







 本文介绍了Flink在Yarn集群上的两种运行方式:常驻式和独立式,并详细阐述了如何启动Flink集群、提交作业以及Flink与Yarn的交互过程。在Yarn上启动Flink集群可以通过指定内存资源,作业管理器和任务管理器的配置。提交作业后,可通过Web UI观察资源使用情况。
本文介绍了Flink在Yarn集群上的两种运行方式:常驻式和独立式,并详细阐述了如何启动Flink集群、提交作业以及Flink与Yarn的交互过程。在Yarn上启动Flink集群可以通过指定内存资源,作业管理器和任务管理器的配置。提交作业后,可通过Web UI观察资源使用情况。
Yarn模式
Yarn是一个分布式集群资源管理框架,在Yarn集群上可以部署运行各种分布式式应用程序。例如:Mapreduce,Spark。Yarn框架为这些分布式应用程序运行提供了可靠的支持。
因为在生产开发环境中很少使用Standalone模式,Flink On Yarn模式用的稍微多一点,今天我们就来讲讲Flink On Yarn
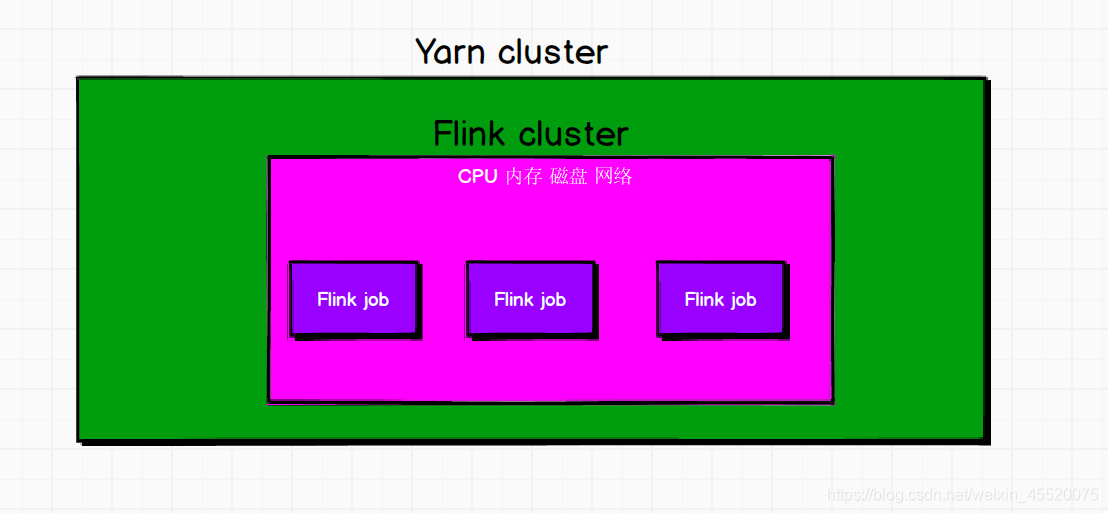
第一种方式
在Yarn集群中初始化一个Flink集群,该Flink集群占用着指定的资源,以后的Flink作业都会向这个Flink集群提交,这个Flink集群会常驻于Yarn集群中
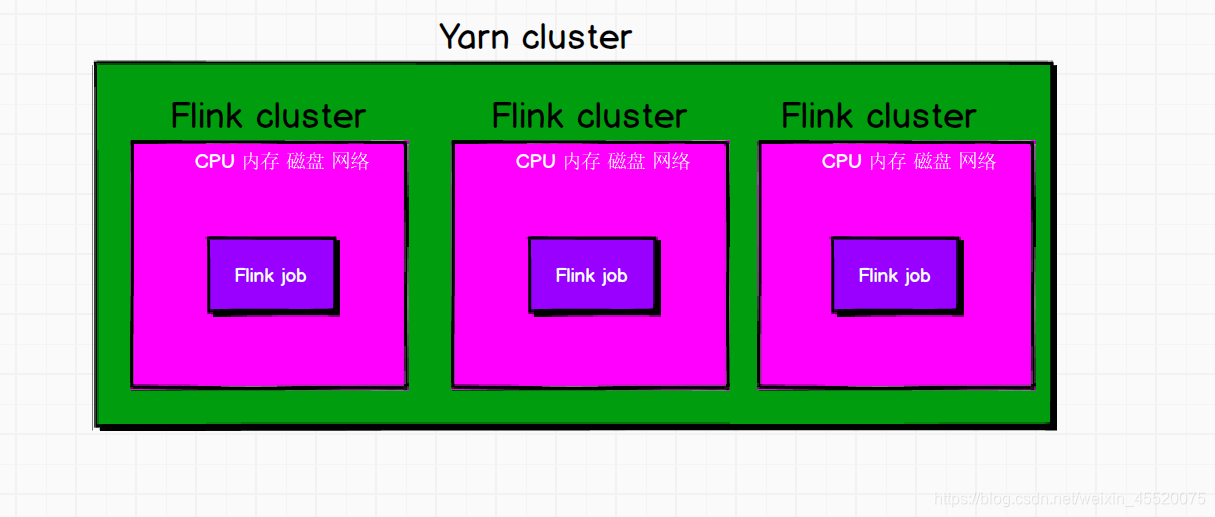
第二种方式
每次提交Flink作业的时候都会在Yarn集群上创建一个独立的Flink集群,与上面的不同的是,该提交的Flink作业之间相互独立不受影响,等到Filnk作业执行完毕之后就会释放资源
在Yarn集群中启动一个Flink集群
我们可以进入到Flink的bin目录下找到与之相关联的启动脚本
[luyan@hadoop114 bin]$ ./yarn-session.sh
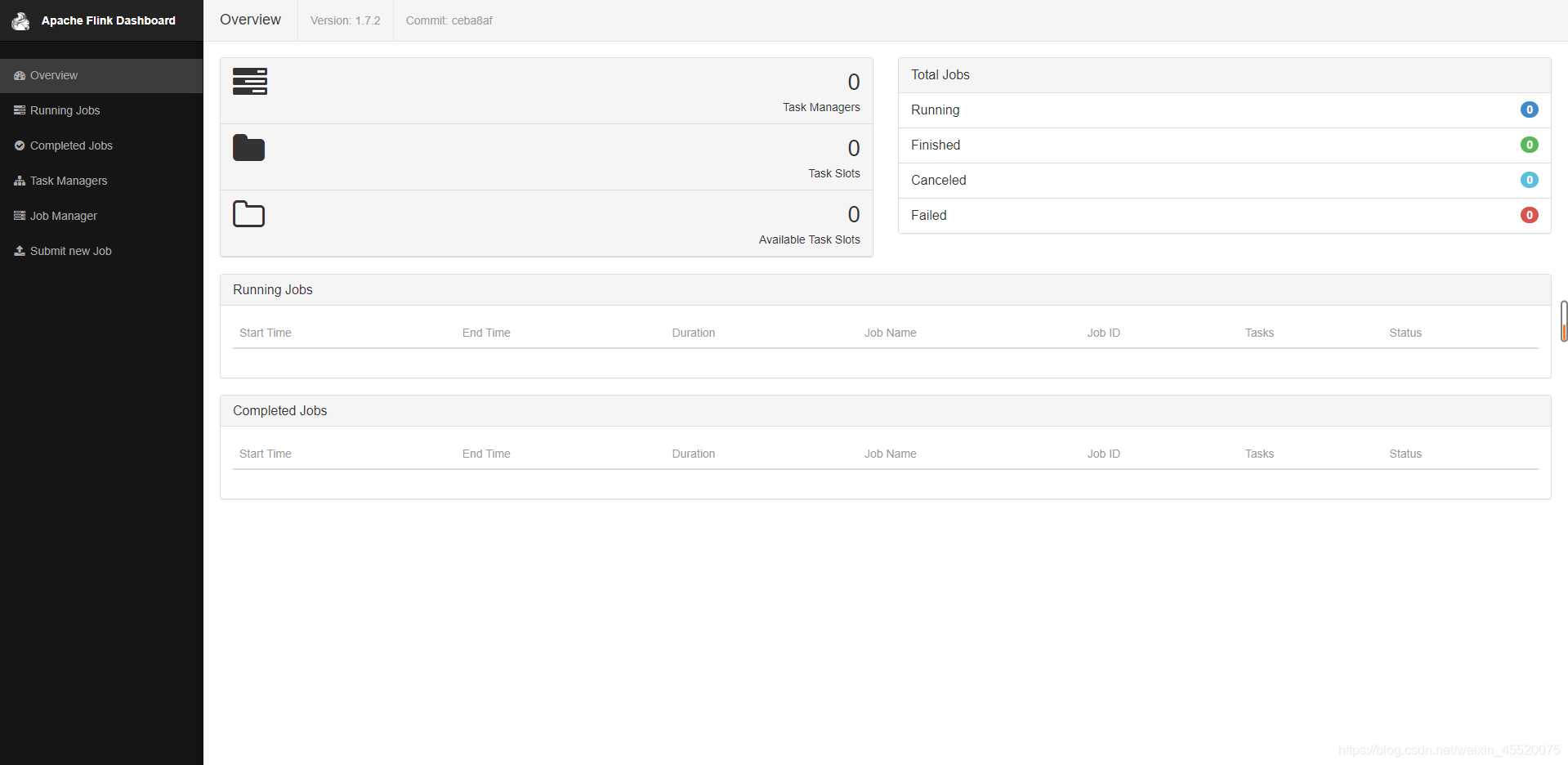
执行这个脚本之后,控制台上就会打印Flink集群的各种信息。最终要的一点我们会看到如下信息:
JobManager Web Interface: http://hadoop114:51775,这个表示在Yarn集群中初始化一个Flink集群的Web UI地址,如下图:
下面我们来介绍关于yarn-session的一些常用的命令
在调用yarn-session.sh脚本的时候,指定-h参数可以查看该脚本提供的可选参数:
[luyan@hadoop114 bin]$ ./yarn-session.sh -h
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value></ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









