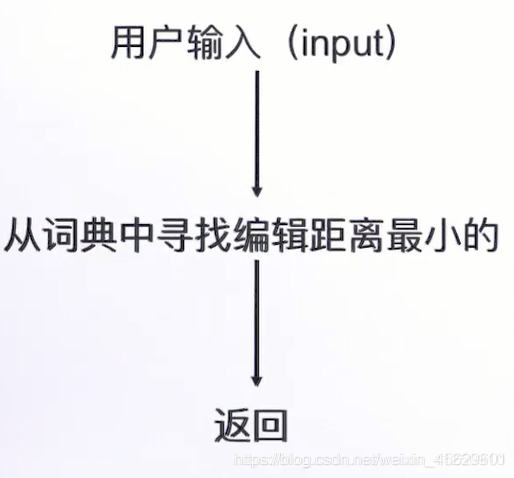
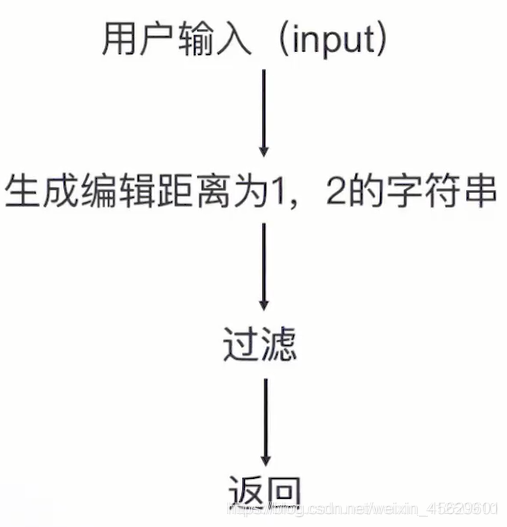
缺点及优化方法:寻找编辑距离最小的单词,如果采用遍历算法,计算错词与词典中单词的编辑距离从而寻找最小值,词典的单词数通常是亿级别,显然不符合实时性要求。采用以下算法将降低筛数,从而降低时间复杂度。
单词过滤
将停用词(stop-words) 及 出现频率很低的词过滤掉,类似于特征筛选。
同义词替换
英文的过去式,一般式,进行式的标准化: went–go–going == go
常用技术有Stemming 和 Lemmazation: 基于一些规则来变换

Porter Stemming 算法: 波特比算法
文本的表示
单词的表示
- One-hot Representition:稀疏度高,维度高
- Distributed count vecotr :可以衡量单词间语义相似度,还可以进行可视化分析,使用深度学习模型(Skip-Gram,Glone Cbow,RNN/LSTM)来训练
句子的表示
- bollen vector
- count vector
- Tf-idf Representation

基于词向量表达句子
- 平均法则 2.LSTM/RNN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









