










并发python编程基础与实例
先验知识:
掌握操作系统的进程,线程异同之处。
- 并发的应用场景
1.减少处理特定任务的时间(爬虫缩短时间),提升速度。
2.提升程序速度的常用4种方法:

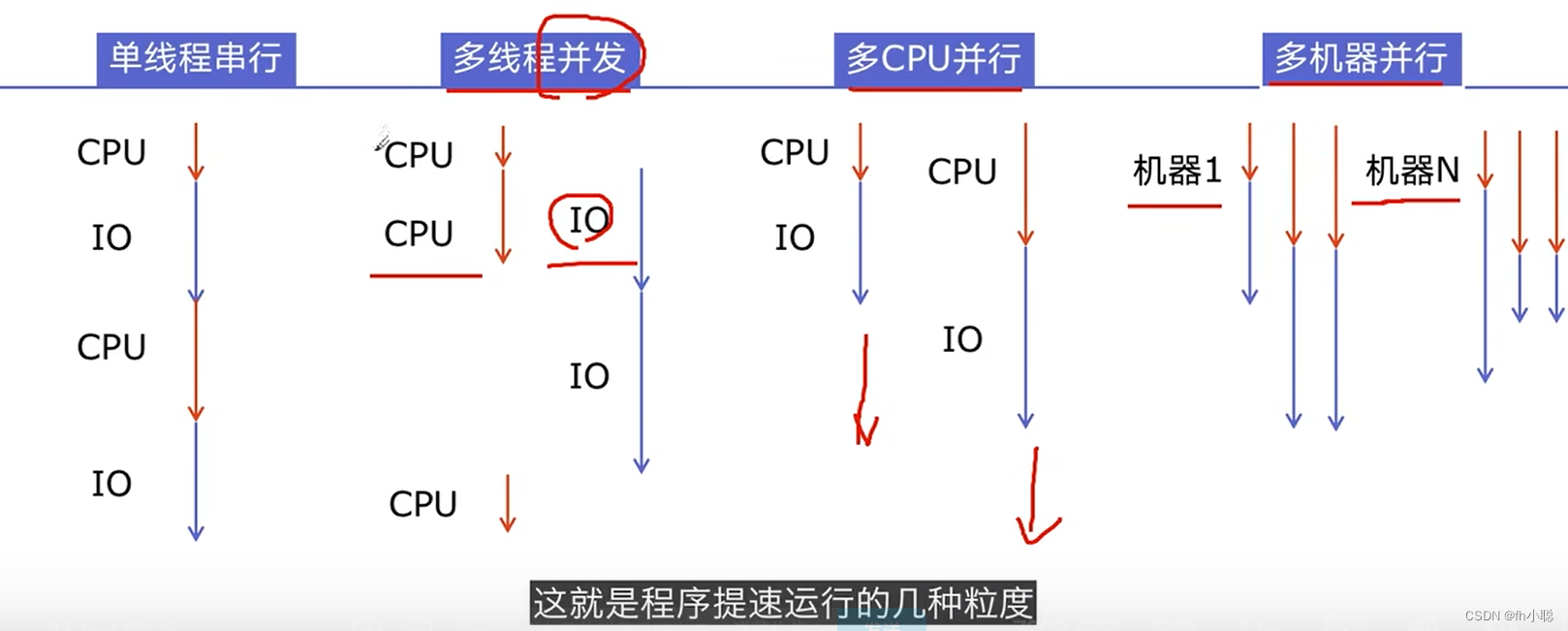
本博客只研究多线程并发与多CPU并行的两种实现技术,不涉及多机器并行的大数据技术的实现方案。
- Python对并发编程中的相应支持

Python并发编程的三种方式
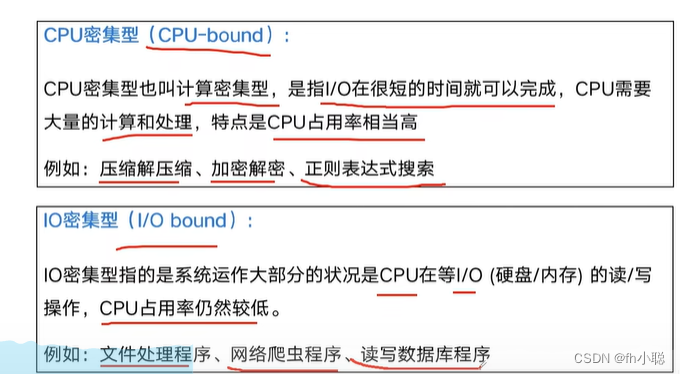
先验知识:什么是CPU的密集型计算,IO的密集型计算?
1.多线程
2.多进程
3.多协程
三者的关系与各自的优缺点:

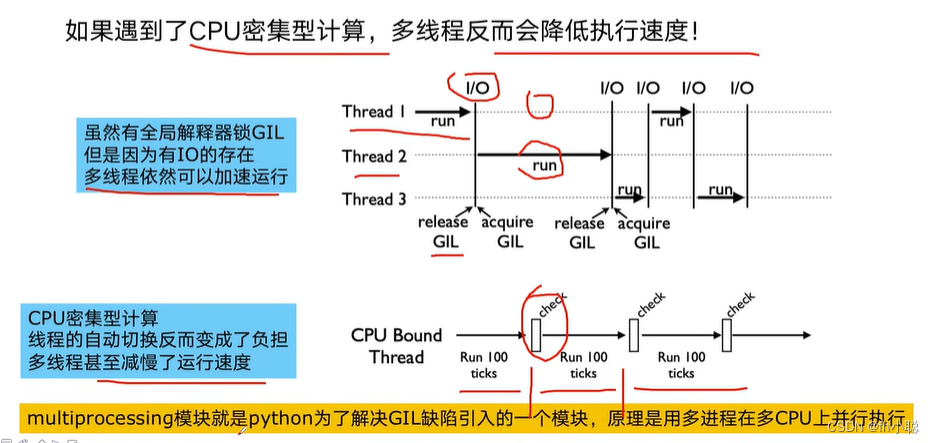
注意GIL(全局解释器锁)将在后面进行补充。它也是使得Python不能使用多核CPU进行并发执行的罪魁祸首。
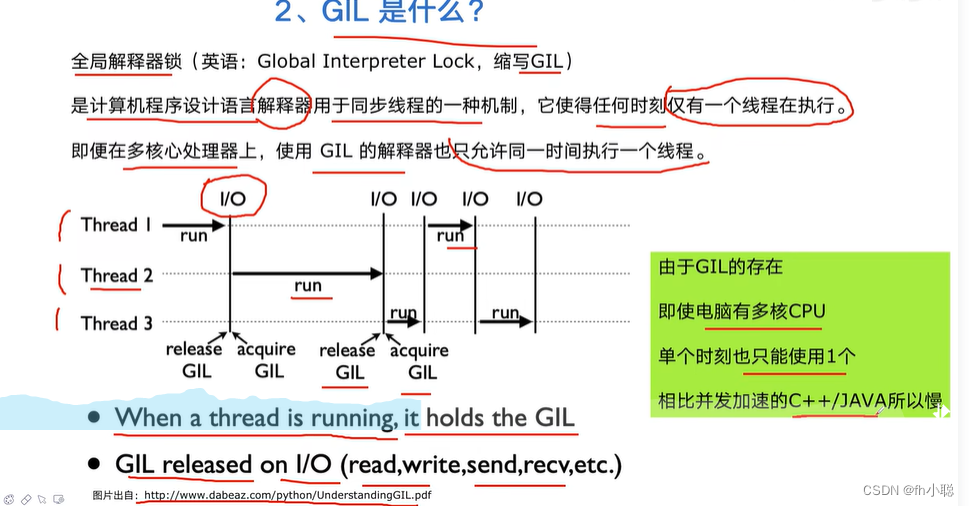
规避GIL的策略:

三种并发技术选型的原则流程图:

Python创建多线程:

以爬虫获取博客园为例,对比单线程与多线程的区别:
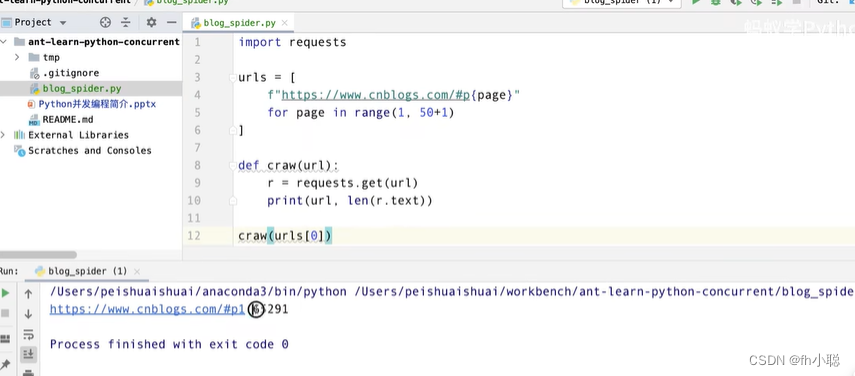
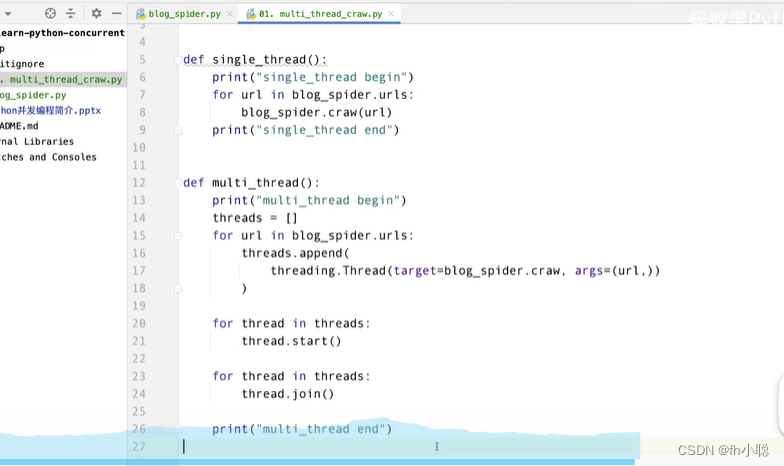
测试上述函数:

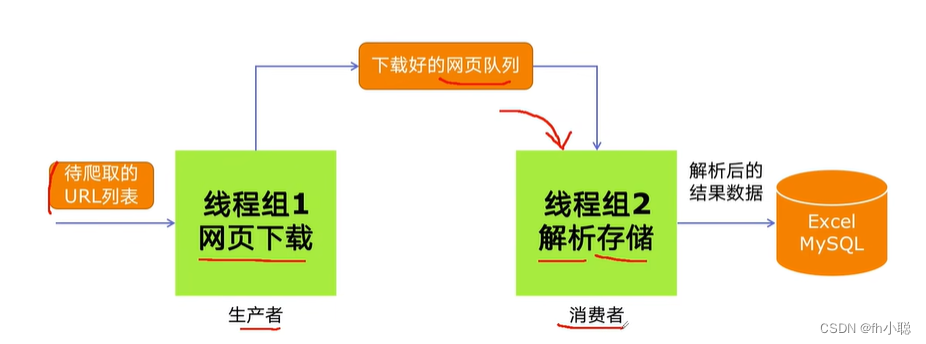
生产者消费者多线程爬虫模式
多组件的Pipeline技术架构
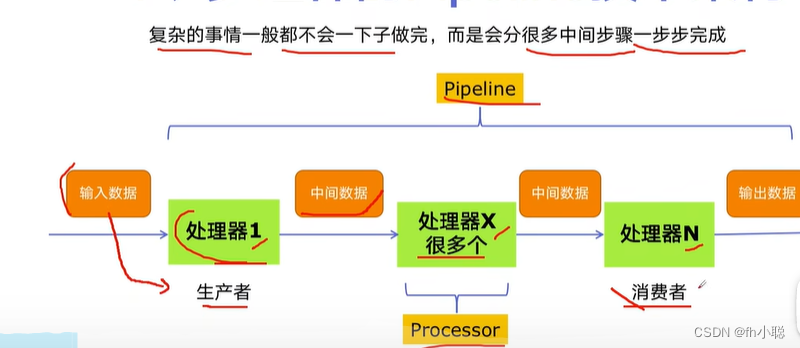
因为多组件的Pipeline技术架构就是一种生产者-消费者技术架构的原型,所以在这里作为先验知识进行相应的补充。
多线程数据通信所需的queue:

在上面的实例代码的基础上,进行改造,爬取每条博客的标题:
单线程版本的生产者-消费者爬虫实例:
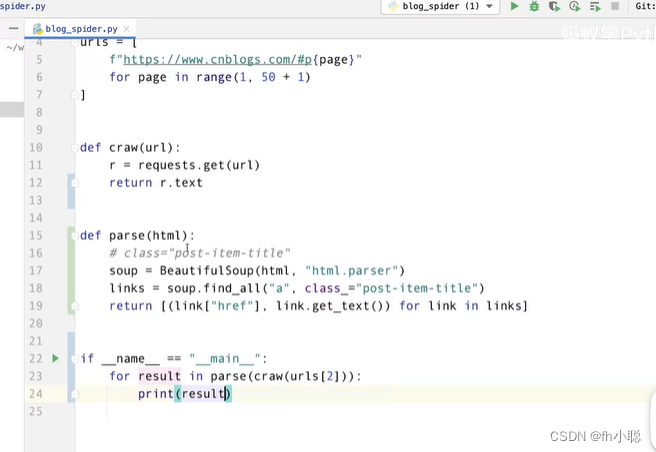
craw函数作为生产者,parse作为消费者。
多线程版本的生产者-消费者爬虫实例:
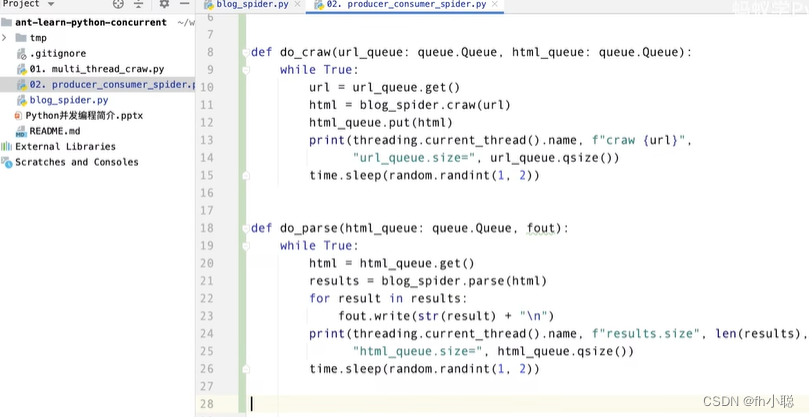
调用处:
共设置三个生产者,两个消费者
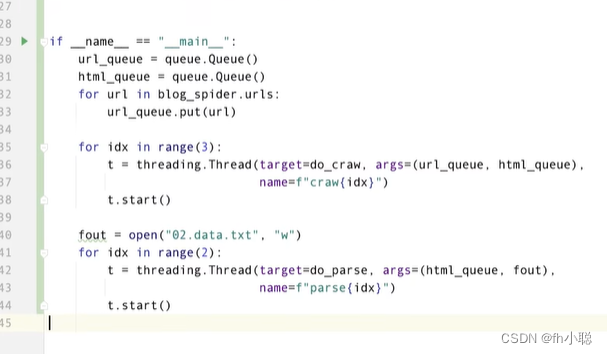
显示效果:
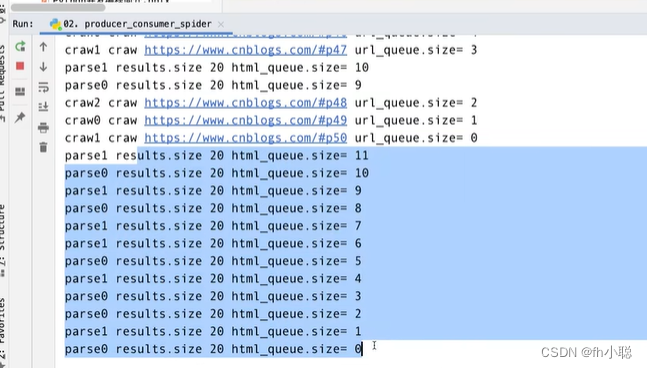
02.data.txt内容:
线程安全

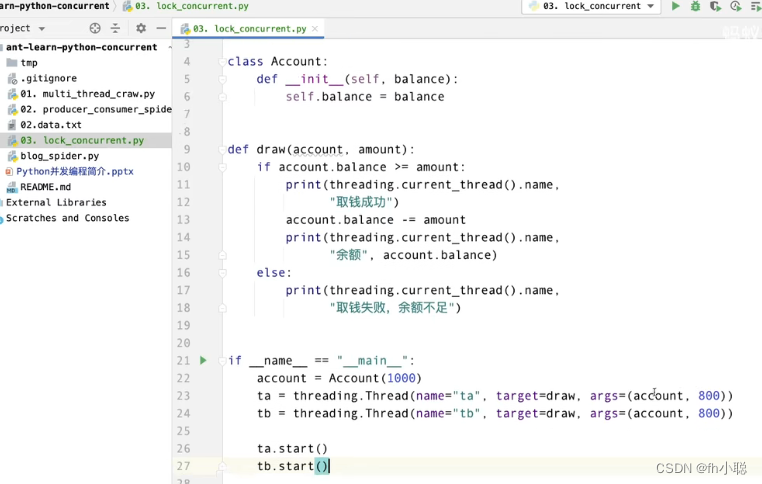
未加锁时直接导致银行亏损600元钱。
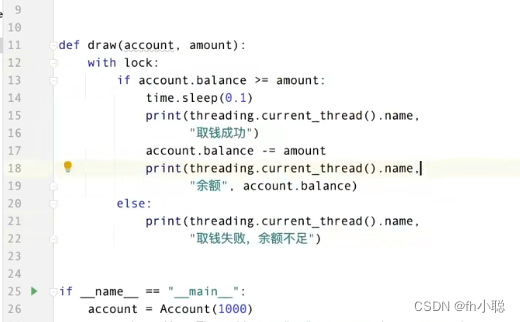
针对以上问题的应对解决方案Lock加锁:

以银行取钱的实例作为编程实例:
两个线程取800元钱同时:
下面是不加锁是导致的问题代码,因为cpu调度哪一个线程的时机是不确定的。尤其是在涉及项目中的远程调用和线程睡眠阻塞时,一定会产生意想不到的问题。
修改按照上面的加锁简化版with,先去产生一个Lock对象
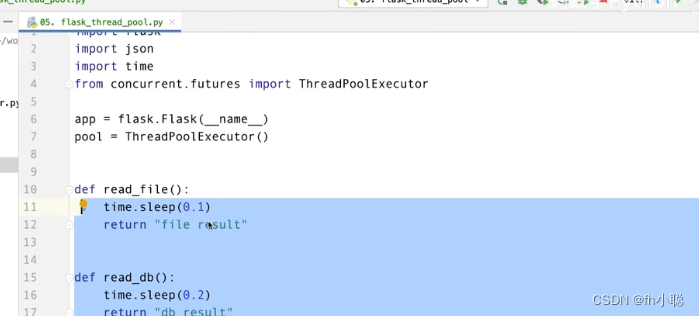
线程池
线程池原理
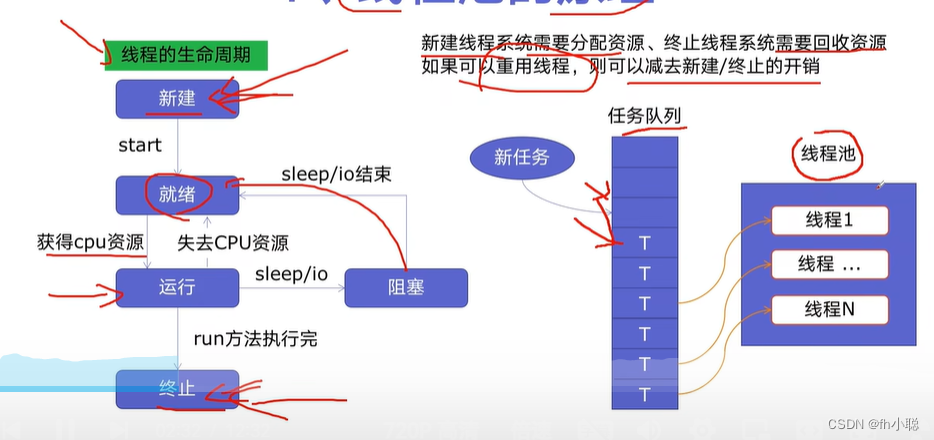
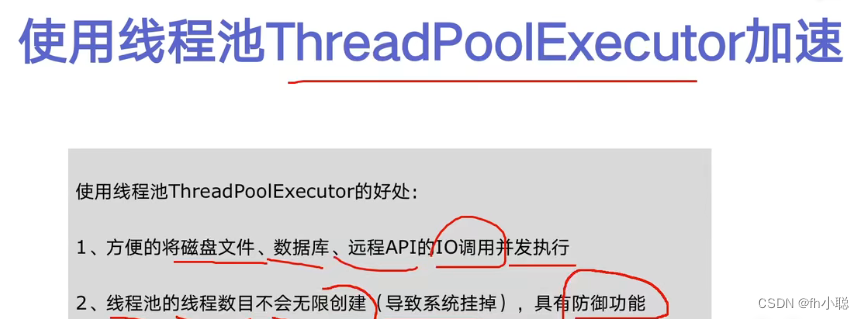
线程池好处:

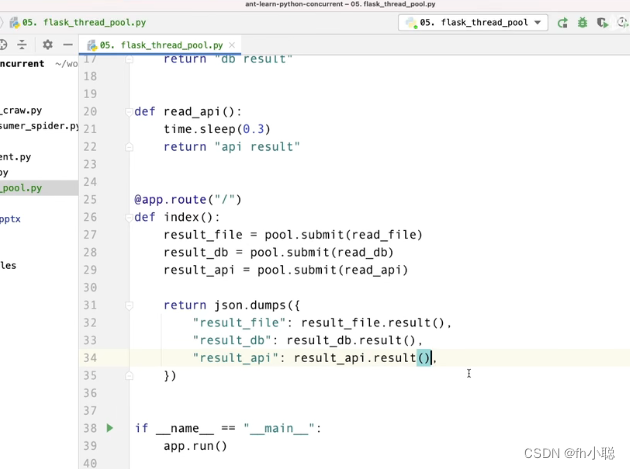
python中的线程池技术:ThreadPoolExecutor

右侧使用方法的as_completed是任务队列中先执行结束时才先输出,这一点与右侧的第一种结果遍历方案有所不同。
连接池技术属于concurrent.futures类库
改造原先的爬虫程序,可以得到url和html博客标题的对应关系
Web服务采用线程池的好处及架构
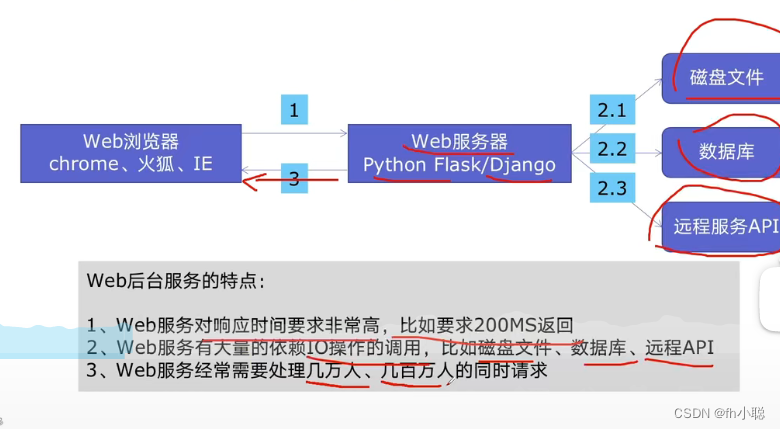
使用postman可以实现服务返回响应时间,在自己的项目开发中可以积累经验
原先需要600ms:
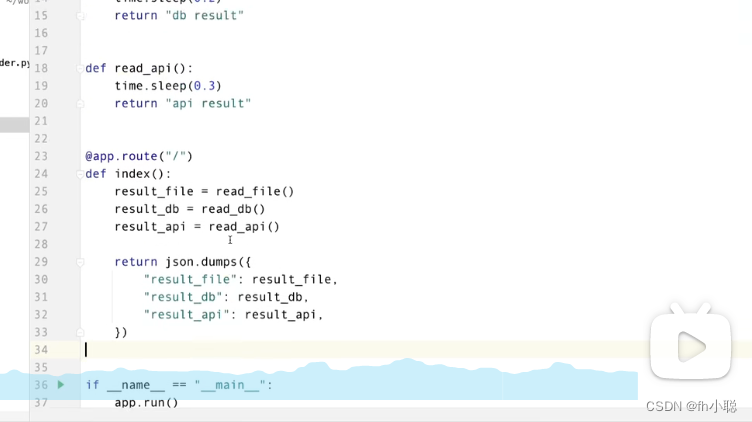
改造后:
全局建一个pool对象
至此多线程并发编程结束。
多进程并发编程
为什么需要?
使用api:

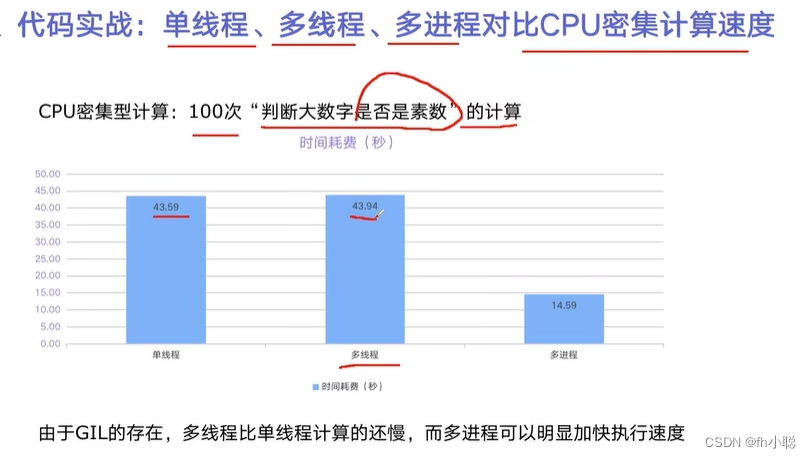
素数的判断程序
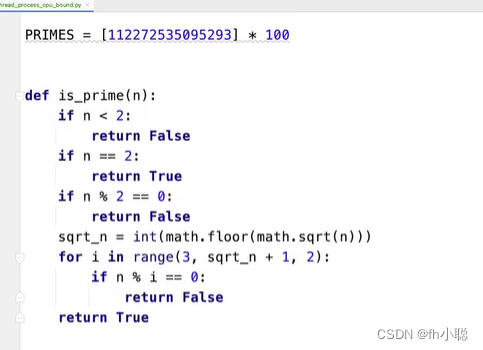
其余的函数设计(对比三种实现的方式):
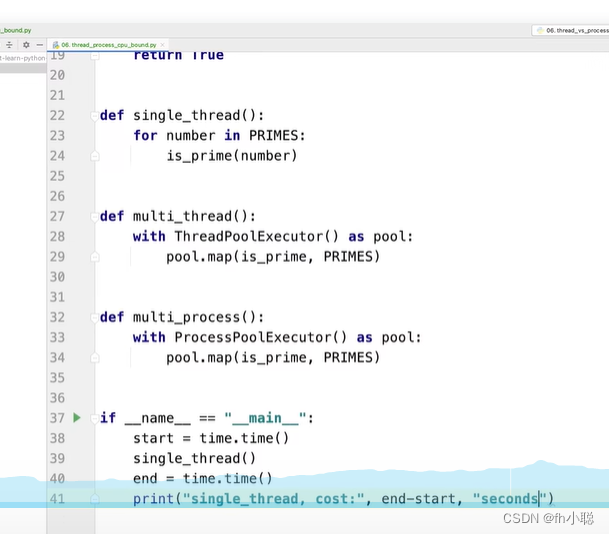
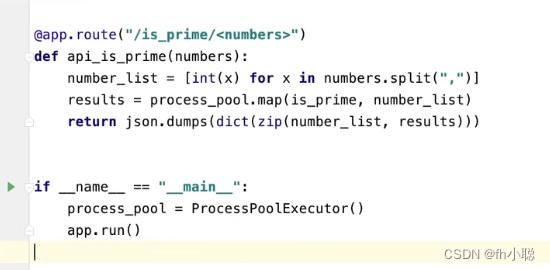
注意多进程(CPU密集型计算)的实现需要与多线程方式进行代码的顺序调整。
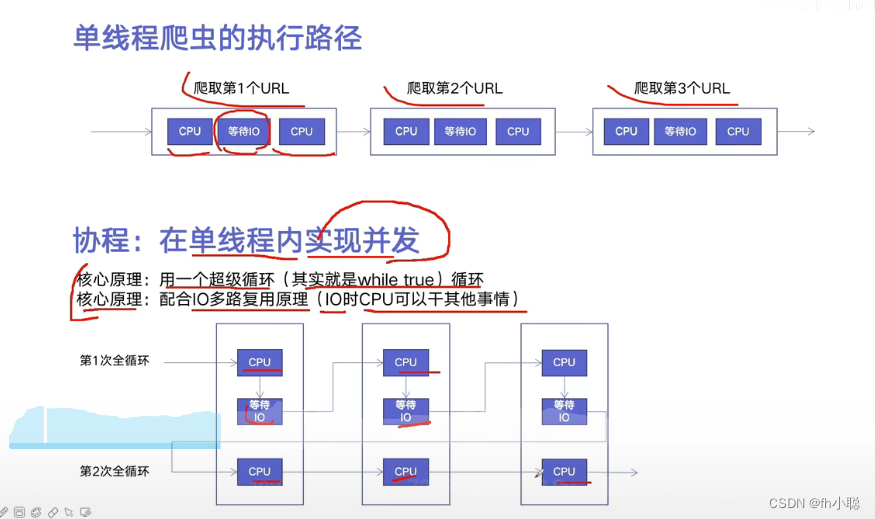
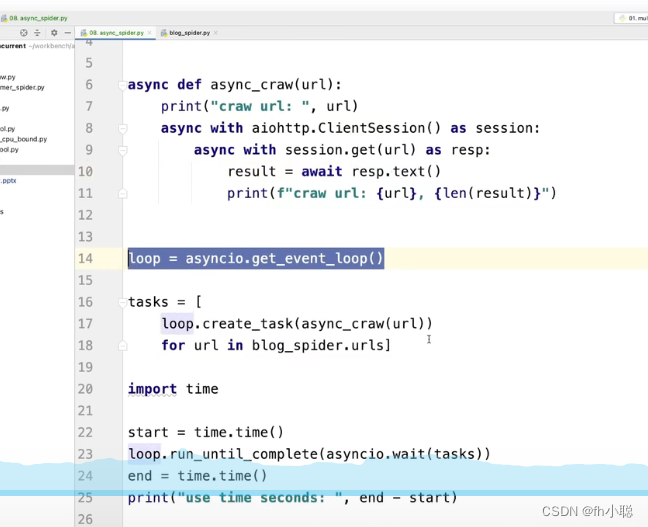
异步IO
原理:在等待IO时再去干其他的事情,从而提高效率。
await对应io时刻:(第三方库需要在IO时不能发生阻塞)

最后执行task等待循环执行完成。
协程就是在异步IO中执行的函数。需要使用超级循环来进行调度:
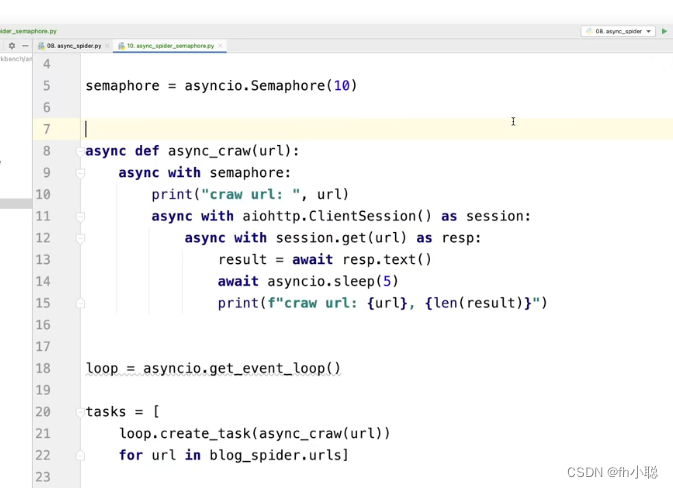
异步IO中控制爬虫的并发度
防止把目标爬取网站爬取坏,超出处理能力。
用以初始化设置并发度的控制
用信号量semaphore:开始并发–;释放完成++

在先前的爬虫程序只需要修改为:
【【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行】 https://www.bilibili.com/video/BV1bK411A7tV/?share_source=copy_web&vd_source=f59db7cd21a530d0ec8fbe737a772750


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









