







 本文是关于numpy库中ndarray对象的学习笔记,涵盖了创建、数据类型转换、基本运算、索引和切片、布尔型索引、花式索引、转置、通用函数、条件逻辑运算、数学统计方法、排序、唯一化、文件输入输出、矩阵运算、伪随机数生成及广播规则等核心内容。
本文是关于numpy库中ndarray对象的学习笔记,涵盖了创建、数据类型转换、基本运算、索引和切片、布尔型索引、花式索引、转置、通用函数、条件逻辑运算、数学统计方法、排序、唯一化、文件输入输出、矩阵运算、伪随机数生成及广播规则等核心内容。
numpy学习笔记
数组ndarry的基本用法
创建ndarry
numpy中多维数组对象是ndarry
-
创建ndarray
最简单的方法是调用array函数
调用zero,ones函数(也可以调用empty函数,但数组中全是垃圾值)

至于调用的方法,可以在ide中寻找到函数原型,查看注释。 -
ndarry类中比较重要方法:
data.shape:数组的维度
data.dtype:数组数据类型 默认float64
data.ndim:数组的维度
例子
import numpy as np
# 生成一个1~1000的一维数组
data = np.array([[1, 2, 3], [4, 5, 6]])
print(data)
print(data.shape)
print(data.dtype)
结果是:
[[1 2 3]
[4 5 6]]
(2, 3)
int64
ndarray的数据类型
如果创建数组,默认float64。
numpy所支持的数据类型:
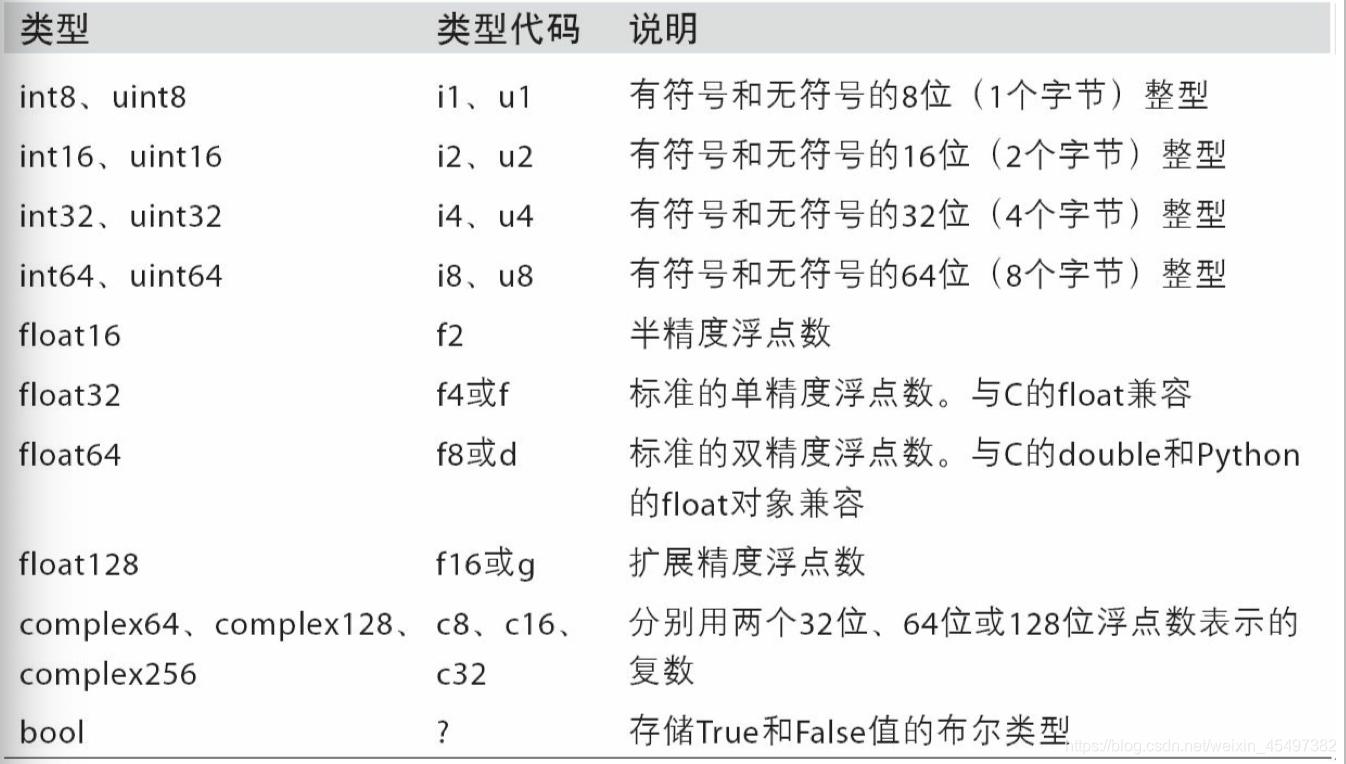
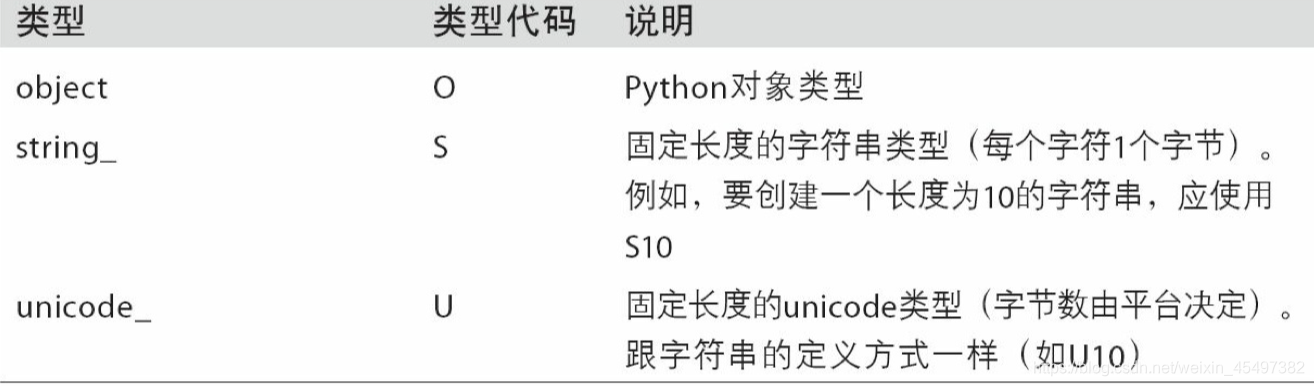
astype可以将数组的数据类型进行转化:
import numpy as np
# 不推荐由高往低转化
data = np.full([2, 3], 10, np.float64)
print(data.dtype)
# astype并不会修改原来数组的数据类型,需要承接结果
data = data.astype(np.int32)
print(data.dtype)
结果为:
float64
int32
astype也可以将改变数组中元素的数据类型,比如数组中的元素都是字符串,可以调用该函数,将其转化为浮点数。
data = np.array(['2.33', '0.56'])
print(data)
print(data.dtype)
data = data.astype(np.float64)
print(data)
print(data.dtype)
结果:
['2.33' '0.56']
<U4
[2.33 0.56]
float64
数组ndarry运算
加减乘除均支持,比如两个矩阵A、B,对其使用加法运算,就是A和B对应的元素相加,A的第一列第一行,和B的第一列第一行元素相加。A第二列第二行,B第二列第二行相加。(当A和B的大小形状相同时,如果不相同时的运算为广播)
数组ndarry的基本索引和切片
一维数组
一维数组与python的相同,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反 映到源数组上。
切片:arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
arr[5:8]
会得到[5, 6, 7],其中 : 的作用跟5~8中的 ~ 传达的意思接近,不过8是取不到的。
如果arr[5:8] = 12 也会触发广播,因为形状不对,5:8有3个元素,而12只是一个元素。
如果想的到一个数组or数组切片的复制需要使用 copy函数
二维数组
二维数组所使用的索引可以是:
[1][2] 或者 [1, 2],所代表的意思都是访问数组的第一行,第二列(包含第0行,第0列)的元素。
在多维数组中,如果省略了后面的索引,则返回对象会是一个维度低一点的 ndarray(它含有高一级维度上的所有数据)
二维数组所使用的切片:
一般而言,我们更偏向与使用[a, b] 而不是[a][b]。
arr[1, :2]表示的是:第一行的第0列,第1列(包含第0行,第0列)
那么arr[:, 1]以及arr[1:, 0]是什么意思?
arr[:, 1]:所有行,第1列的元素
arr[1:, 0]:除第0行外所有行,第0列的元素
data = np.array([[1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









