






目录
正则表达式概念
正则表达式是用于匹配字符串中字符组合的模式。在 JavaScript 中,正则表达式也是对象。这些模式被用于 RegExp 的 exec 和 test 方法,以及 String 的 match、matchAll、replace、search 和 split 方法。(就是对字符串的增删改查,根据需求对字符串进行各种各样处理)
如果创建一个正则表达式
字面量的方法创建
- 语法:正则表达式被包含在斜杠之间的模式组成/ /
let reg= /abc/; - 缺点:使用字面量创建正则表达式,有一个缺点。/ /是无法识别变量的。
let str="abc" console.log(/abc/.test(str)) // 输出的是false,因为/str/中的str并不是我们上面定义的str变量的值abc,只是表示字母str。 - 解决方法:要是想要让我们/str/中的str是我们定义的变量的时:可以使用eval函数(eval():函数会将传入的字符串当做 JavaScript 代码进行执行)进行实现。
let str="abc" console.log(eval(`/${str}/`).test('abc')) // true
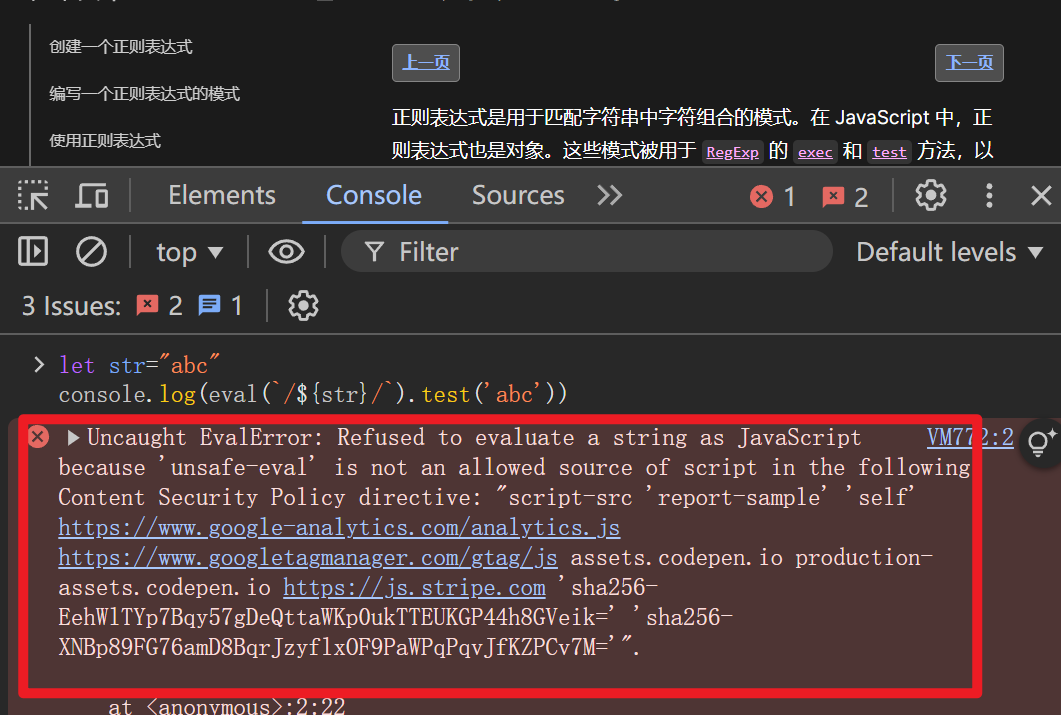
小贴士:
如果你是在使用eval()函数,或者Function()函数,报图片的错误。大概率你是随意打开了一个网页,F12进入了控制台。但是,别人的网站为了安全,不允许字符串来源的脚本。(文章:解读控制台报错文章)换个页面就可以正常了。
使用对象的方法创建
- 语法:new RegExp(正则)注意这里无需使用//
var reg = new RegExp("abc") - 案例:查找输入的内容,把查找到的内容高亮显示
<body> <div>你好,世界</div> </body> <script> let con=prompt("输入您要查询的内容") let reg = new RegExp(con, 'g') let div = document.querySelector('div') console.log(div) div.innerHTML = div.innerHTML.replace(reg, (search) => { return `<span style="color:red">${search}</span>` }) </script>
编写正则表达式的的模式
一个正则表达式模式是由简单的字符所构成的,比如 /abc/;或者是简单和特殊字符的组合,比如 /ab*c/ 或 /Chapter (\d+)\.\d*/。
使用简单模式
- 简单模式是由你想直接找到的字符构成。比如,
/abc/这个模式就能且仅能匹配 "abc" 字符按照顺序同时出现的情况。 - 例如:
- 在 "Hi, do you know your abc's?" 和 "The latest airplane designs evolved from slabcraft." 中会匹配成功。在上述两个例子中,匹配的子字符串是 "abc"
- 在 "Grab crab" 中会匹配失败,因为它虽然包含子字符串 "ab c",但并不是准确的 "abc"
使用特殊字符模式
- 当你需要匹配一个不确定的字符串时,比如寻找一个或多个 "b",或者寻找空格,可以在模式中使用特殊字符。
- 比如,你可以使用
/ab*c/去匹配一个单独的 "a" 后面跟了零个或者多个 "b",同时后面跟着 "c" 的字符串:*的意思是前一项出现零次或者多次。在字符串 "cbbabbbbcdebc" 中,这个模式匹配了子字符串 "abbbbc"
正则表达式特殊字符
字符匹配类
| \d | 匹配一个数字(0到9之前的数字),等价于[0-9]。例如, |
| \D | 匹配一个非数字的字符(除了0-9之外的任意一个字符),等价于[^0-9]。例如, |
| \s | 匹配一个空白字符,包括空格、制表符、换页符和换行符。例如: |
| \S | 匹配一个非空白字符。例如: |
| \w | 匹配一个单字字符(字母、数字或者下划线)。等价于 |
| \W | 匹配一个非单字字符(除了字母、数字或者下划线之外的任意一个字符)。等价于 |
| . | (小数点)默认匹配除换行符之外的任何单个字符。例如, |
小贴士:
- 如果正则表达式中只有字符匹配类的时候,表示匹配的是一个单个字符。
- 比如:/x/:表示匹配x这个单个字符,匹配的是x字符的在字符串中第一次出现的x。
/.n/:表示匹配n前面是除了换行符之外的任何单个字符的值,所以他将会匹配 "nay, an apple is on the tree" 中的 'an' 和 'on',但是不会匹配 'nay'。
位置匹配类
| ^ | 匹配输入的开始。如果多行标志被设置为 true,那么也匹配换行符后紧跟的位置。 例如: 注意:当 ' |
| $ | 匹配输入的结束。如果多行标志被设置为 true,那么也匹配换行符前的位置。 例如: |
| \b | 匹配一个词的边界。一个词的边界就是一个词不被另外一个“字”字符跟随的位置或者前面跟其他“字”字符的位置,例如在字母和空格之间。注意,匹配中不包括匹配的字边界。换句话说,一个匹配的词的边界的内容的长度是 0。(不要和 [\b] 混淆了) 使用"moon"举例: 个人理解:\b前面如果是有字符的话--表示匹配\b前面的字符结尾的值;\b后面如果是有字符的话--表示匹配\b后面的字符结开头的值;当\b前面和后面都有字符的时候,那么就是以这个字符开头并结尾的的字符(就是完全匹配这个字符)。 |
| \B | 匹配一个非单词边界。()匹配如下几种情况:
例如,/\B../匹配"noonday"中的'oo', 而/y\B../匹配"possibly yesterday"中的’yes‘ |
单词边界(\b)和非单词边界(\B):
1. 单词边界要求:必须且仅某一侧出现单词字符,即\w可以匹配的字符

2 .非单词字符边界(\B):要求两侧均为单词字符,它与\b互为补集

3. 示例(关于lastIndex后面再exec的方法中有介绍)
a)\b示例:
let reg=/\bm/g
console.log(reg.exec('moon moonmoon'))
console.log(reg.lastIndex)
console.log(reg.exec('moon moonmoon'))
console.log(reg.lastIndex)
console.log(reg.exec('moon moonmoon'))
console.log(reg.lastIndex) 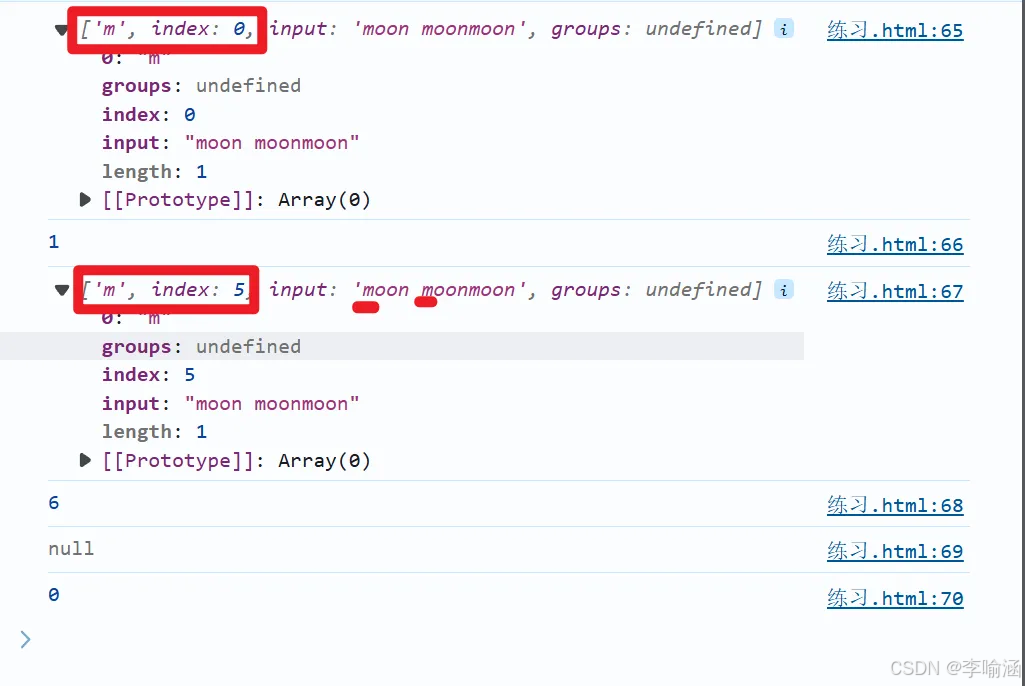
b)\B示例
let reg=/\Bm/g
console.log(reg.exec('moon moonmoon'))
console.log(reg.lastIndex)
console.log(reg.exec('moon moonmoon'))
console.log(reg.lastIndex)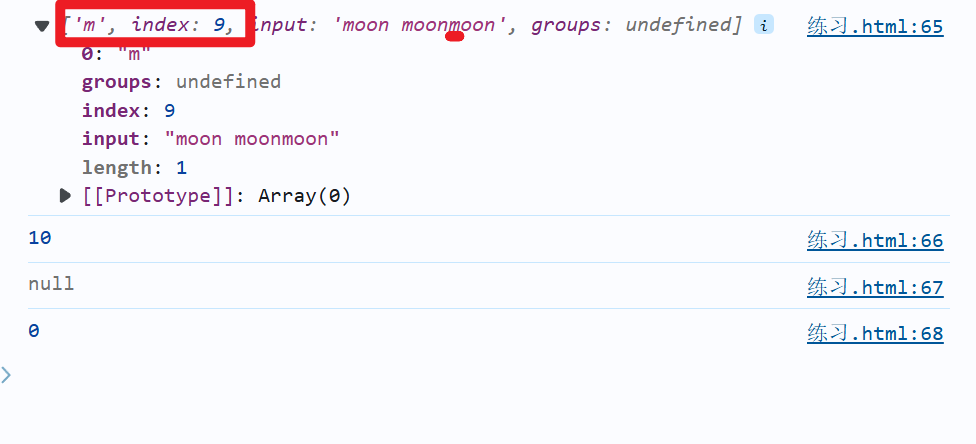
限定符类
| * | 匹配前一个表达式 0 次或多次。等价于 例如, 注意:*号只会影响 |
| + | 匹配前面一个表达式 1 次或者多次。等价于 例如, 注意:+号只会影响 |
| ? | 匹配前面一个表达式 0 次或者 1 次。等价于 例如, 如果?紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 "123abc" 使用 还用于先行断言中,如本表的 |
| {n} | n 是一个正整数,匹配了前面一个字符刚好出现了 n 次。 |
| {n,m} | n 和 m 都是整数。匹配前面的字符至少 n 次,最多 m 次。如果 n 或者 m 的值是 0,这个值被忽略。 例如,/a{1, 3}/ 并不匹配“cndy”中的任意字符,匹配“candy”中的 a,匹配“caandy”中的前两个 a,也匹配“caaaaaaandy”中的前三个 a。注意,当匹配”caaaaaaandy“时,匹配的值是“aaa”,即使原始的字符串中有更多的 a。 |
| {n,} | n 是一个正整数,匹配前一个字符至少出现了 n 次。 例如,/a{2,}/ 匹配 "aa", "aaaa" 和 "aaaaa" 但是不匹配 "a"。 |
贪婪和禁止贪婪
- 贪婪:*、?、+、{n,}……限定符默认都是贪婪的进行匹配的,就是匹配的越多越好(比如:/a+/如果a连续出现了超过10次,那么匹配出了10个a,匹配次数是最大的,这就是贪婪匹配)。
- 禁止贪婪:如果?紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪,匹配尽量少的字符。比如:/a+?/如果a连续出现了超过10次,那么匹配出了1个a,匹配次数是最少的的,这就是禁止贪婪匹配)
+? :匹配1次
*???:匹配0次
{n,}、{n,m}:匹配n次
- 例如
let str='baaaaaaap'
let reg1=/a+/
console.log(str.match(reg1),reg1)
let reg2=/a+?/
console.log(str.match(reg2),reg2)
let reg3=/a*?/
console.log(str.match(reg3),reg3)
let reg4=/a??/
console.log(str.match(reg4),reg4)
let reg5=/a{2,5}?/
console.log(str.match(reg5),reg5)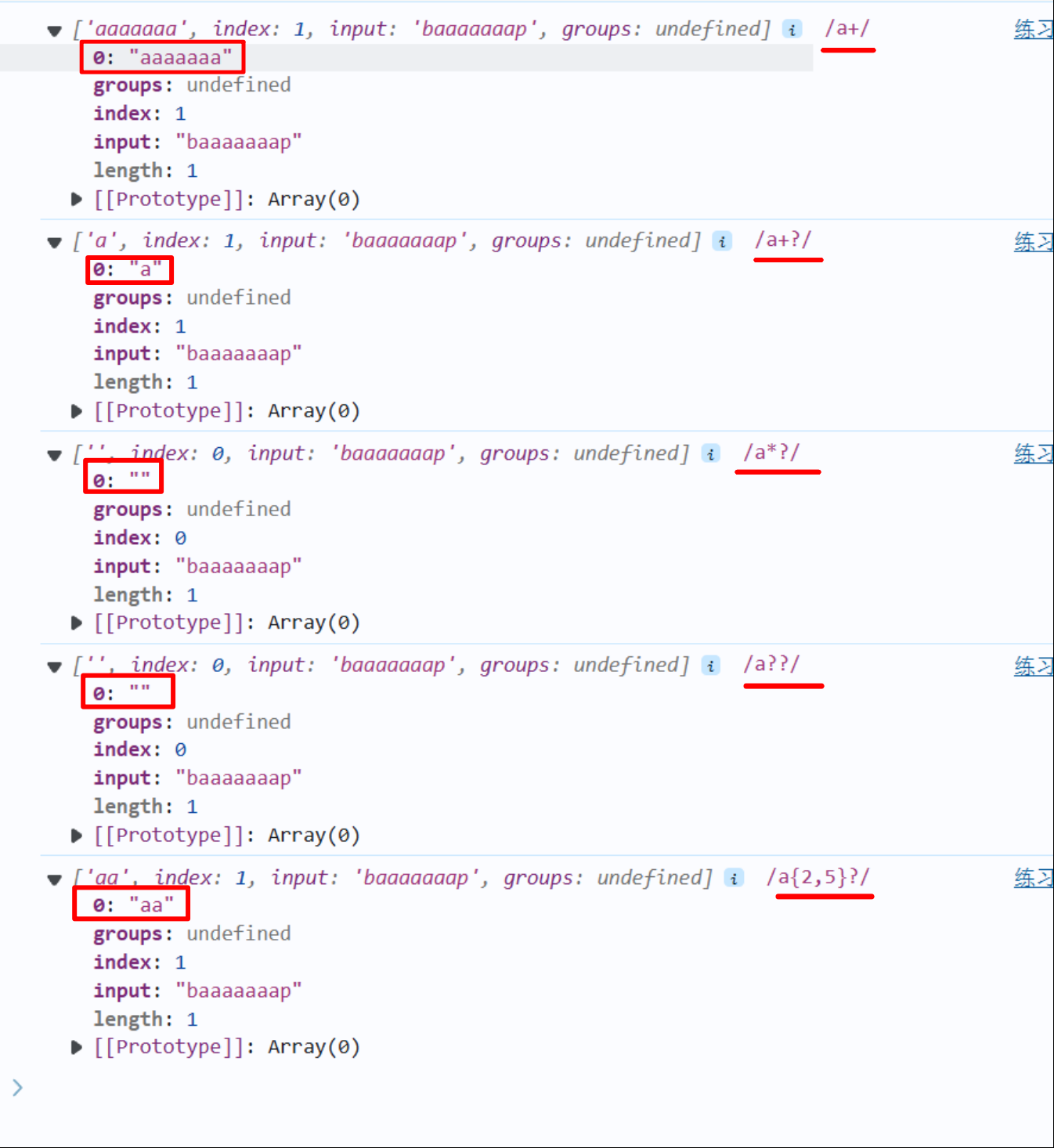
在原子组后的限定符
- *、?、+、{n,}……限定符是一般情况是只影响前面一个字符的,比如:/hd+/:是只影响前面的d出现一次或者是多次
- 如果加上了原子组(),那么就是一个整体。比如:/(hd)+/:hd就是一个整体,+影响前面的hd出现一次或者是多次
- 例如:
let reg=/hd+/
let str1='hhddddddd'
let reg2=/(hd)+/
let str2='hddddddd'
let str3='hdhdhdhdhdhdhd'
let reg3=/(hd){1,3}/
console.log(str1.match(reg))
console.log(str2.match(reg2))
console.log(str3.match(reg3))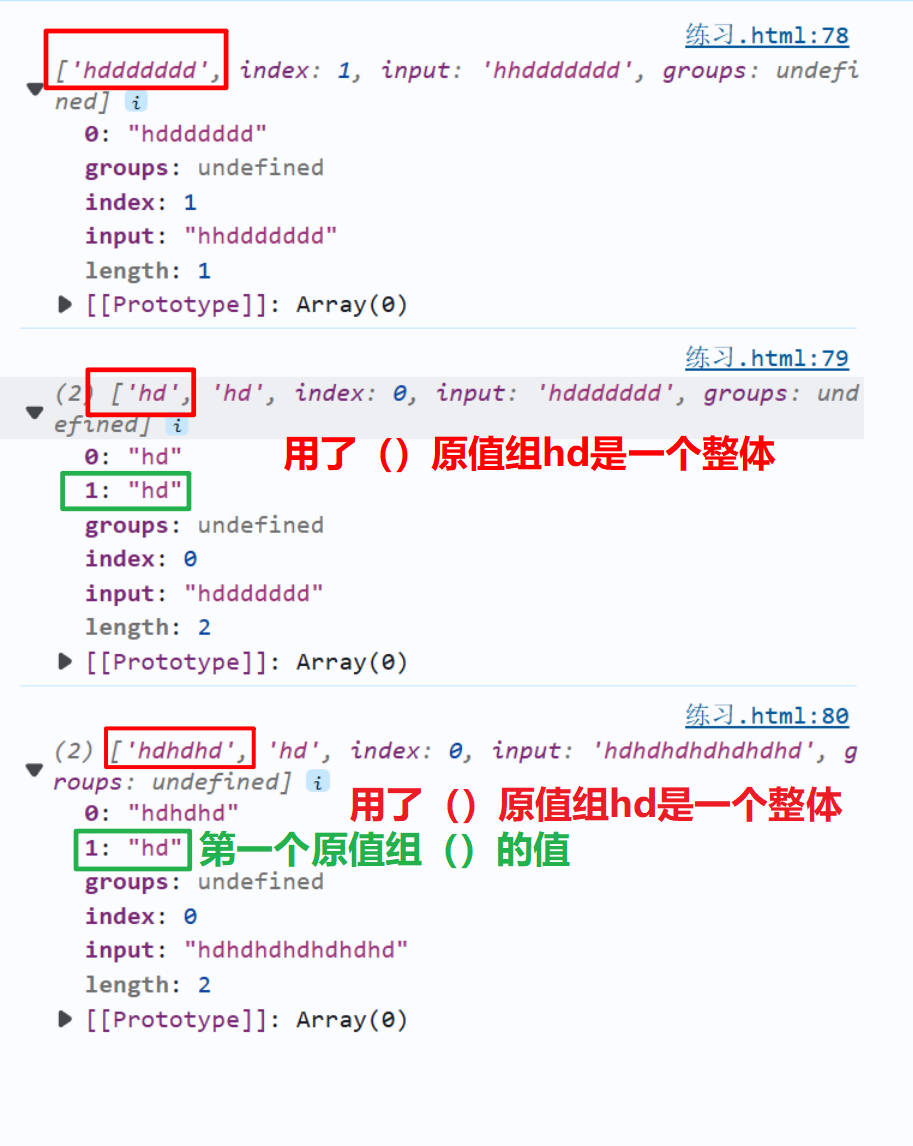
分组类
| x|y | 匹配‘x’或者‘y’。 例如,/green|red/匹配“green apple”中的‘green’和“red apple”中的‘red’ |
| [xyz] | 一个字符集合( [ ])。匹配方括号中的任意字符,包括转义序列。你可以使用破折号(-)来指定一个字符范围。对于点(.)和星号(*)这样的特殊符号在一个字符集中没有特殊的意义。他们不必进行转义,不过转义也是起作用的。 |
| [^xyz] | 一个反向字符集。也就是说, 它匹配任何没有包含在方括号中的字符。你可以使用破折号(-)来指定一个字符范围。任何普通字符在这里都是起作用的。 例如,[^abc] 和 [^a-sc] 是一样的。他们匹配"brisket"中的‘r’,也匹配“chop”中的‘h’。 |
| (x) | 像下面的例子展示的那样,它会匹配 'x' 并且记住匹配项。其中括号被称为捕获括号。 模式 |
| \n | 在正则表达式中,它返回最后的第 n 个子捕获匹配的子字符串 (捕获的数目以左括号计数)。 比如 |
| (?:x) | 匹配 'x' 但是不记住匹配项。这种括号叫作非捕获括号,使得你能够定义与正则表达式运算符一起使用的子表达式。看看这个例子 |
[] 原子表详解:
- /[12345]/:表示匹配1、2、3、4、5中的任意一个数字就行。[ ]里面的值是或的含义,只要有其中一个就可以匹配成功
- 原子表匹配区间问题:原子表中可以升序,但是不能降序。比如:[0-9]、[a-z]是可以的,但是不可以[9-0]、[z-a]这样写
- 原子表中的特殊字符:特殊字符放在[ ]里面代表的就是普通字面量的含义,没有任何的特殊含义
- [ ( ) ]:中的()表示的就是普通的()的字面量,并没有特殊含义,不代表这是原子组。
- [ + ]:中的+表示的就是普通的+的字面量,并没有特殊含义,哪怕通过转义(\+)他也代表的是+的字面量,而不是0个或多个。
- 利用原子组匹配所有的字符:[\d\D]、[\s\S] 。分析:\d:表示0-9之间的数,而\D表示除了0-9之间的数,那么[\d\D]:表示的就是0-9之间的数,和除了0-9之间的数,那么就是所有的字符。
- 例子:日期格式中带-或者/的日期都可以匹配到
let str1="2025-01-01"
let str2="2025/01/01"
let str3="2025-01/01"
let reg=/^\d{4}[-/]\d{2}[-/]\d{2}$/
console.log(reg.test(str1),str1,reg)
console.log(reg.test(str2),str2,reg)
console.log(reg.test(str3),str3,reg)
let reg2=/^\d{4}([-/])\d{2}\1\d{2}$/
console.log(reg2.test(str1),str1,reg2)
console.log(reg2.test(str2),str2,reg2)
console.log(reg2.test(str3),str3,reg2)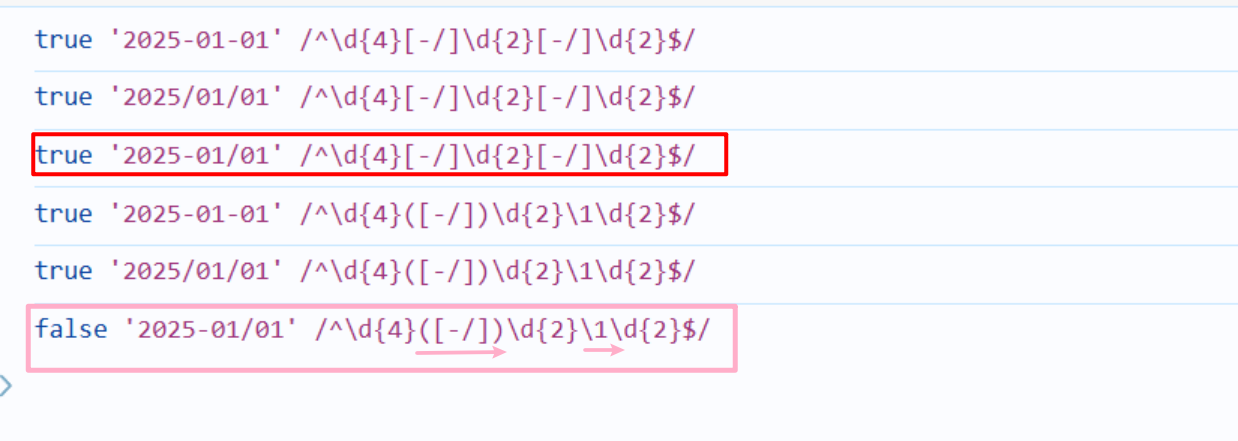
注意:在我们使用 /^\d{4}[-/]\d{2}[-/]\d{2}$/正则的时候,这个日期格式为2025-01/01的也被匹配成功,但是这个前面是-,后面是/这样的格式并不正常,我们希望的是-或者/前面出现的是什么后面就出现的是什么。这个时候就可以用原子组(),()会记住被匹配的项
()原子组详解
基本内容介绍
- /(12)/:表示匹配12。()里面是一个整体,是一个完全匹配的意思。
- 加上|:/(12|34)/:表示匹配12或者34其中任意一个数字就行。
- 原子组中的特殊字符:特殊字符放在()里面代表的就是普通字面量的含义,没有任何的特殊含义 。
- 关于\n:n是正整数,表示在该正则表达式中从左往右计算的第n个捕获括号(里面的匹配的值。注意在(?:X)非捕获括号中是没有用的。
- /^\d{4}([-/])\d{2}\1\d{2}$/:中的\1就表示该正则表达式的第一个括号的([-/])里面匹配到的值
- 例如:
- 在上面的案例/^\d{4}([-/])\d{2}\1\d{2}$/.test("2025-01/01")返回的就是false,
- 是因为加上了原子组后因为前面([-/])匹配的值为-,这时候后面的\1的值就为-,
- 所以我们2025-01/01后面为/字符的时候,就和正则表达式中的被记住的值-不一致,匹配没能成,返回false。
原子组的替换:配合replace方法
1.在replace()方法中,第二个参数可以是字符串,也可以是函数。
2.当replace第二个参数为字符串的时候,关于使用的$。
a) $n是需要配合原子组使用;
b) $`、$'、$&无需配合原子组使用,是与正则表达式匹配的值有关
| $n | n是正整数,n表示正则表达式中从左到右的第n个捕获括号里面匹配的值 |
| $` | 正则表达式匹配的值,(前面)左边的所有内容 |
| $' | 正则表达式匹配的值,(后面)右边的所有内容 |
| $& | 正则表达式匹配的内容 |
c) $n例子:
// 1、电话号的格式变为010-1234567的格式
let str="(010)1234567 (024)7654321"
let reg=/\((\d{3,4})\)(\d{7,8})/g
console.log(str.replace(reg,"$1-$2"))
// 010-1234567 024-7654321\(:是转义的左边括号(;
\):是转义的右边括号);
$1:表示的是(\d{3,4})的匹配的值010还有024,
$2:表示的是(\d{7,8})的值1234567还有7654321
d) $`、$'、$&例子:
let str1="ab表达CD"
let reg1=/表/
console.log(str1.replace(reg1,"$&")) //ab表达CD
console.log(str1.replace(reg1,"$`")) //abab达CD
console.log(str1.replace(reg1,"$'")) //ab达CD达CD正则表达式:/表/,就是完全匹配表这个字
字符串:ab表达CD ,那么在/表/的匹配下:
$&的值就是"表";$`的值就是"表"前面的内容"ab";$'的值就是"表"后面的内容"达CD"
3. 当replace第二个参数为函数的时候,根据参数决定值。需要配合原子组使用。如:
a ) str.repacle(reg,(v,p1,p2,p3……Pn)=>{XXX})中
- 第一个参数v表示:正则表达式匹配的内容
- pn表示:正则表达式中从左到右的第n个捕获括号里面匹配的值。
- 第二个参数p1表示:正则表达式中从左到右的第1个捕获括号里面匹配的值。
let str="(010)1234567 sa"
let reg=/\((\d{3,4})\)(\d{7,8})/g
str.replace(reg,(v,p1,p2)=>{
console.log(v,'v') //(010)1234567 v
console.log(p1,'p1') //010 p1
console.log(p2,'p2') //1234567 p2
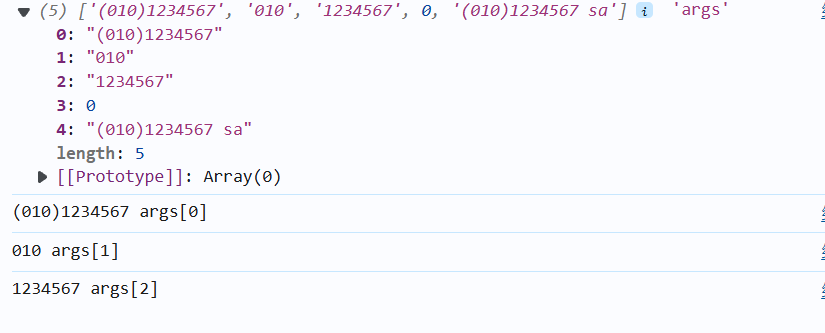
})b)当参数很多的时候可以利用...的方式。比如:str.repacle(reg,(...args)=>{XXX})
let str="(010)1234567 sa"
let reg=/\((\d{3,4})\)(\d{7,8})/g
replace(reg,(...args)=>{
console.log(args,'args')
console.log(args[0],'args[0]')
console.log(args[1],'args[1]')
console.log(args[2],'args[2]')
})
原子组别名 (?<XX> )
- 语法:(?<XX> )的格式就是在正则表达式中给这个原子组起别名的方式。
- 使用别名:在正则表达式之外,使用这原子组的的时候可以用$<XX>的方式获取(?<XX> )原子组匹配的值。无需在一个个括号的查询了。(注意在正则表达式里面要是用原子组还是要是用\n的格式)
- 例如:
let str="(010)1234567"
let reg=/\((?<area>\d{3,4})\)(?<phone>\d{7,8})/
let list=[]
console.log(str.replace(reg,`$<area>-$<phone>`))
let array=str.match(reg)
console.log(array)
list.push(array["groups"])
console.log(list)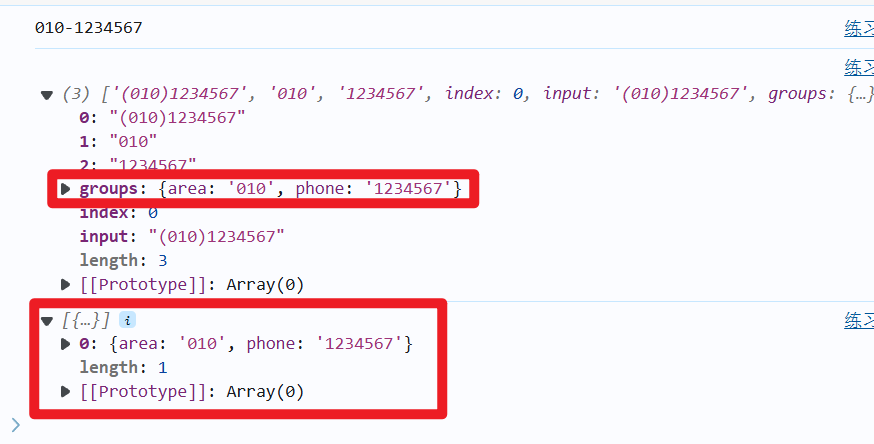
array["groups"]:可以获取整个原子组的别名和原子组该别名匹配到的值
list.push(array["groups"]) :放在数组中
断言匹配
| x(?=y) | 匹配'x'仅仅当'x'后面跟着'y'.这种叫做先行断言。(后面跟着是什么) 例如,/Jack(?=Sprat)/会匹配到'Jack'仅当它后面跟着'Sprat'。/Jack(?=Sprat|Frost)/匹配‘Jack’仅当它后面跟着'Sprat'或者是‘Frost’。但是‘Sprat’和‘Frost’都不是匹配结果的一部分。 |
| (?<=y)x | 匹配'x'仅当'x'前面是'y'.这种叫做后行断言。(查找前面是什么) 例如,/(?<=Jack)Sprat/会匹配到' Sprat '仅仅当它前面是' Jack '。/(?<=Jack|Tom)Sprat/匹配‘Sprat ’仅仅当它前面是'Jack'或者是‘Tom’。但是‘Jack’和‘Tom’都不是匹配结果的一部分 |
| x(?!y) | 仅仅当'x'后面不跟着'y'时匹配'x',这被称为正向否定查找。(零宽负向先行断言,查找后面不是什么) 例如,仅仅当这个数字后面没有跟小数点的时候,/\d+(?!\.)/ 匹配一个数字。正则表达式/\d+(?!\.)/.exec("3.141") 匹配‘141’而不是‘3.141’ |
| (?<!y)x | 仅仅当'x'前面不是'y'时匹配'x',这被称为反向否定查找(零宽负向先行断言,查找前面不是什么) 例如,仅仅当这个数字前面没有负号的时候, |
- 断言匹配:就相当于是一个条件语句
- (?=y)、(?<=y)、(?!y)、(?<!y):这是断言的格式,虽然有括号,但是并不是原子组,所以在\n的查询是第几个捕获括号时候(?=y)……是不被计算数量的。
- /[a-z]+(?!\d+)$/:$是限制[a-z]+的,并不是前面的断言。断言可以理解为[a-z]+的一个条件语句。
1、案例:电话号中间四位脱敏
let str="16023451234"
let reg=/(?<=\d{3})\d{4}(?=\d{4})/g
console.log(reg.test(str))
const phone=str.replace(reg,(v)=>{
return "*".repeat(4)
})
console.log(phone) //160****12342、 案例:屏蔽敏感词a
let str="abcs"
let str1="cas"
let str2="csa"
let str3="acssa"
let str4="cs"
let reg=/^(?!.*a.*).*/
console.log(reg.test(str)) //false
console.log(reg.test(str1)) //false
console.log(reg.test(str2))//false
console.log(reg.test(str3))//false
console.log(reg.test(str4))//true其他类
转义字符 \
1、 \ :转义字符。当一个字符有多个含义的时候,就需要进行转义。将特殊字符转义为字面量的含义。
2、+的字面量就是+,另一层含义是匹配一个或多个字符。当在/a+/中+就是特殊字符匹配一个或多个。
a)如果想要里面的+就是字面量+的时候,需要用到转义,写法:/a\+/
3、在原子表[]、原子组()中的特殊字符就是字面量的含义,无需转义,就算转义了也为字面量的含义。
字符属性 \p
1、\p:表示检测每个字符的属性,基于Unicode属性的字符开头
2、\p{}是需要配合着u模式使用的,要不然没有效果。比如:/\p{L}/u
3、Unciode的属性代码:
a)通用类型
| \p{L} | 表示所有字母,涵盖各种语言的字母字符,比如:英文字母,汉字等 |
| \p{M} | 用于标记符号,项变音符子类的用于修饰其他字符的符号 |
| \p{N} | 匹配所有的数字字符,例如0到9等更种数字表示形式 |
| \p{P} | 匹配标点符号相关,像逗号,句号,引号等 |
| \p{S} | 匹配货币符号,数字符号等,例如:¥,$,+,-…… |
| \p{Z} | 匹配空白字符,如空格,制表符…… |
b) 脚本属性:script,简写为sc
| \p{sc=Han} | 专门用于匹配汉字字符 |
| \p{sc=Arabic} | 针对阿拉伯字符进行匹配 |
c)还有很多不列举了,不常用。
4、例如
console.log(/\p{N}/.test("12")) //false,没有使用模式u
console.log(/\p{N}/u.test("12")) //true
console.log(/\p{N}/u.test("Ⅱ"))//Ⅱ:罗马数字。true
console.log(/\p{sc=Han}/u.test("你好")) //true模式(通过标志进行高级搜索)
1、 正则表达式有六个可选参数 (flags) 允许全局和不分大小写搜索等。这些参数既可以单独使用也能以任意顺序一起使用,并且被包含在正则表达式实例中。
| i | 不区分大小写搜索。例如:/[a-z]/i等价于[a-zA-Z]。 |
| g | 全局搜索,全局进行匹配。例如/u/g可以匹配“huhudddu”中的所有的u。“huhudddu” |
| m | 多行搜索。(每一行单独处理) |
| s | 允许 |
| u | 使用 unicode 码的模式进行匹配。(配合unicode 码使用)例如:/\p{sc=Han}/u |
| y | 执行“粘性 ( |
2、m模式案例:每一行进行单独处理。
a) 因为字符串中“#1 a,10ss # 你好”是和别的行格式不一样的,所以我们利用m模式,进行每一行的单独处理。
let str=`
#1 a,10元 #
#2 b,20元 #
#1 a,10ss # 你好
#4 d,20元 #
`
let reg=/^\s*#\d+\s+.+\s+#$/gm
const lesson=str.match(reg).map(v=>{
v=v.replace(/\s+#\d+\s*/,"").replace(/#/,"")
let [name,price]=v.split(",")
return {name,price}
}
)
console.log(lesson)
// [
// {
// "name": "a",
// "price": "10元 "
// },
// {
// "name": "b",
// "price": "20元 "
// },
// {
// "name": "d",
// "price": "20元 "
// }
// ]3、 y模式:
a) y模式和g模式的区别
- y模式:是一直连续的满足匹配条件,如果不满足的话就停止了
- g模式:就是从头查找到结尾
let str="abcabc"
let reg=/a/y
let reg1=/a/g
console.log(reg.exec(str),"/a/y")
console.log(reg.lastIndex,"/a/y")
console.log(reg.exec(str),"/a/y")
console.log(reg.lastIndex,"/a/y")
console.log(reg1.exec(str),"/a/g")
console.log(reg1.lastIndex,"/a/g")
console.log(reg1.exec(str),"/a/g")
console.log(reg1.lastIndex,"/a/g")
console.log(reg1.exec(str),"/a/g")
console.log(reg1.lastIndex,"/a/g")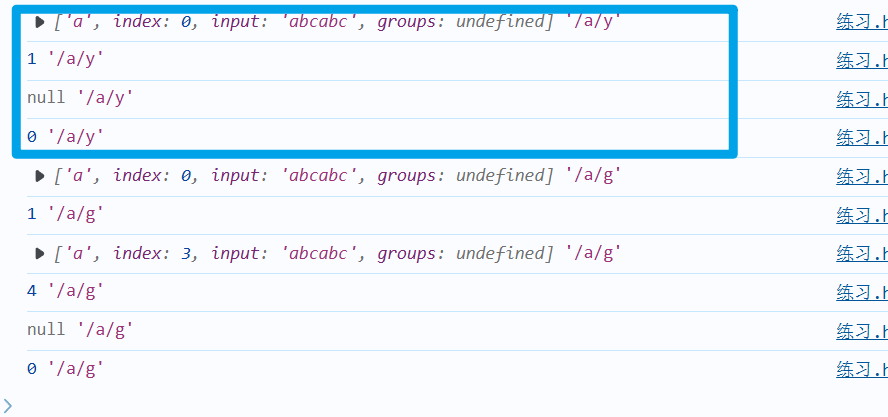
/a/y:匹配到了第一个a是满足条件的,但是后面的b是不满足条件的,就不在匹配了,就停止匹配了。
/a/g:是从头到尾的查找。
b) y模式用途:在比较多的字符的时候,可以利用y模式,配合lastIndex属性其查找从哪个索引开始进行匹配,提高检索效率
let str="我的号码是:12345678,23345566,77877777"
// 匹配数字
let reg=/(\d+),?/y
//从第6个索引值开始匹配(数字1)
reg.lastIndex=6
let list=[]
while(res=reg.exec(str)){
list.push(res[1])
}
console.log(list)
// ["12345678","23345566","77877777"]方法
| search | 一个在字符串中测试匹配的 String 方法,它返回匹配到的位置索引,或者在失败时返回 -1。(返回的是第一个匹配成功的位置) 例如:"eara".search(/a/)返回的是1 |
| match | 一个在字符串中执行查找匹配的 String 方法,它返回一个数组,在未匹配到时会返回 null。 |
| matchAll | 一个在字符串中执行查找所有匹配的 String 方法,它返回一个迭代器(iterator) |
| split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 比如:在日期格式的时候,不确定是用-还是/分隔的时候,可以使用split方法,str.split(/[-\/]/)进行拆分年月日的值。 |
| replace | 一个在字符串中执行查找匹配的 String 方法,并且使用替换字符串替换掉匹配到的子字符串。(关于replace中正则相关替换在上面原子组替换中有笔记) |
| test | 一个在字符串中测试是否匹配的 RegExp 方法,它返回 true 或 false。 |
| exec | 一个在字符串中执行查找匹配的 RegExp 方法,它返回一个数组(未匹配到则返回 null) |
1、 当你想要知道在一个字符串中的一个匹配是否被找到,你可以使用 test 或 search 方法;想得到更多的信息(但是比较慢)则可以使用 exec 或 match 方法。
2、关于macth方法:
a) match方法,返回的是一个数组。
b) 但是正则表达式有在有g和无g的模式下是有区别
- 在有g的模式下,是只返回一个数组,数组里面不包含任何的细节
- 在无g的模式下,返回一个数组,数组里面包含细节的。
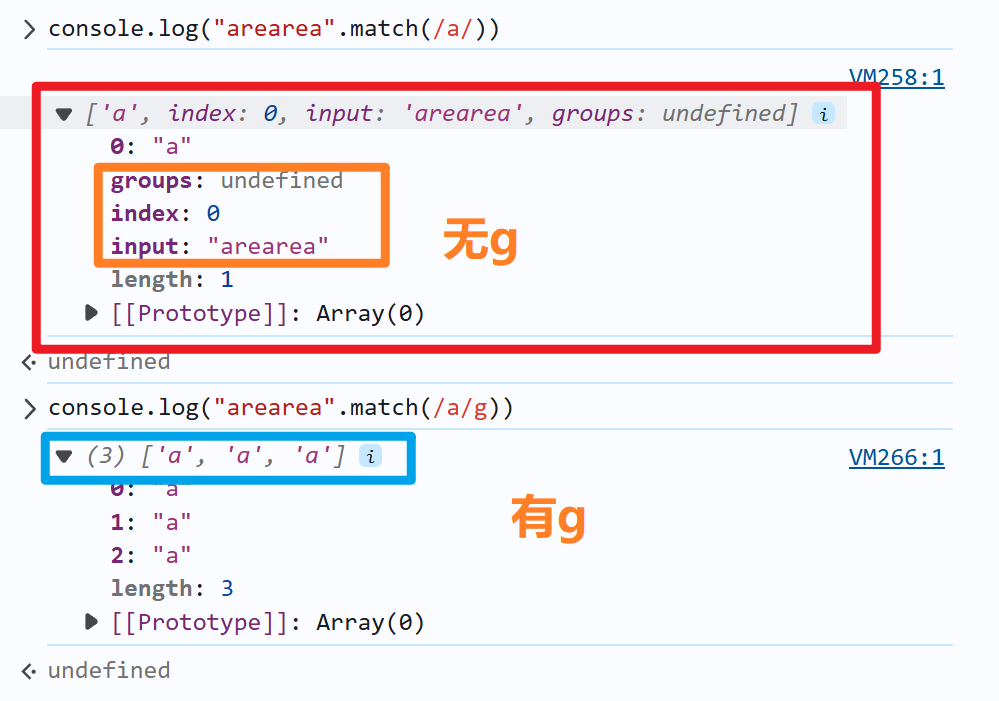
3、关于exec方法
a) 每次输出的都是该次找到的匹配值的结果,哪怕是全局匹配(有g的模式下)也是输出的是一次匹配成功的值。
b) 但是可以利用lastIndex属性(开始下一个匹配的起始索引值)进行下一次的匹配。
c) exec方法,在匹配不到的时候返回的是null。
let str="abcabca"
let reg1=/a/g
console.log(reg1.exec(str),"exec")
console.log(reg1.lastIndex,"lastIndex")
console.log(reg1.exec(str),"exec")
console.log(reg1.lastIndex,"lastIndex")
console.log(reg1.exec(str),"exec")
console.log(reg1.lastIndex,"lastIndex")
console.log(reg1.exec(str),"exec")
console.log(reg1.lastIndex,"lastIndex")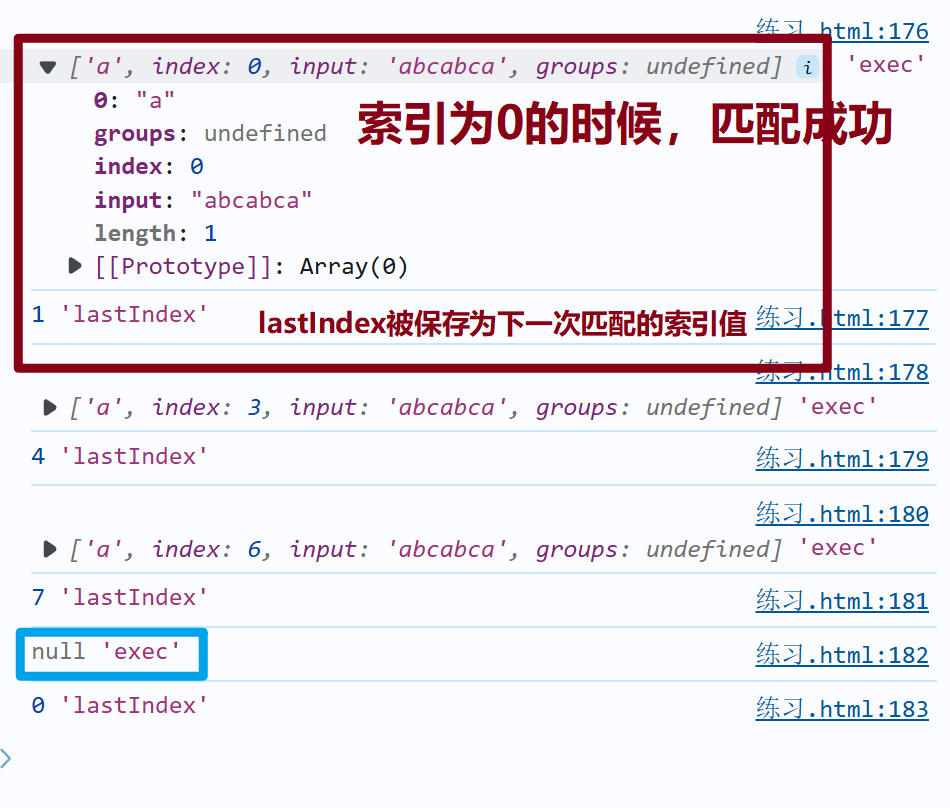
d) 所以,exec方法,可以配合循环使用。比如:查询某个字母出现的次数
let str="abcabca"
let reg1=/a/g
let count=0
while(res=reg1.exec(str)){
console.log(res,"exec")
console.log(reg1.lastIndex,"lastIndex")
count++
}
console.log(count) //3
//reg1.exec(str)在没有匹配成功的时候,为ull,循环就会结束了4、 返回的是数组时,相关介绍
let str="asd(010)1234567dda"
let reg=/\((?<area>\d{3,4})\)(?:\d{7,8})/
console.log(str.match(reg))
console.log(reg.exec(str))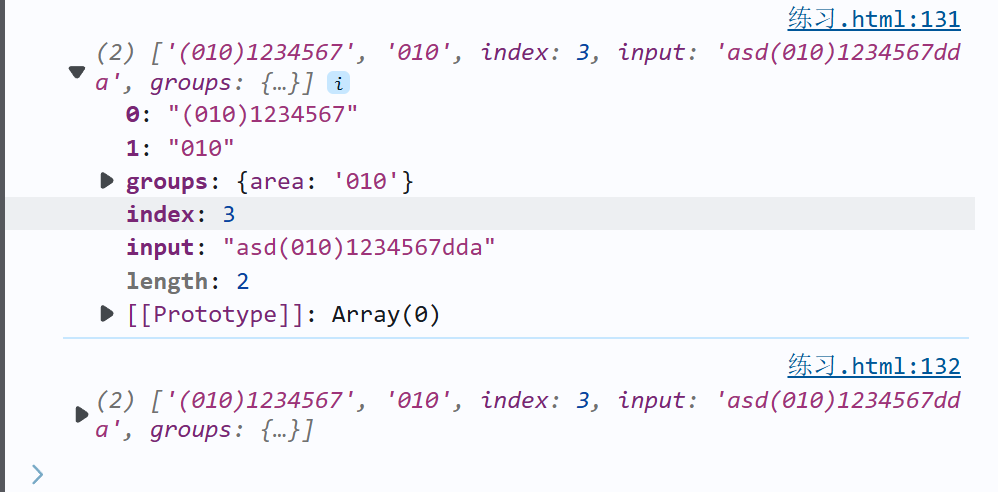
- [0]:最近一个匹配的字符串。例如:(010)1234567指的
- [1]:是正则表达式从左到右开始的第一个捕获括号匹配的值。例如:(010)。本项目有两个原子组,但是后面的原子组(?:\d{7,8}),因为是非捕获括号所以不被记录。
- index:在输入的字符串中匹配到的以 0 开始的索引值。例如:该正则是在第3个索引(值为0)的时候开始匹配成功的。
- groups:是对象格式,在设置原子组的别名的时候,显示该原子组的别名和所匹配到的值。如果没有设置原子组别名的,也不会显示在groups对象中。例如:{ "area": "010" }
- input:初始字符串。例如:asd(010)1234567dda
5、案例:对需要满足多个正则的校验,比如,有字母数字组成的5-10位,且必须包含大写字母,
let reg=[/^[\da-z]{5,10}$/i,/[A-Z]/]
console.log(reg.every(e=>e.test("ass12d12"))) //false
console.log(reg.every(e=>e.test("ass12dA12"))) //true
















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









