






顶级会议NeurIPS组织了一个关于Datasets and Benchmarks Track,旨在通过大规模数据和评测来促进领域发展。
本次Track基本涵盖了所有领域的算法,包括图算法,计算机视觉CV,自然语言处理NLP,强化学习RL,语音处理,可解释性,架构搜索NAS,时间序列,因果推断等等。
https://openreview.net/group?id=NeurIPS.cc/2021/Track/Datasets_and_Benchmarks/Round1&utm_source=wechat_session&utm_medium=social&utm_oi=56371995213824
图学习 Graph Learning
A Large-Scale Database for Graph Representation Learning

本文提出了一个大规模图数据集MalNet,如下所示,其包括1.2M+张图,平均节点个数为17K,平均边个数为39K,图的类型也高达696。
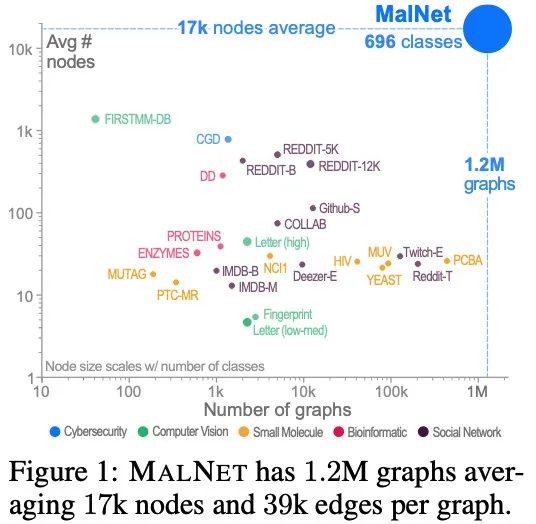
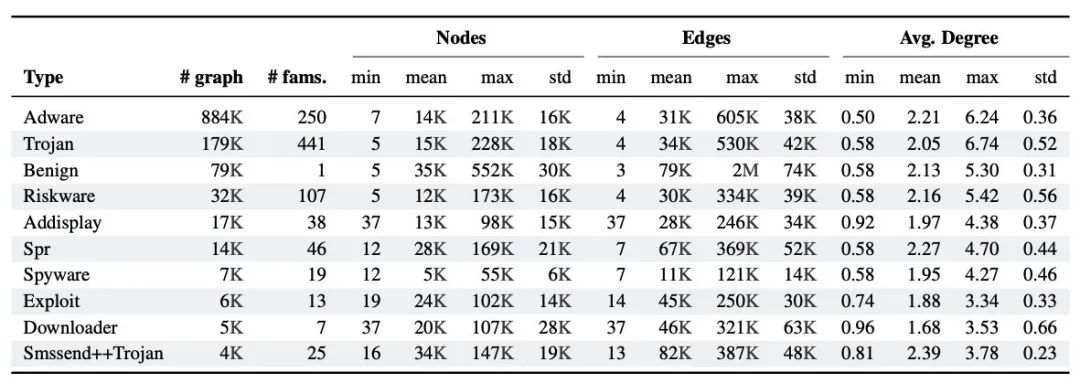
MalNet中最大的10张图的统计信息如下所示:
论文链接:
https://openreview.net/pdf?id=1xDTDk3XPW
数据集链接:
www.mal-net.org
An Empirical Study of Graph Contrastive Learning

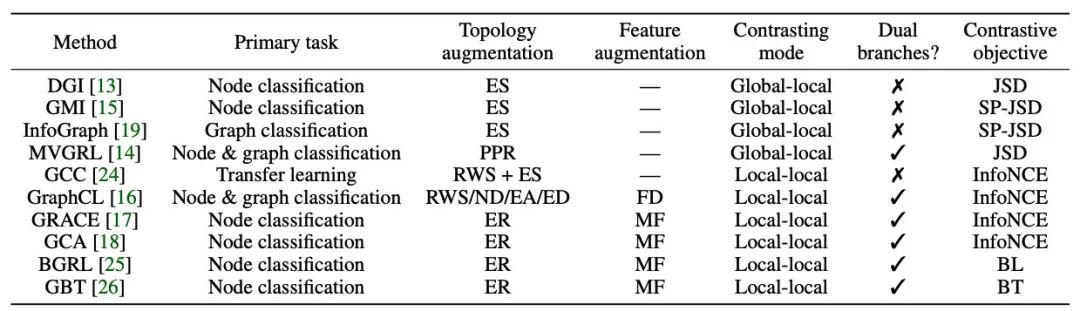
本文对现有的图对比学习技术进行了梳理总结,设计了一个相关的工具箱PyGCL,并在多个数据集上进行了统一测评。
链接:
https://openreview.net/pdf?id=fYxEnpY-__G
Graph Robustness Benchmark: Rethinking and Benchmarking Adversarial Robustness of Graph Neural Networks
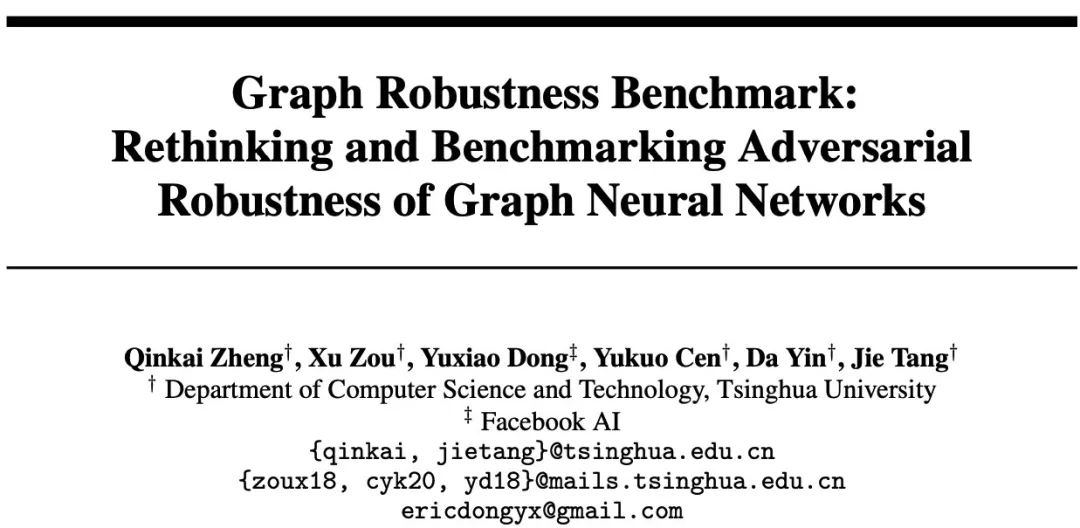
本文研究了图上的对抗鲁棒性问题,提供了相关的数据集,代码和leaderboard。入坑图对抗方向的同学不要错过呀~
下图梳理了关于GNN上的对抗攻击的一系列工作:
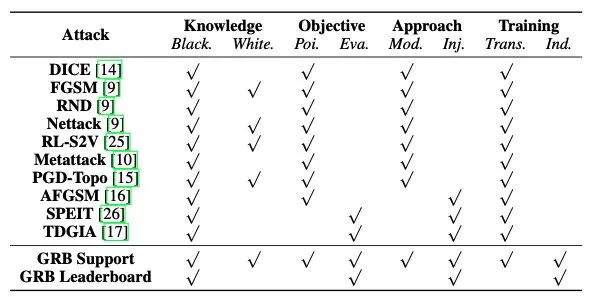
链接:
https://openreview.net/pdf?id=pBwQ82pYha
https://cogdl.ai/grb/home,
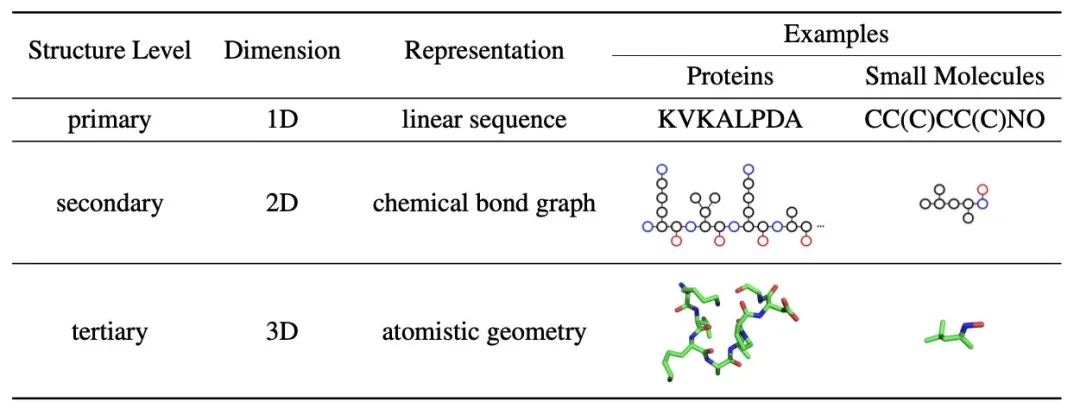
ATOM3D: Tasks On Molecules in Three Dimensions

用深度学习的方法如GNN来研究药物分子(如AI制药)在这两年非常火热。OGB竞赛的其中一个赛道就是预测分子图性质。分子图实际是3D结构的,尽管也可以以1D或者2D的形式表示,但是忽略一些空间位置信息。
自然语言处理 NLP
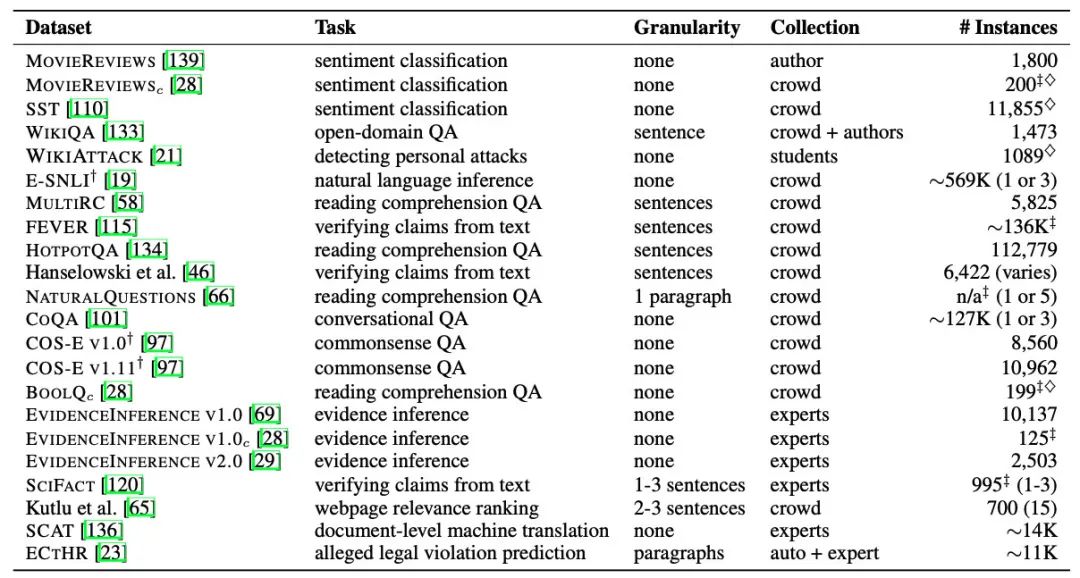
Teach Me to Explain: A Review of Datasets for Explainable Natural Language Processing

名字起的很好玩,教我解释。本文主要关注NLP模型的解释性,集中搜集了61个文本数据集,并分析了现有的解释性NLP的优缺点。
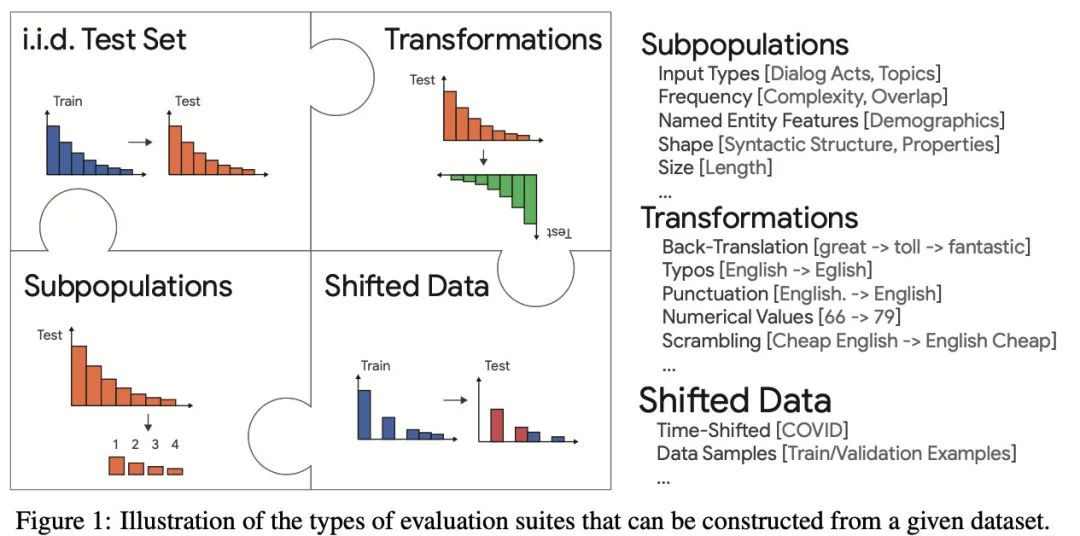
Automatic Construction of Evaluation Suites for Natural Language Generation Datasets
本文主要关注了NLG上的测评问题:从现有测评的缺点出发,引出了本文的GEM benchmark。下图给出了一个具体的例子。
强化学习 RL
NeoRL: A Near Real-World Benchmark for Offline Reinforcement Learning

RL算法经常在模拟环境下跑的很好,一到真实环境就跪,这种reality gap极大的限制了其应用。本文提出了一种近似真实世界的RL benchmark,包括数据集和任务,希望改善上述问题。
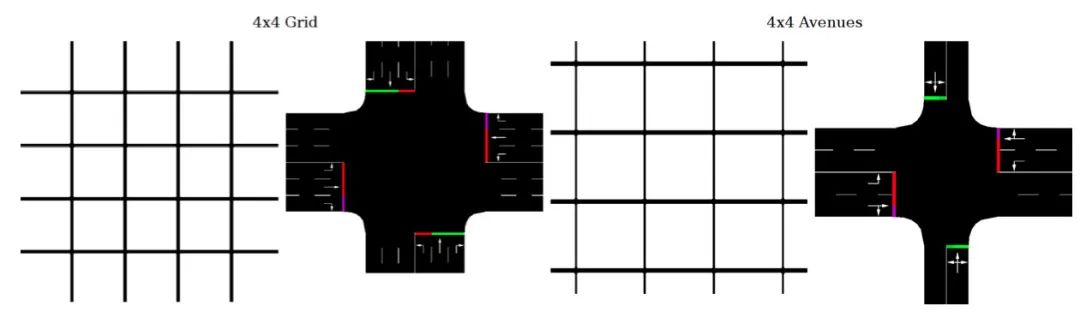
Reinforcement Learning Benchmarks for Traffic Signal Control

本文梳理了如何用强化学习RL来实现交通信号灯控制的benchmarks。


















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









