






最近在做一些慢SQL的治理、优化,发现了一个大家可能都会忽略的问题,今天就分享给大家。
MySQL查询慢,很多程序员第一印象,加索引。除了索引之外,是否还有其它的原因,导致SQL查询过慢,答案是,当然有。
MySQL的底层执行原理
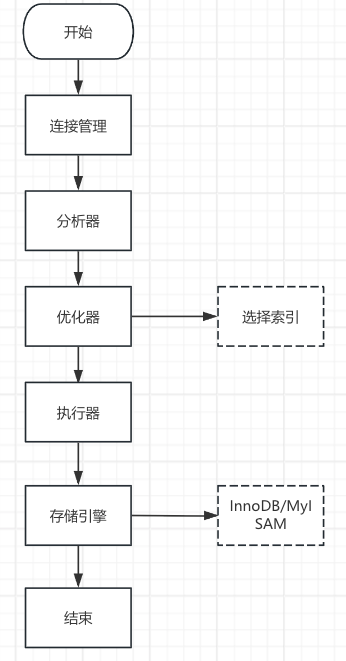
mysql的查询步骤分为以下几个部分。
- 连接管理
管理数据库的连接,MySQL 5.7版本默认的最大连接数是151,上限是16384。
客户端基本上都是用数据库连接池,最常用的是druid。 - 分析器
检查SQL有没有语法错误。 - 优化器
用来选择索引类型 - 执行器
调用存储引擎执行SQL。 - 存储引擎
负责数据的CRUD,常用的存储引擎是InnoDB。
具体流程图如下所示。
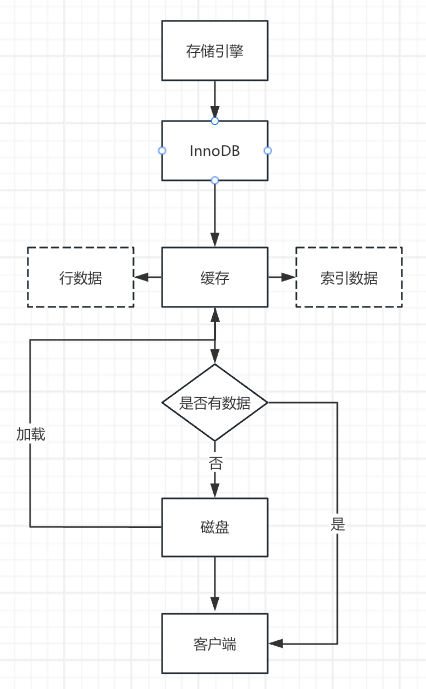
存储引擎内部有一个缓存区(buffer bool),用来存储索引数据和行数据。
存储引擎每次执行SQL的时候,会根据优化器选择的索引,去缓存区查索引数据,没有的话,会从磁盘中加载在缓存区,然后带着索引去缓存区找行数据,找不到的话,同样会从磁盘加载,最后将执行结果返给客户端。
具体流程如下图所示。
了解了mysql的底层执行原理,我们再来看这个问题。
影响查询性能的因素有三个,一个是连接管理,另外一个是优化器,最后一个是存储引擎。
对于连接管理,MySQL的5.7版本最大连接数默认是151, 而客户端现如今都是使用数据库连接池。
使用以下命令即可更改数据库默认的最大连接数。
set global max_connections = 200;
数据库的最大连接数量修改之后,如果查询速度还是没有提升,那么可以检查下数据库连接池的最大连接数。
优化器就不用细说了,用explain命令,就可以看到SQL的具体执行情况。
最佳实践可见:
最后一个是存储引擎,这里影响查询性能的就是缓存区的大小了。
执行以下命令即可调整。
# 查询缓存的命中率
show status like Innodb_buffer_pool_%
# 更改缓存的大小
set global innodb_buffer_pool_size = 16777216



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











