







 在爬取游民星空网站图片时,由于未设置时间间隔,可能导致IP被封,表现为能够正常浏览网页,但无法打开图片。目前问题尚未解决。
在爬取游民星空网站图片时,由于未设置时间间隔,可能导致IP被封,表现为能够正常浏览网页,但无法打开图片。目前问题尚未解决。
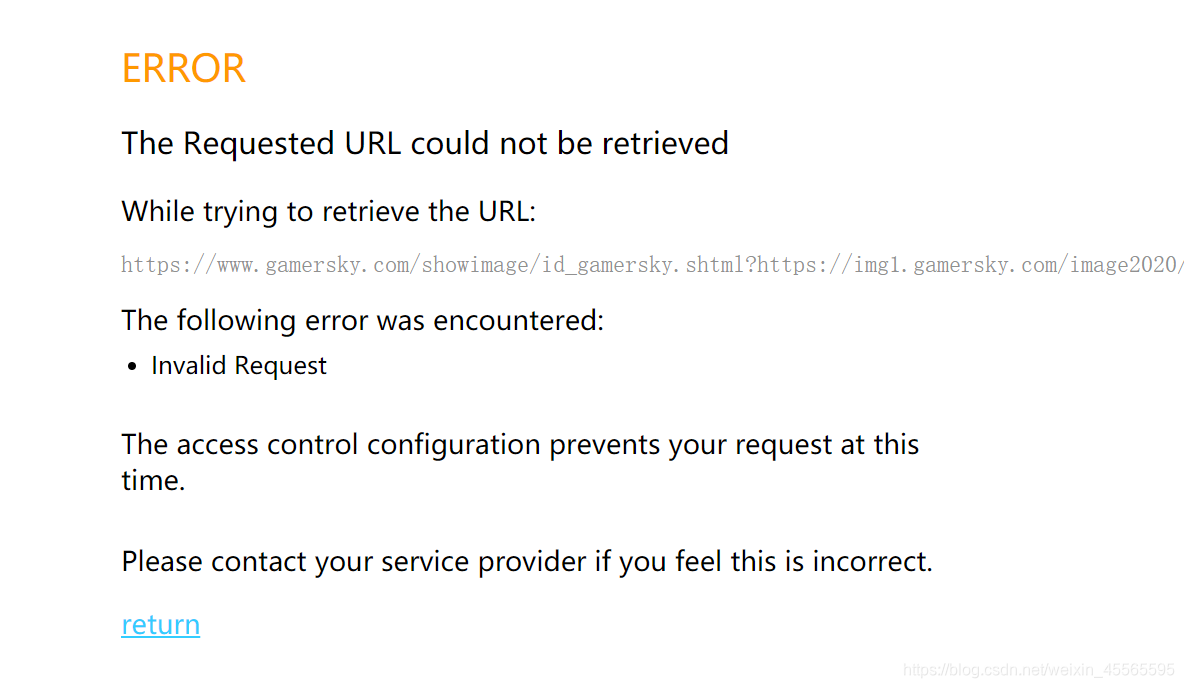
爬取下来的图片都打不开,没找到原因:
没有设置时间间隔,应该是被封ip了,网页可以看,但是点不开大图了。
import requests,urllib.request
from bs4 import BeautifulSoup
import os
import datetime
#获取当前年月日并创建以年月日命名的文件夹
today=datetime.date.today()
if not os.path.exists(f'{today}'):
os.makedirs(f'{today}') #如果没有这个path则直接创建
#爬虫部分
#头文件
header={"User-Agent":"Mozila/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"} #利用header模拟是从谷歌浏览器发出请求
name=1
for i in range(2,4):
url='https://www.gamersky.com/ent/202009/1319344_{}.shtml'.format(i)
r=requests.get(url,headers=header)
r.encoding = r.apparent_encoding#解决中文乱码问题
html=r.text
soup=BeautifulSoup(html,'lxml')#lxm 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









