







一、消息分区
- 不受单台服务器的限制,可以不受限的处理更多的数据
- 并且数据量过大之后,还会分段存储
二、顺序读写
- Kafka的消息时存储在磁盘中的文件中的,在写文件时以追加的方式写入,这个顺序读写效率是很高的
- 效率高主要是和随机读写进行比较,主要是磁盘的寻址过程效率高
- 磁盘顺序读写,提升读写效率
三、页缓存
- 页缓存是linux中的概念,可以理解为linux系统的缓存
- Kafka在读数据时,把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
四、零拷贝【重点】
Linux的IO模型:划分两个空间,用户空间和内核空间,用户空间权限比较小,内核空间权限更大一些,可以调用系统的一切资源。
1. 非零拷贝
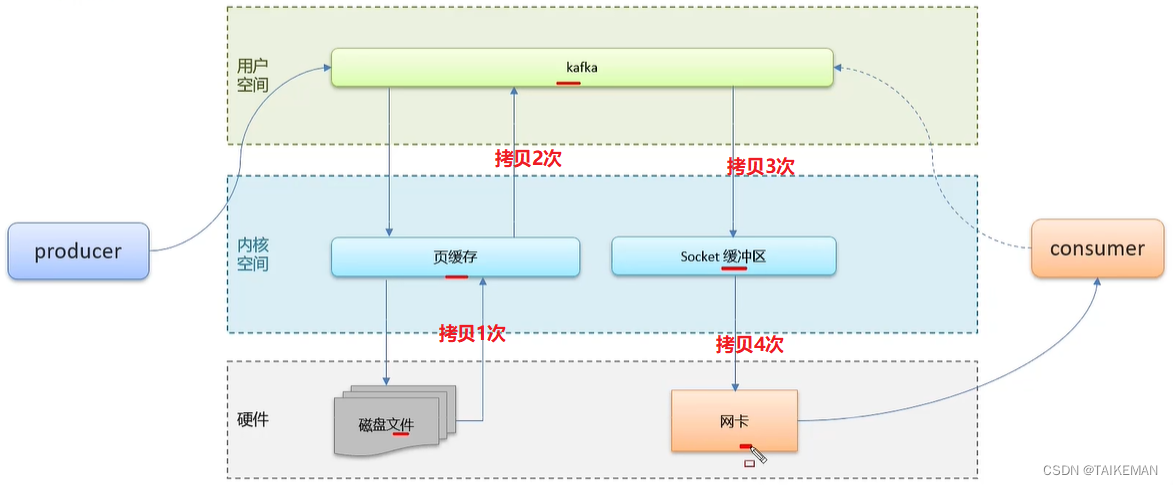
-
保存消息的流程:一个生产者去发送消息,肯定是在用户空间发起的,消息时要存储在磁盘文件中,用户空间没有权限调用磁盘读写,会先把数据拷贝到内核空间的页缓存中去处理,页缓存中数据到了一定批次后,就会把数据写入到磁盘中。
-
消费消息的流程:一个消费者去消费消息,首先用户空间的Kafka服务会先到页缓存中去找有没有这个消息,没有再到磁盘文件中去读取文件中的消息。把消息拷贝到页缓存中,再从页缓存中将数据拷贝到用户空间的Kafka中。Kafka将消息拷贝到socket缓冲区,socket缓冲区在将消息拷贝给网卡发送给消费者。这个过程性能肯定是不高的,因为消息拷贝的次数太多了。
2. 零拷贝
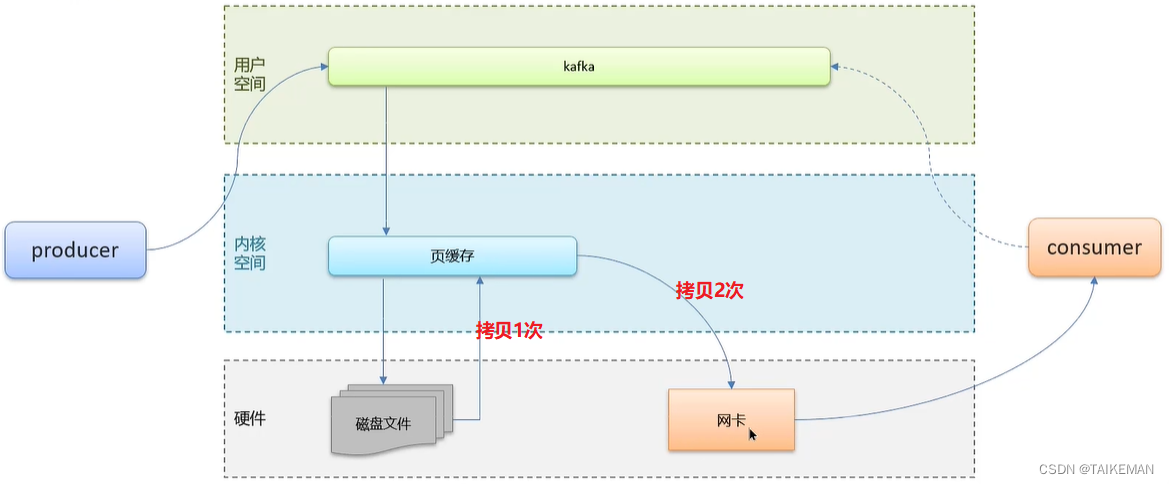
- 把所有的事情都委托给系统去操作,由系统直接从页缓存中将消息拷贝到网卡,发送给消费者
- 减少上下文切换及数据拷贝的次数
五、消息压缩
- Kafka内部提供了多种的消息压缩算法,发送数据时可以专门进行设计
- 压缩数据时,可以减少磁盘IO和网络IO
- 不过压缩会耗费一定的CPU,根据业务需求进行压缩设计
六、分批发送
- 将消息打包批量发送,减少网络传输开销,提高网络传输效率和吞吐量
- 通过参数的配置来批量发送消息的大小,默认:16KB
- 也可以设置等待时间,在等待时间内,如果消息没达到16KB大小,Kafka也会将缓冲区中的消息发送出去,避免消息积压
七、小结

八、模拟面试



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









