




文章目录
摘要
本文提出了一种新的新闻推荐深度强化学习框架。由于新闻特性和用户偏好的动态性,在线个性化新闻推荐是一个极具挑战性的问题。虽然有人提出了一些在线推荐模型来解决新闻推荐的动态性,但这些方法存在三个主要问题。
- 首先,他们只尝试模拟当前的奖励(例如,点击率)。
- 其次,很少有研究考虑使用点击/不点击标签以外的用户反馈(例如,用户返回的频率)来帮助改进推荐。
- 这些方法倾向于不断向用户推荐类似的新闻,这可能会让用户感到无聊。
本文创新之处:
- 提出了一个基于深度Q-Learning的推荐框架,该框架可以明确地建模未来的奖励。
- 进一步考虑用户返回模式作为点击/不点击标签的补充,以获取更多的用户反馈信息。
- 此外,还加入了有效的探索策略,为用户寻找新的有吸引力的新闻。
一、Introduction
1、引入原因
原有的推荐算法有以下几个问题解决不了:
问题一:
新闻推荐的动态变化很难处理。新闻推荐的动态变化主要表现在两个方面。
- 新闻很快就会过时。在我们的数据集中,一条新闻发布到最后一次点击之间的平均时间是4.1小时,推荐候选池变化是非常迅速的。
- 用户对不同新闻的兴趣可能会随着时间的推移而变化。因此,有必要定期更新模型。虽然有一些网上的推荐方法,可以捕捉新闻的动态变化特性和用户偏好模型通过在线更新,他们只是试图优化当前的奖励(例如,点击率),因此忽略当前的建议可能会带来什么影响未来。
下面举一个例子来说明考虑未来必要性的例子。
当用户Mike请求新闻时,推荐代理会预测他有几乎相同的概率点击两条新闻:一条是关于雷雨警报的,另一条是关于篮球运动员科比·布莱恩特的。但是,根据Mike的阅读偏好,新闻的特点,以及其他用户的阅读模式,我们的代理推测,Mike在阅读了关于雷雨的新闻后,将不再需要阅读关于这个alert的新闻,但是在阅读了关于科比的新闻后,他可能会阅读更多关于篮球的信息。这表明,推荐后一条消息会带来更大的未来回报。因此,从长远来看,考虑未来的奖励将有助于提高推荐性能。
下图就是用户兴趣的变化情况。
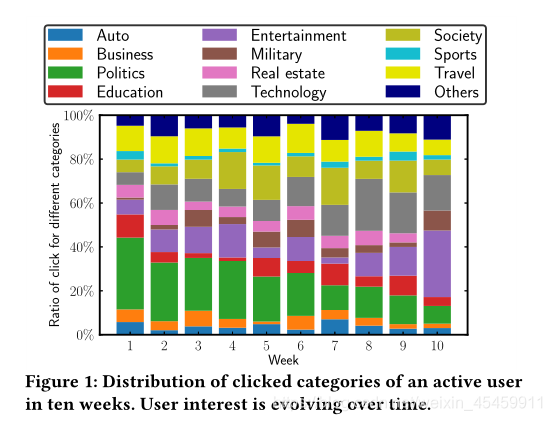
问题二:
当前的推荐算法通常只考虑用户的点击/未点击,或者 用户的评分作为反馈。然而,用户隔多久会再次使用服务也能在一定程度上反映用户对推荐结果的满意度。
问题三:
模型很容易推荐相似的内容给用户。之前有两种办法来缓解这个问题:
- ϵ \epsilon ϵ-greedy策略,但它会推给用户完全不相关的内容
- UCB,但是它的响应时间很长,需要重复点击一个item很多次才能给出一个准确的reward。
本文的解决方法是
- 引入DQN框架来更好的学习新闻动态特征和用户偏好,因为DQN能同时考虑current reward和future reward。MAB-based方法不能清晰地给出future reward,MDP-based方法不适用于大规模数据。
- 引入用户返回APP的情况转化为用户活跃度,作为用户反馈信息。可以在任意时刻计算用户活跃度。
- exploration时采用Dueling Bandit Gradient Descent(DBGD)方法来挑选当前推荐环境下的候选items,方法是在当前推荐器的邻域内随机选择候选项。这种探索策略可以避免推荐完全不相关的项目,从而保持更好的推荐准确性。
2、结构框架
深度强化推荐系统如下图所示。在系统中,用户池和新闻池构成了环境,推荐算法扮演代理的角色。状态定义为用户的特征表示,动作定义为新闻的特征表示。每当用户请求新闻时,一个状态表示(即和一组动作表示(即,新闻考生的特征)被传递给代理。代理将选择最佳操作(即,向用户推荐新闻列表),获取用户反馈作为奖励。具体来说,奖励是由点击标签和用户活跃度评估组成的。所有这些推荐和反馈日志都将存储在代理的内存中。每隔一小时,代理将使用内存中的日志更新其推荐算法。
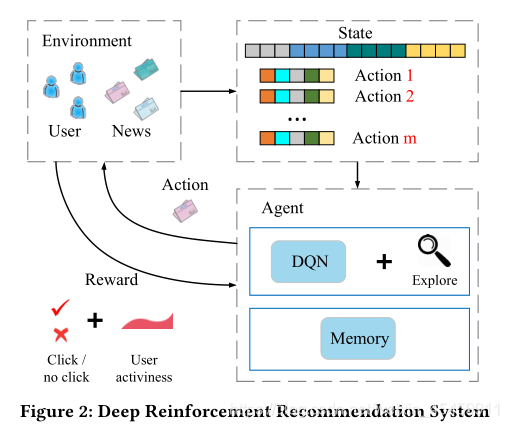
简单概括一下:
用户点击情况就是实时reward,用户活跃度(用户在一次推荐后返回应用程序的频率)就是future reward,state表示的用户特征以及用户行为特征,action是新闻候选池的特征,这样就构成了强化学习的基本框架。
二、相关工作
1、新闻推荐算法
推荐系统因其与产品利润的直接关系而被广泛研究。近年来,随着网络内容的爆炸式增长,推荐的一种特殊应用——网络个性化新闻推荐受到了越来越多的关注。传统的新闻推荐方法可以分为三类。
基于内容的方法将维护新闻词频特征(例如TF-IDF)和用户概况(基于历史新闻)。然后,推荐人会选择更接近用户资料的新闻。
相比之下,协同过滤方法通常利用当前用户或相似用户的过去评级,或结合这两种进行评级预测。为了结合前两组方法的优点,进一步提出混合方法来改进用户配置文件建模。
近年来,深度学习模型[1,2,3]作为对以往方法的扩展和集成,由于能够对复杂的用户-项目关系进行建模,其性能远远优于前三种模型。
与建模用户与物品之间复杂交互的工作不同,我们的算法侧重于处理在线新闻推荐的动态特性,以及对未来奖励的建模。然而,这些特征构造和用户-项目建模技术可以很容易地集成到我们的方法中。
2、推荐中的强化学习
主要分为两类
- 基于Contextual Multi-Armed Bandit models
- 基于Markov Decision Process models.
3、问题定义
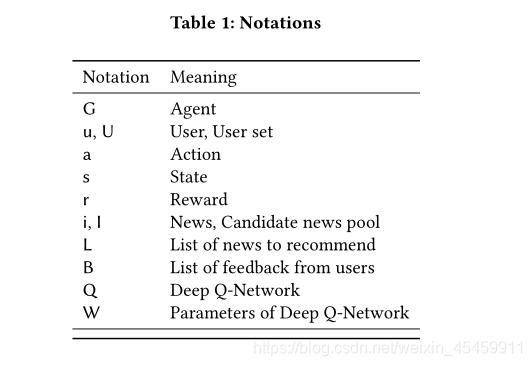
我们将我们的问题定义为:当用户u在时间t向推荐代理G发送一个新闻请求时,给定一个新闻候选集I,我们的算法将为该用户选择一个top-k合适的新闻列表L。本文使用的表示法如表1所示。
三、实现原理
1、模型框架
如下图所示,我们的模型由离线部分和在线部分组成。
离线部分,模型采用了用户记录日志的新闻级别和用户级别的4类特征作为输入,计算DQN的reward。该网络使用离线用户-新闻单击日志进行训练。
在线学习部分,我们的推荐代理G将与用户进行交互,并按照以下四步更新网络:
- PUSH:t1时刻用户u发出请求,agent利用u和新闻候选池作为输入,生成top k个推荐
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3034
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









