







1、需求描述:
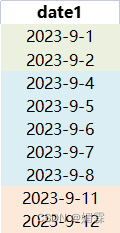
有一列不连续日期如下,需要把连续日期拼接在一起,
最终效果:2023-09-01至2023-09-02&2023-09-04至2023-09-08&2023-09-11至2023-09-12
**2、实现步骤:
基本思路是将相邻的连续日期分为一组,分别取出每组组内最小和最大值进行拼接**
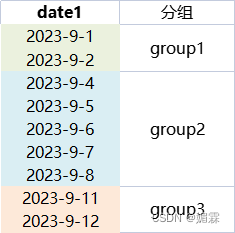
实现分组具体步骤

1)先对date1进行排序,见第1列
2)使用row_number()添加序号,见第2列
3)用lag() over() 函数取上一条日期记录,见第3列
4)用date_diff函数计算当前日期与上一条记录日期的差值,见第4列
5)用sum() over 函数计算累计至当前的日期差值,见第5列
6)用步骤2的序号减去步骤5的序号得到组别ID,见第6列
接着就是使用group by 在每组组内求出最小和最大日期
presto SQL 实现代码如下
with t0 as (
select cast('2023-09-01' as date) as date1 union all
select cast('2023-09-02' as date) as date1 union all
select cast('2023-09-04' as date) as date1 union all
select cast('2023-09-05' as date) as date1 union all
select cast('2023-09-06' as date) as date1 union all
select cast('2023-09-07' as date) as date1 union all
select cast('2023-09-08' as date) as date1 union all
select cast('2023-09-11' as date) as date1 union all
select cast('2023-09-12' as date) as date1
)
,
t1 as (
select
date1
,row_number() over(order by date1 asc) as rank1 -- 升序序号
,lag(date1,1,null) over(order by date1 asc) as lag_date1 -- 上一条日期记录
from t0
)
,
t2 as (
select
*
,date_diff('day',lag_date1,date1) as diffs -- 当前日期与上一条记录的日期差
from t1
)
,
t3 as (
select
*
,0 + coalesce(sum(diffs) over(order by date1 asc rows between unbounded preceding and current row),0) as real_rank -- 计算累计日期差值,得到的是连续值情况下的序号
,rank1 - coalesce(sum(diffs) over(order by date1 asc rows between unbounded preceding and current row),0) as group_id -- 得到组别
from t2
)
,
t4 as (
select
group_id
,min(date1) as min_date1
,max(date1) as max_date1
,concat_ws('至',cast(min(date1) as varchar(10)),cast(max(date1) as varchar(10))) as date_range
from t3
group by
group_id
)
select
ARRAY_JOIN(ARRAY_AGG(date_range), '&') as date_range
from t4
order by
date_range asc
以上如果使用hiveSQL,date_diff函数要更换成datediff,ARRAY_AGG函数更换成 concat_ws(‘&’,collect_list())

















 3709
3709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









