







极端值处理
KNN 决策树 对极端值不敏感
可视化检验
例如:信用卡额度过高,持卡人年龄过大
缺失值处理
完全随机
随机
完全非随机
提升算法
伪残差,拟合残差
正则项
决策树的复杂度可考虑叶节点数和叶权值
超参数
GBDT
GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。这就是Gradient Boosting在GBDT中的意义,
GBDT可以用更少的feature,且避免过拟合。Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错instance的权重,而已经分对的instance则都趋向于0。这样后面的树就能越来越专注那些前面被分错的instance。就像我们做互联网,总是先解决60%用户的需求凑合着,再解决35%用户的需求,最后才关注那5%人的需求,这样就能逐渐把产品做好。
通过最小化损失函数求解最优模型:
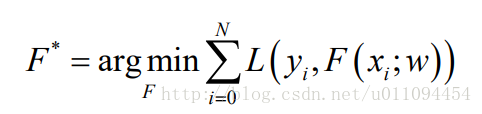
XGBoost
1.Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。
2.传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
3.传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
4.xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和
5.列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
xgboost工具支持并行。
加入正则项
正则项对每棵回归树的复杂度进行了惩罚,而复杂度可以用树的深度,内部节点个数,叶子节点个数(T),叶节点分数(w)等来衡量。
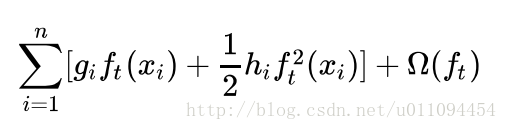
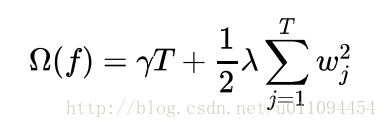
打分函数:
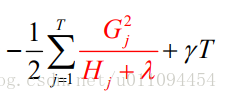
Adaboost:
根据分类误差率得到权值
更新权值分布
误差率小的权值大
前向分布算法
Adaboost是另一种boost方法,它按分类对错,分配不同的weight,计算cost function时使用这些weight,从而让“错分的样本权重越来越大,使它们更被重视”。Bootstrap也有类似思想,它在每一步迭代时不改变模型本身,也不计算残差,而是从N个instance训练集中按一定概率重新抽取N个instance出来(单个instance可以被重复sample),对着这N个新的instance再训练一轮。由于数据集变了迭代模型训练结果也不一样,而一个instance被前面分错的越厉害,它的概率就被设的越高,这样就能同样达到逐步关注被分错的instance,逐步完善的效果。Adaboost的方法被实践证明是一种很好的防止过拟合的方法,但至于为什么则至今没从理论上被证明。
summary
Bagging减少训练方差;
Boosting减少偏差;

















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









