







论文地址:https://arxiv.org/pdf/2011.07057.pdf
论文git:https://github.com/flyingdoog/PTDNet
介绍
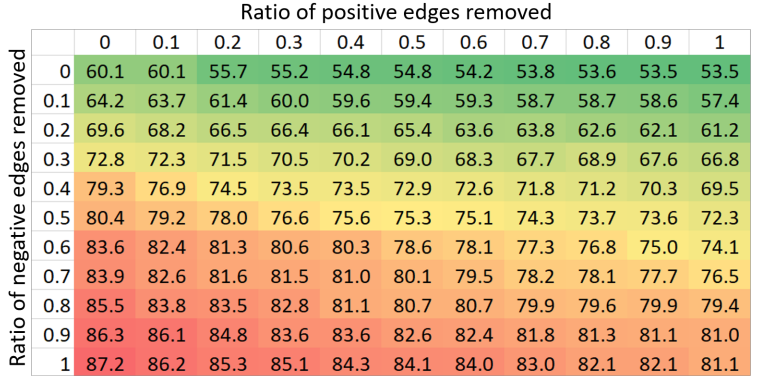
GNN 模型通常是根据拓扑结构,利用节点特征构建消息传递过程。然而,并不是所有的节点都需要参与消息传递过程,因此,需要一种选择的方法来刻画哪些边上的消息传递是真正需要的,也就是对边信息进行去噪。作者首先给出了一个GCN在Cora上的实验小例子,这个实验将相同标签的节点连接成正边,否则为负,对这些边进行随机移除,发现负边的移除会使得模型准确率上升:
这种针对拓扑结构进行修改确实也有很多讨论,比如GAT中有对边进行重新权重,或者比如DropEdge对图进行采样构造小子图避免过拟合。然而这些方法大多基于随机方法,对于下游任务很难说明为什么这些采样的信息更有帮助,其次,节点信息和图的拓扑结构应该同时去考虑什么样的信息应该被过滤。因此,作者采用参数化方法表示图拓扑结构,并对其进行去噪。
模型
模型整体结构如下,对于每层GNN传递做边的滤除,并且通过正则化参数直接约束滤除边的形式:
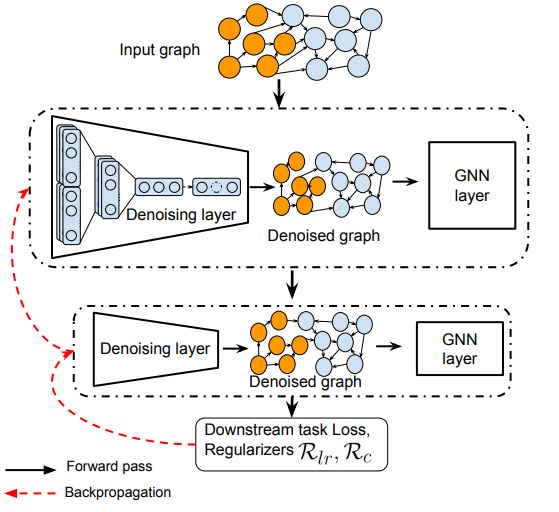
GNN在图上进行每层消息传递的是根据当前层的边信息进行运算的,由于模型希望对每一层都有一次过滤操作,那么在每一层上就可以有一层独立的Mask ,与原来第层的边有,这样就可以直接去除当前层带的噪音影响。这个时候发现如果直接求解这个仅由0和1构成的Mask是很苦难的一件事情,所以作者将其参数化更利于优化,比如映射到伯努利分布上,这时节点与之间的值用表示。这一步的Loss形式可以写成:
其对应梯度为:
。
那么接下来的问题就应该是怎么去解这些。作者采用的方法是参考Gumble-Softmax的方式进行重参数化的,设重参数化函数为,转化后的参数则为。Mask信息和这个重参数化的对应关系为,对应代码hard_concrete_sample函数,训练的时候与Gumble-Softmax相似会加入一些采样信息,写作:
,
这里是温度函数,会随迭代逐渐下降。测试的时候就直接一把sigmoid然后做归一化处理并且硬分割,具体操作是:
。
这里的和属于俩超参,扩大原本数值用的。总之,现在的问题就转化成了求:
。
这样就能够说明图网络最后的预测结果和这个拓扑结构可以直接相关。
接下来考虑是否能加入正则项。首先考虑这些mask的非零含量:
。
表示统计函数( cumulative distribution function, CDF),根据CDF可以得到对的微分结果:(PS: 对于所有分布的重参数采样后的结果来源于SCG[1]中的,且作者是给了一个很大的表可以用作参考,L指Logistic 函数。)

同样可以从SCG里拿结论,有:
。
而对的微分则可以看做一个复合函数的求解,即:
同样,带入CDF可得:
当采样的值等于0时,这个值可以写成:
因此可以说明这个正则化可以直接约束的值。另外,由于真实场景下,相同类别标签的节点更倾向于组成不同的簇,因此,从降噪的角度来看希望标签类别相同的节点能被边构成子图。由于邻接矩阵的rank的个数能够反应簇的个数,因此这个约束项用以减少rank,达到最终可以达到相同标签节点连接更紧密的效果。由于直接优化矩阵最小rank是一个NP-hard问题,所以作者采用了一种凸优化的方式来做这件事情,参考[2]。这一项写作:
表示这个邻接矩阵层的最大特征值。一般求解特征值的方法有两种,一种是SVD方法解,一种是用迭代式方式解,但SVD解得的特征值可能导致反传函数不稳定的情况,而迭代式可能输出不准确的近似值,并且当特征值接近零的时候更不准确了,会有较大波动,不易收敛。因此,基于以上分析,作者结合了这两种方法直接对mask进行分解,用SVD的特征向量初始化替代迭代法中的随机初始,如图所示:
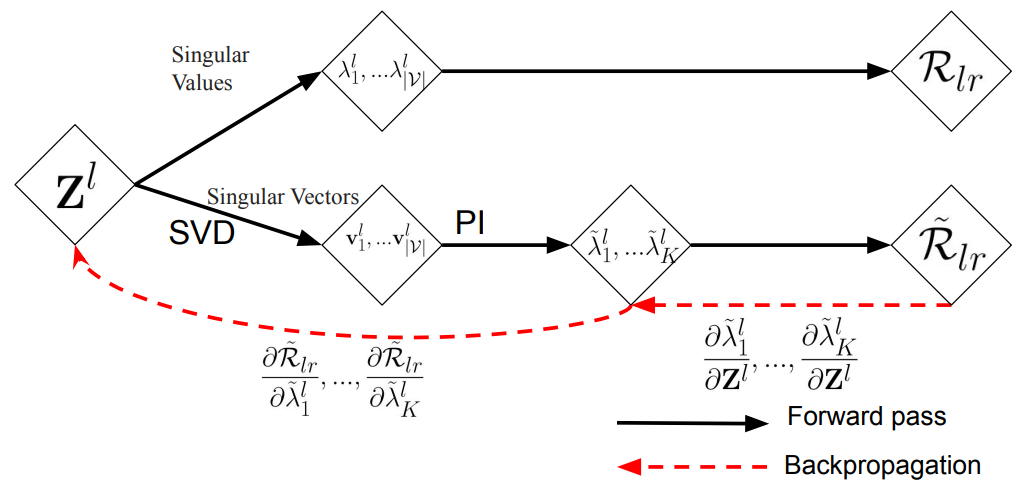
注意这里的迭代法只用来计算梯度,因此是分开的计算。这个梯度可以直接用于mask边是否存在的判别,写作:
实验
首先测试模型是否对常见的图网络模型有较好的提升作用:
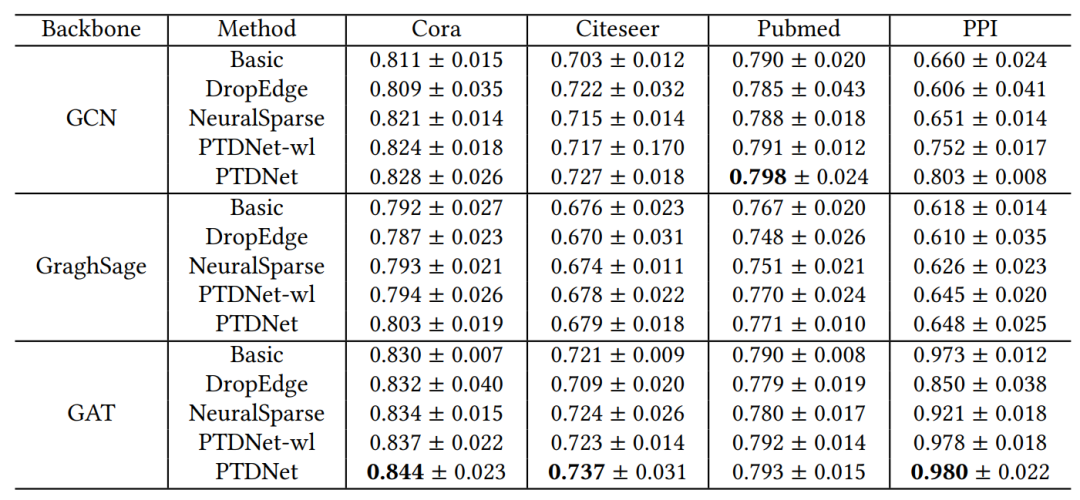
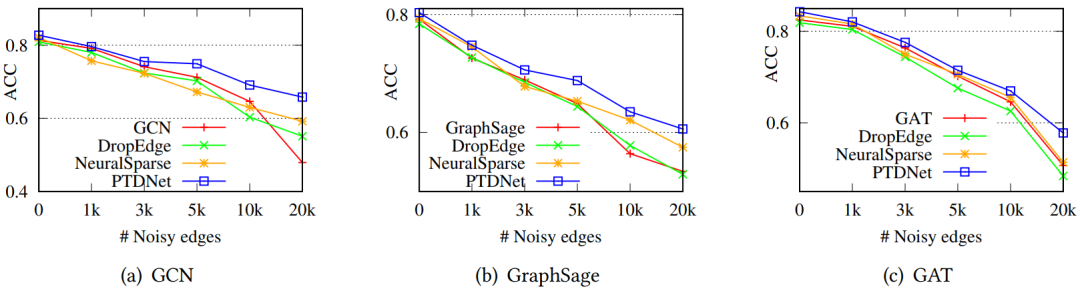
如图是几个常见数据集中的节点分类结果。之后测试这个模型是否能真的剔除噪音边,因此在Cora数据集中随机加入干扰边,可以发现随着随机边的增加,PTDNet模型改进的会更加明显:
相似的,作者也验证了PTDNet是否会对本身是否会滤除有重要贡献的边。作者构建了一个模拟数据,这个模拟数据里正边指同样标签的节点连接,否则负边。同时,作者考虑探讨了这种drop方法是否会对图本身拓扑结构信息,如度数分别产生影响:
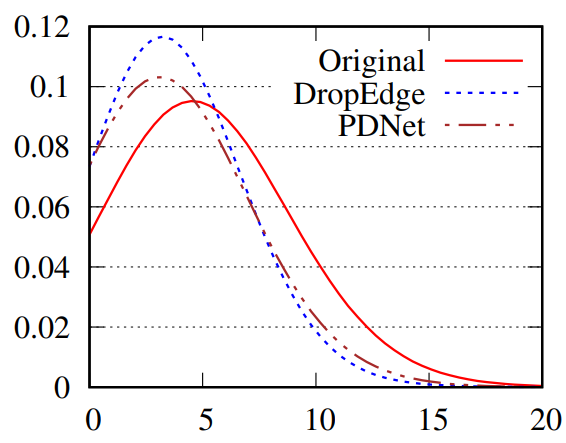
纵坐标表示占比,可以发现使用PTDNet之后的度分布曲线与原始分布比较接近,而DropEdge的形态改变比较明显(这个图有一点小typo,但是不影响阅读)。之后,可以看一下两个约束项对模型有多大影响:
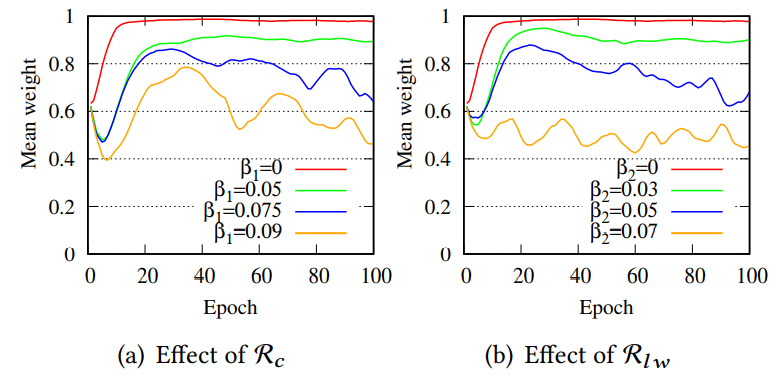
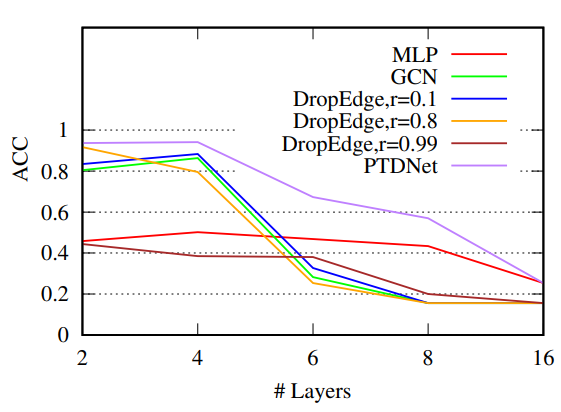
这里的Mean weight表示留下来的边占多大比例,可以发现这两种约束都可以有效滤除边的数目。PTFNet是可以延缓深度带来的over-smoothing影响的,实验如下:
[1]Chris J Maddison, Andriy Mnih, and Yee Whye Teh. 2016. The concrete distribution: A continuous relaxation of discrete random variables. arXiv preprint arXiv:1611.00712 (2016).
[2]Shmuel Friedland and Lek-Heng Lim. 2018. Nuclear norm of higher-order tensors. Math. Comp. 87, 311 (2018), 1255–1281.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









