




目录
代码讲解
在网络爬虫中,我们经常需要从网页中提取有用的信息,其中一种常见的方式是使用正则表达式。本文将介绍如何使用 Python 的 re 模块和正则表达式来提取豆瓣电影 Top250 页面的电影信息。 首先,我们需要发送请求获取网页内容,并使用 decode 方法将网页内容的字节流转化为字符串。这个过程与 BeautifulSoup 版本是一样的,主要是为了方便后续处理。具体代码如下:
import requests
import re
# 设置请求头
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36' }
# 发送请求,获取网页内容
url = 'https://movie.douban.com/top250'
response = requests.get(url, headers=headers)
if response.status_code == 200:
print('网页内容获取成功。')
else:
print(f'网页内容获取失败。状态码:{response.status_code}')
html = response.content.decode('utf-8')接下来,我们需要构造一个正则表达式的模式字符串,来匹配 HTML 代码中的电影信息。这里我们使用了 re 模块的 compile 函数来编译正则表达式。在模式字符串中,我们使用了 .*? 来匹配电影信息前后的任意字符,使用 (.*?) 来分组提取电影名称、电影信息中的上映地点和时长、评分和星级等信息。其中,re.S 表示使用单行模式,可以匹配多行字符串。具体代码如下:
# 使用正则表达式提取电影信息
pattern = re.compile(r'<li>.*?<span class="title">(.*?)</span>.*?<p class="">(.*?)</p>.*?<span class="rating_num" property="v:average">(.*?)</span>.*?<span class="inq">(.*?)</span>.*?</li>', re.S)
items = re.findall(pattern, html)然后,我们使用 re 模块的 findall 函数来在 HTML 代码中查找所有符合模式字符串的电影信息,并将结果保存到 items 列表中。如果没有找到符合条件的电影信息,则 items 列表为空。 接下来,我们遍历 items 列表,提取电影名称、上映地点、时长、评分、星级等信息,并将其写入 result.txt 文件中。如果 items 列表为空,则输出没有获取到电影信息的提示。具体代码如下:
if items:
print(f'共获取到 {len(items)} 条电影信息。')
with open('result.txt', 'w', encoding='utf-8') as f:
for item in items:
title = item[0]
info = item[1].split('/')
region = info[0].strip()
length = info[1].strip() if len(info) > 1 else ''
star = item[2]
quote = item[3]
f.write(f'电影名称:{title}\n')
f.write(f'上映地点:{region}\n')
f.write(f'时长:{length}\n')
f.write(f'评分:{star}\n')
f.write(f'星级:{quote}\n\n')
else:
print('没有获取到电影信息。')需要注意的是,使用正则表达式提取 HTML 代码中的信息,可能会受到 HTML 代码的变化而出现问题。因此,如果您需要爬取的网站或页面具有一定的复杂度,建议使用 BeautifulSoup 等 HTML 解析库来提取信息,这样更为稳定和可靠。 至此,使用正则表达式提取电影信息的代码已经完成。您可以根据自己的需求修改相关代码,并将其应用于其他网页信息的提取。 希望本文能够对您有所帮助!
总代码
import requests
import re
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 发送请求,获取网页内容
url = 'https://movie.douban.com/top250'
response = requests.get(url, headers=headers)
if response.status_code == 200:
print('网页内容获取成功。')
else:
print(f'网页内容获取失败。状态码:{response.status_code}')
html = response.content.decode('utf-8')
# 使用正则表达式提取电影信息
pattern = re.compile(r'<li>.*?<span class="title">(.*?)</span>.*?<p class="">(.*?)</p>.*?<span class="rating_num" property="v:average">(.*?)</span>.*?<span class="inq">(.*?)</span>.*?</li>', re.S)
items = re.findall(pattern, html)
if items:
print(f'共获取到 {len(items)} 条电影信息。')
with open('result.txt', 'w', encoding='utf-8') as f:
for item in items:
title = item[0]
info = item[1].split('/')
region = info[0].strip()
length = info[1].strip() if len(info) > 1 else ''
star = item[2]
quote = item[3]
f.write(f'电影名称:{title}\n')
f.write(f'上映地点:{region}\n')
f.write(f'时长:{length}\n')
f.write(f'评分:{star}\n')
f.write(f'星级:{quote}\n\n')
else:
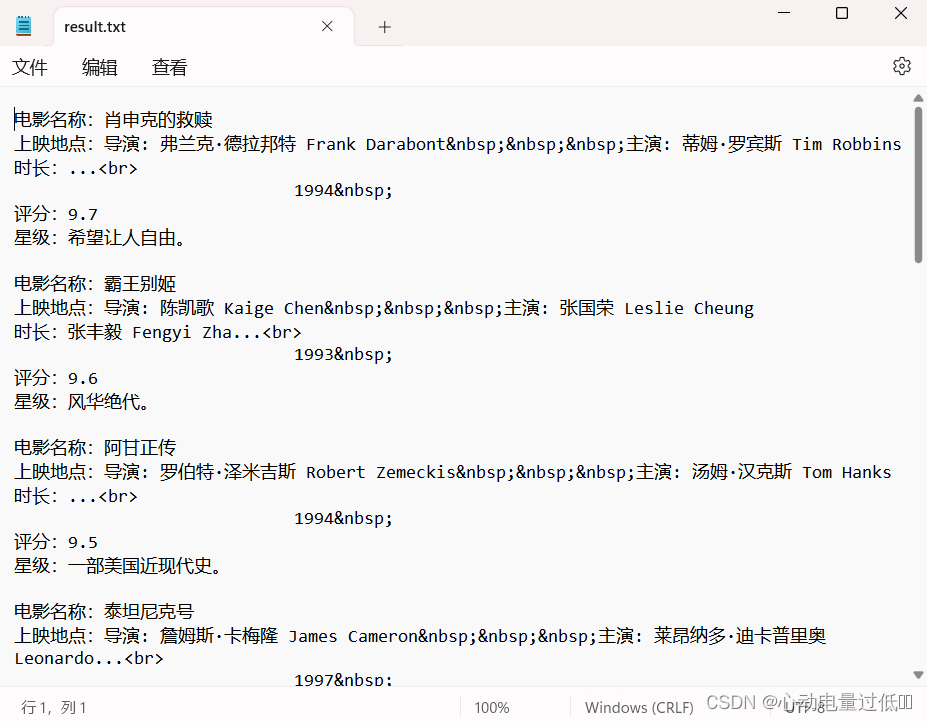
print('没有获取到电影信息。')效果展示


















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











