







 本文详细剖析了HashMap的底层实现机制,包括其继承体系、存储结构、put操作流程、哈希碰撞处理、链化与红黑树转换策略,以及扩容原理。通过源码分析,深入理解HashMap如何保证高效的数据存取。
本文详细剖析了HashMap的底层实现机制,包括其继承体系、存储结构、put操作流程、哈希碰撞处理、链化与红黑树转换策略,以及扩容原理。通过源码分析,深入理解HashMap如何保证高效的数据存取。
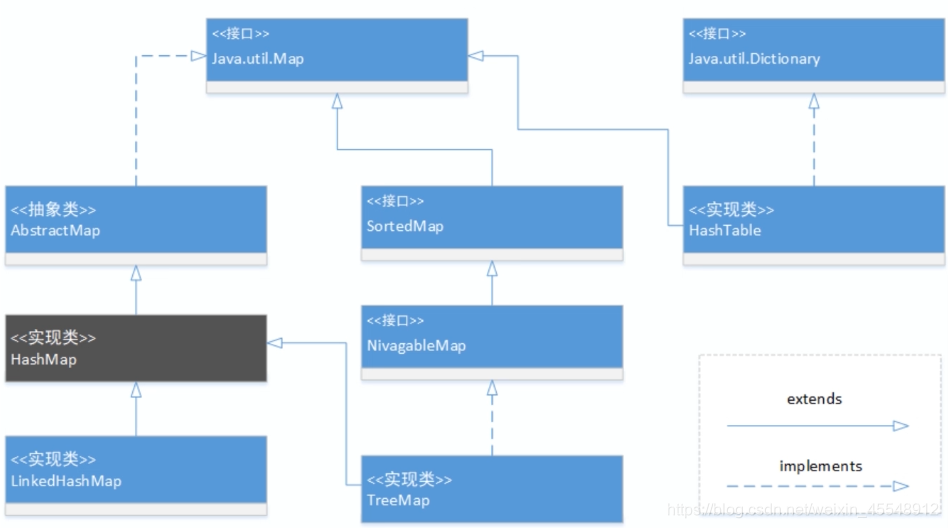
Map继承体系图:
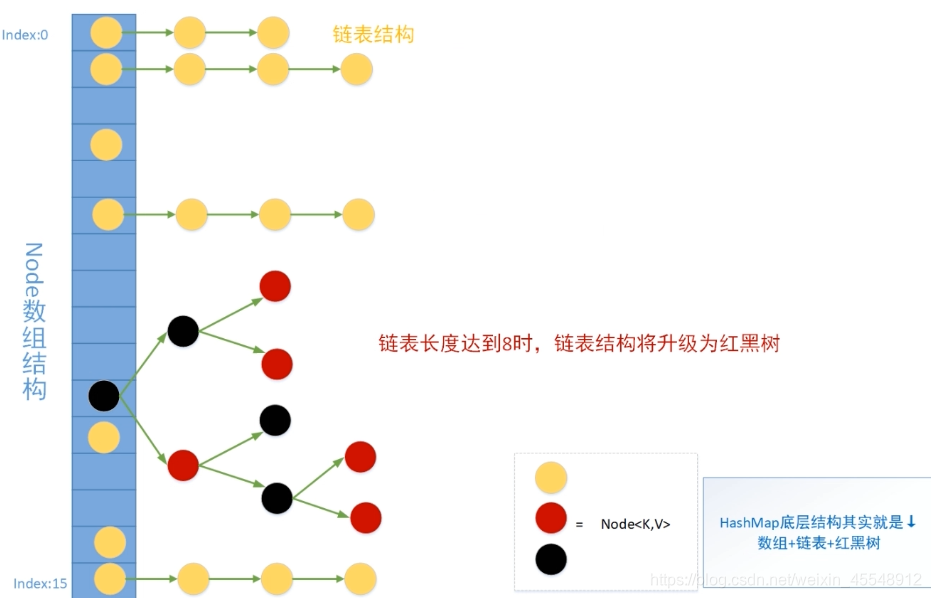
底层存储结构:
put数据原理分析:
map.put(k,v);
获取k字符串的Hash值
经过hash值扰动函数,使此hash值更散列
构造出Node对象
通过路由算法,找出Node应存放在数组的位置(路由寻址公式:(table.length-1)&node.hash)
哈希碰撞:
可能几个Hash值都能通过路由算法得到同一个值,这过程为哈希碰撞
什么是链化:
原本查找效率为O(1) 由于过于链化 时间复杂度变为O(N)
为什么提出红黑树:
防止链化过长,它是一个自平衡二叉查找树
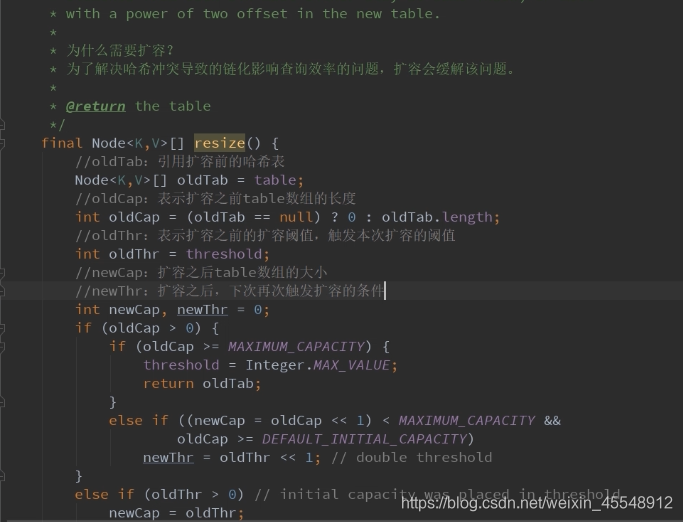
HashMap的扩容原理
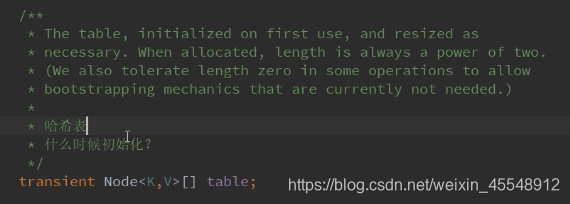
构造方法源码分析:
缺省table大小:
DEFAULT_INITIAL_CAPACITY =1<<4; // aka 16
table最大长度
MAXIMUM_CAPACITY=1<<30;
缺省的负载因子大小
DEFAULT_LOAD_FATORY=0.75f;
树华阈值
TREEIFY_THRESHOLD=8;
树降级称为链表的阈值
UNTREEIFY_THRESHOLD=6;
树华的另一个参数,当哈希表的所有元素个数超过64时,才会允许树华
MIN_TREEIFY_CAPACITY=64;



构造方法:
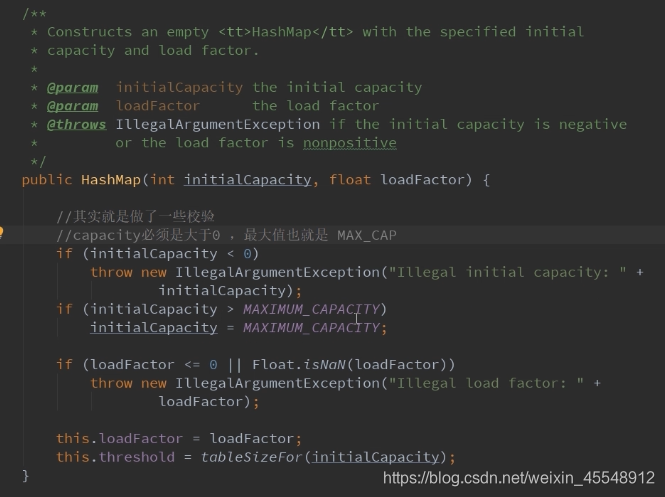
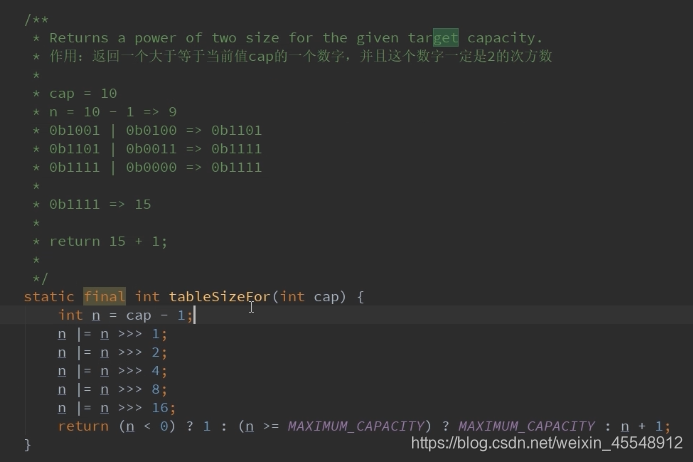
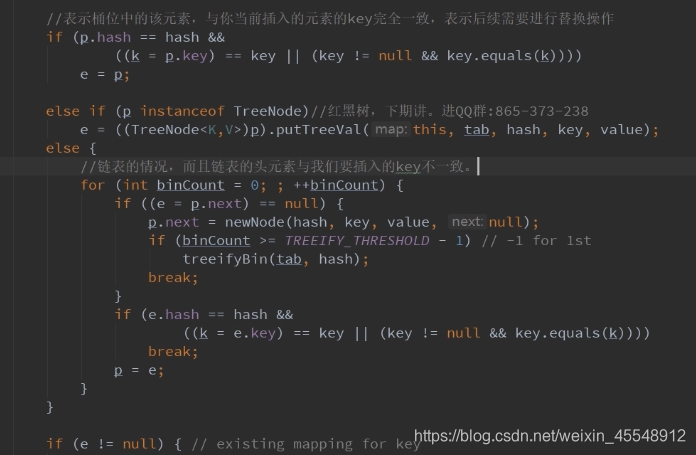
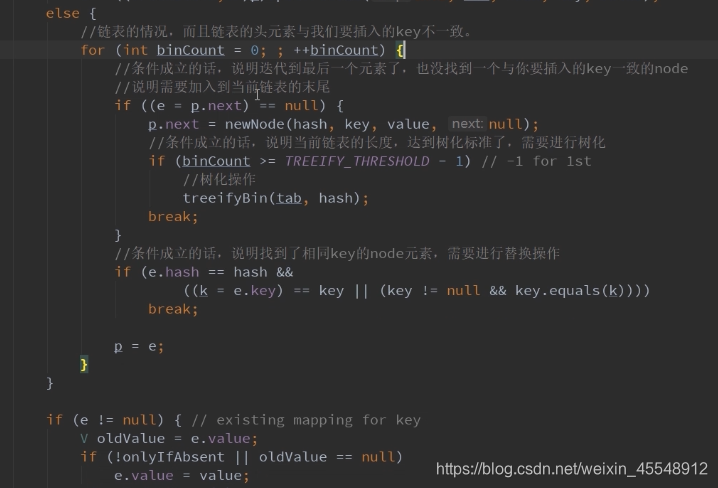
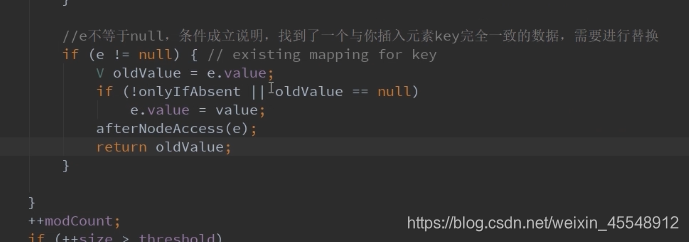
HashMap put方法分析 ==> putVal方法分析:

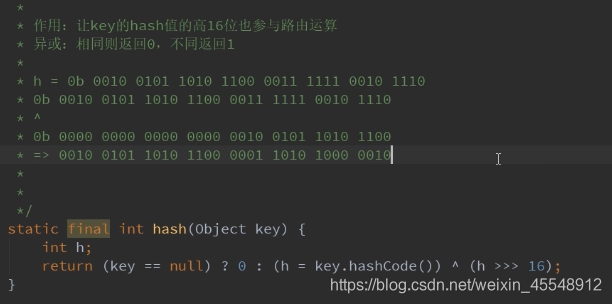
当你的length很短的时候,让你的hash值高16位也能进行运算(table.length-1)&node.hash
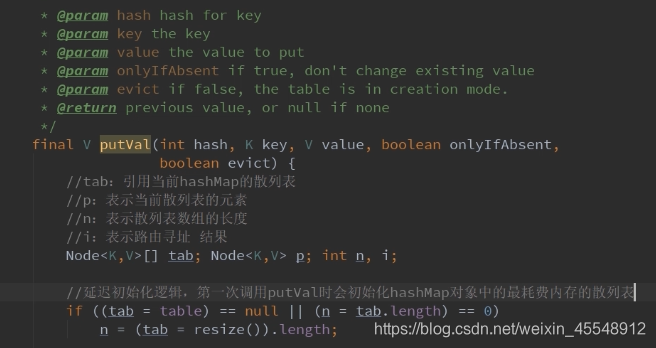

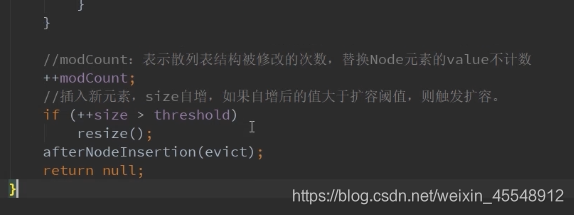
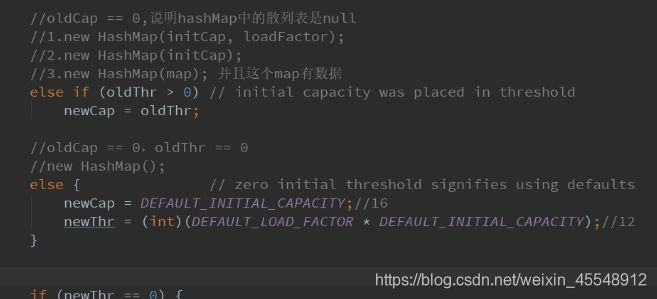
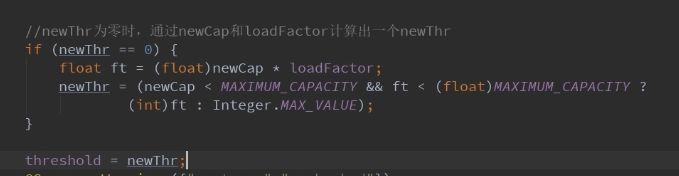
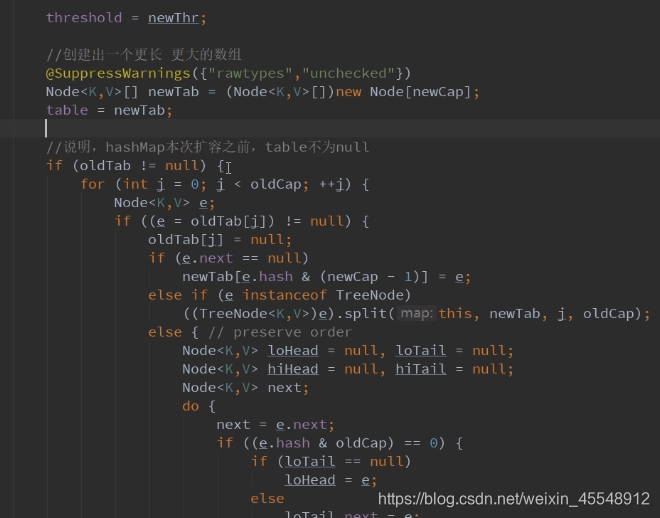
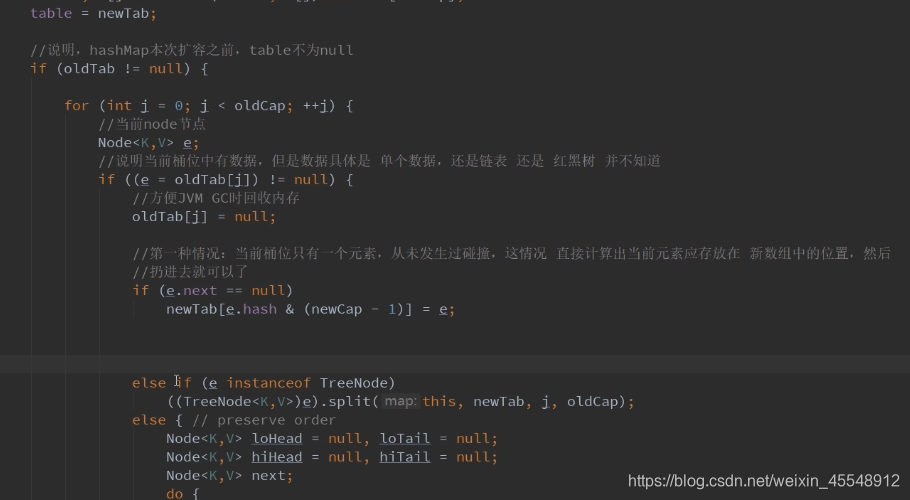
resize扩容方法源码分析:


















 3530
3530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









